 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapturing Knowledge of Emerging Entities From Extended Search Snippets
Mar 17, 2021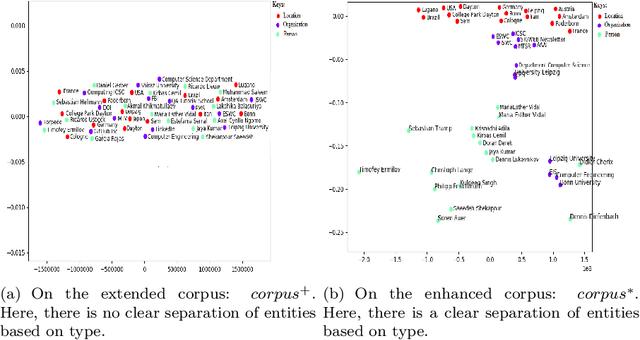

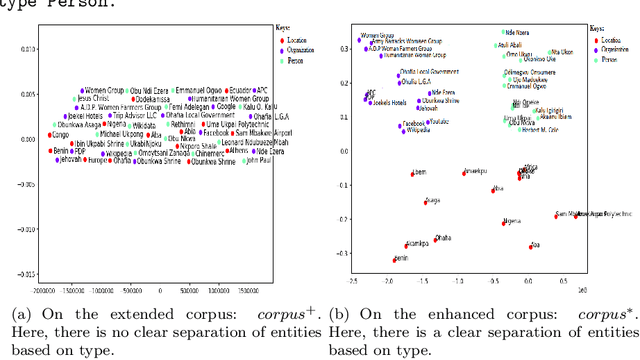
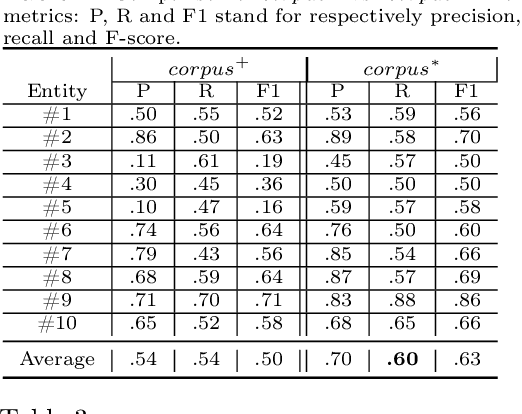
Google and other search engines feature the entity search by representing a knowledge card summarizing related facts about the user-supplied entity. However, the knowledge card is limited to certain entities that have a Wiki page or an entry in encyclopedias such as Freebase. The current encyclopedias are limited to highly popular entities, which are far fewer compared with the emerging entities. Despite the availability of knowledge about the emerging entities on the search results, yet there are no approaches to capture, abstract, summerize, fuse, and validate fragmented pieces of knowledge about them. Thus, in this paper, we develop approaches to capture two types of knowledge about the emerging entities from a corpus extended from top-n search snippets of a given emerging entity. The first kind of knowledge identifies the role(s) of the emerging entity as, e.g., who is s/he? The second kind captures the entities closely associated with the emerging entity. As the testbed, we considered a collection of 20 emerging entities and 20 popular entities as the ground truth. Our approach is an unsupervised approach based on text analysis and entity embeddings. Our experimental studies show promising results as the accuracy of more than $87\%$ for recognizing entities and $75\%$ for ranking them. Besides $87\%$ of the entailed types were recognizable. Our testbed and source code is available on Github https://github.com/sunnyUD/research_source_code.
A Road-map Towards Explainable Question Answering A Solution for Information Pollution
Jul 04, 2019

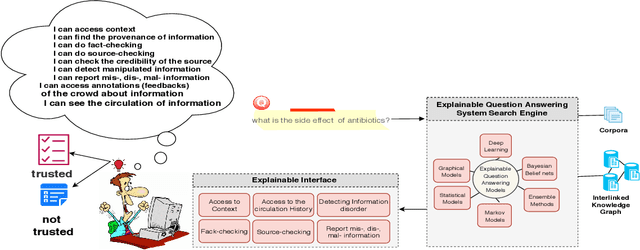

The increasing rate of information pollution on the Web requires novel solutions to tackle that. Question Answering (QA) interfaces are simplified and user-friendly interfaces to access information on the Web. However, similar to other AI applications, they are black boxes which do not manifest the details of the learning or reasoning steps for augmenting an answer. The Explainable Question Answering (XQA) system can alleviate the pain of information pollution where it provides transparency to the underlying computational model and exposes an interface enabling the end-user to access and validate provenance, validity, context, circulation, interpretation, and feedbacks of information. This position paper sheds light on the core concepts, expectations, and challenges in favor of the following questions (i) What is an XQA system?, (ii) Why do we need XQA?, (iii) When do we need XQA? (iv) How to represent the explanations? (iv) How to evaluate XQA systems?
CEVO: Comprehensive EVent Ontology Enhancing Cognitive Annotation
Oct 03, 2018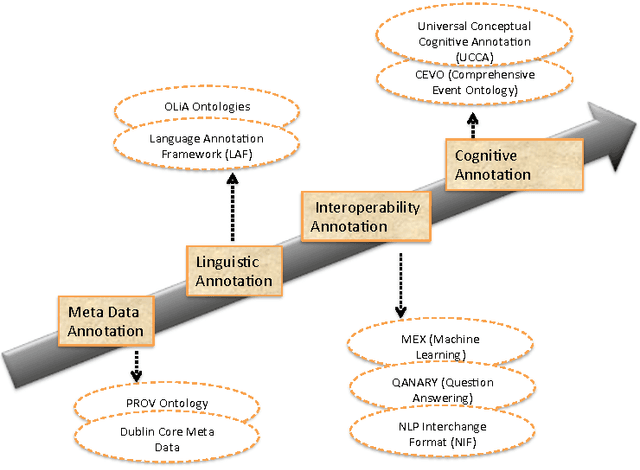
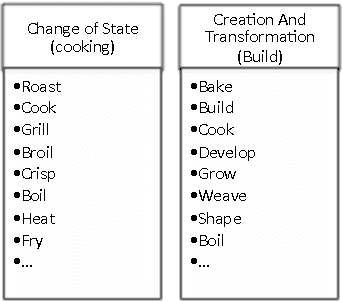
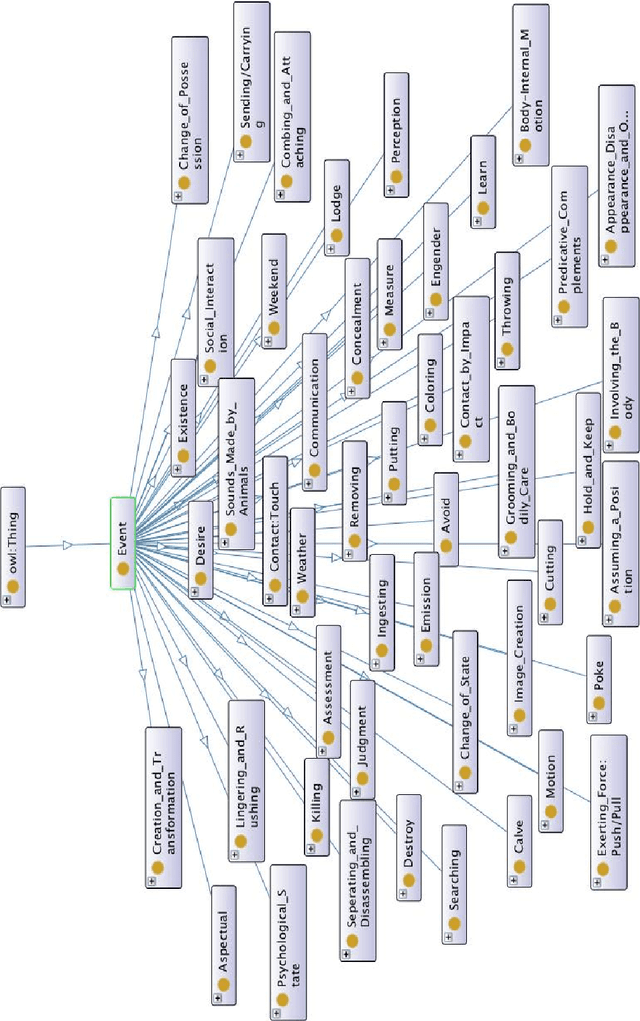
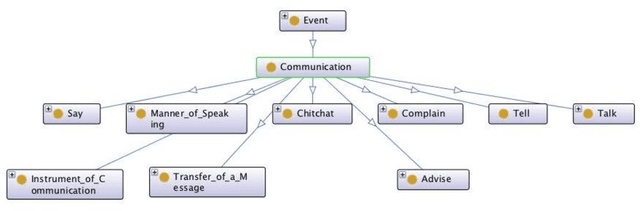
While the general analysis of named entities has received substantial research attention on unstructured as well as structured data, the analysis of relations among named entities has received limited focus. In fact, a review of the literature revealed a deficiency in research on the abstract conceptualization required to organize relations. We believe that such an abstract conceptualization can benefit various communities and applications such as natural language processing, information extraction, machine learning, and ontology engineering. In this paper, we present Comprehensive EVent Ontology (CEVO), built on Levin's conceptual hierarchy of English verbs that categorizes verbs with shared meaning, and syntactic behavior. We present the fundamental concepts and requirements for this ontology. Furthermore, we present three use cases employing the CEVO ontology on annotation tasks: (i) annotating relations in plain text, (ii) annotating ontological properties, and (iii) linking textual relations to ontological properties. These use-cases demonstrate the benefits of using CEVO for annotation: (i) annotating English verbs from an abstract conceptualization, (ii) playing the role of an upper ontology for organizing ontological properties, and (iii) facilitating the annotation of text relations using any underlying vocabulary. This resource is available at https://shekarpour.github.io/cevo.io/ using https://w3id.org/cevo namespace.
Concept2vec: Metrics for Evaluating Quality of Embeddings for Ontological Concepts
Jul 26, 2018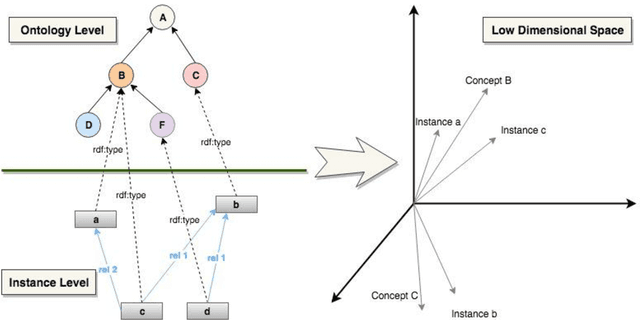
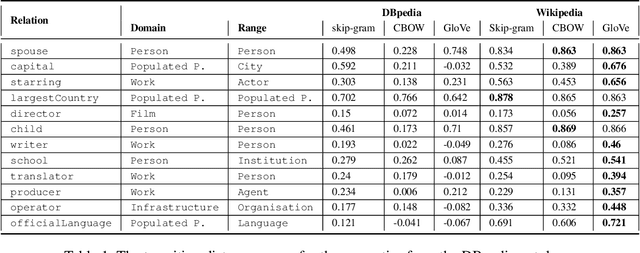
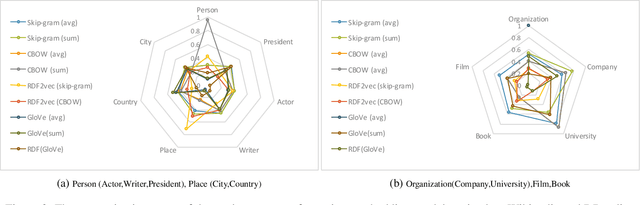
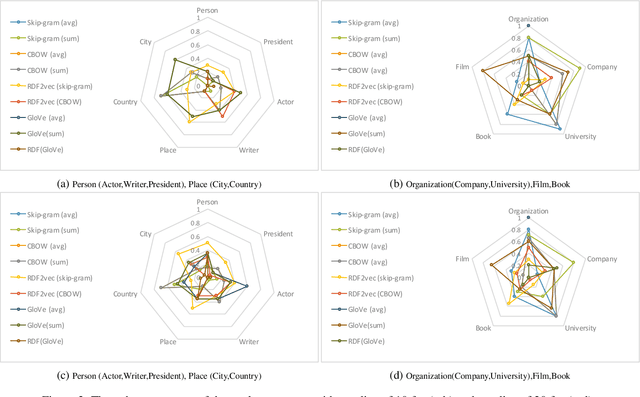
Although there is an emerging trend towards generating embeddings for primarily unstructured data, and recently for structured data, there is not yet any systematic suite for measuring the quality of embeddings. This deficiency is further sensed with respect to embeddings generated for structured data because there are no concrete evaluation metrics measuring the quality of encoded structure as well as semantic patterns in the embedding space. In this paper, we introduce a framework containing three distinct tasks concerned with the individual aspects of ontological concepts: (i) the categorization aspect, (ii) the hierarchical aspect, and (iii) the relational aspect. Then, in the scope of each task, a number of intrinsic metrics are proposed for evaluating the quality of the embeddings. Furthermore, w.r.t. this framework multiple experimental studies were run to compare the quality of the available embedding models. Employing this framework in future research can reduce misjudgment and provide greater insight about quality comparisons of embeddings for ontological concepts.