 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Empowering machine learning models with contextual knowledge for enhancing the detection of eating disorders in social media posts
Feb 08, 2024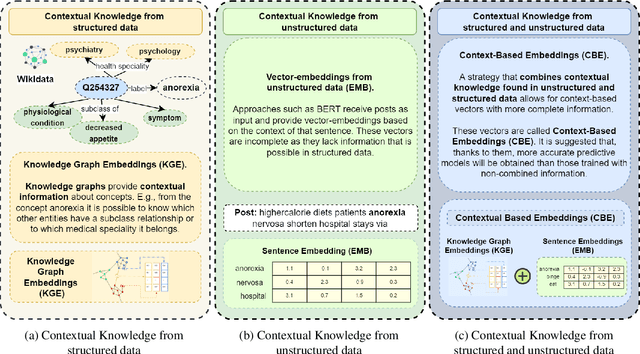
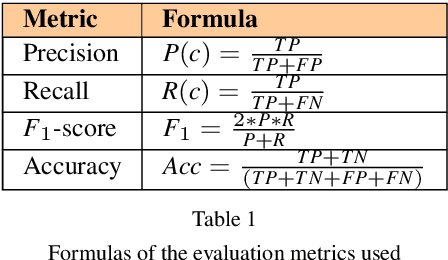
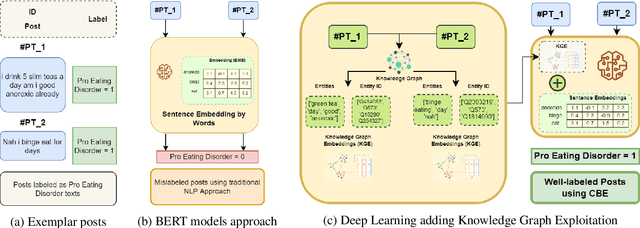
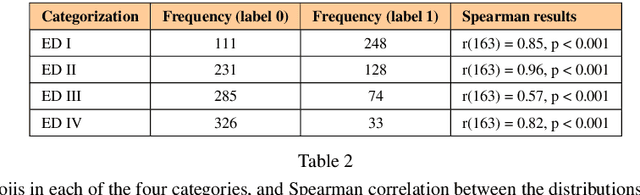
Social networks are vital for information sharing, especially in the health sector for discussing diseases and treatments. These platforms, however, often feature posts as brief texts, posing challenges for Artificial Intelligence (AI) in understanding context. We introduce a novel hybrid approach combining community-maintained knowledge graphs (like Wikidata) with deep learning to enhance the categorization of social media posts. This method uses advanced entity recognizers and linkers (like Falcon 2.0) to connect short post entities to knowledge graphs. Knowledge graph embeddings (KGEs) and contextualized word embeddings (like BERT) are then employed to create rich, context-based representations of these posts. Our focus is on the health domain, particularly in identifying posts related to eating disorders (e.g., anorexia, bulimia) to aid healthcare providers in early diagnosis. We tested our approach on a dataset of 2,000 tweets about eating disorders, finding that merging word embeddings with knowledge graph information enhances the predictive models' reliability. This methodology aims to assist health experts in spotting patterns indicative of mental disorders, thereby improving early detection and accurate diagnosis for personalized medicine.
EABlock: A Declarative Entity Alignment Block for Knowledge Graph Creation Pipelines
Dec 15, 2021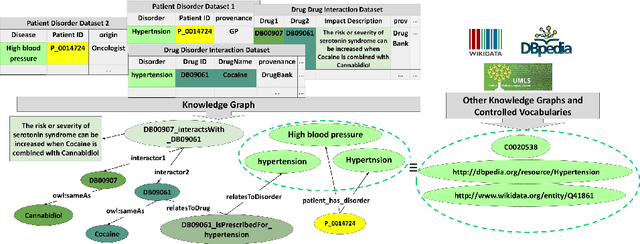
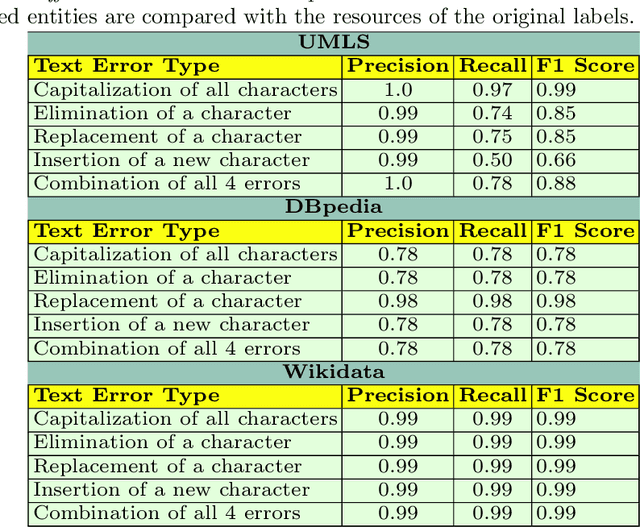
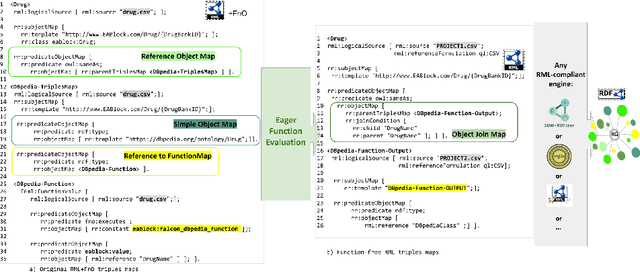
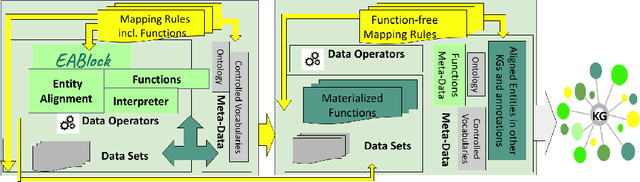
Despite encoding enormous amount of rich and valuable data, existing data sources are mostly created independently, being a significant challenge to their integration. Mapping languages, e.g., RML and R2RML, facilitate declarative specification of the process of applying meta-data and integrating data into a knowledge graph. Mapping rules can also include knowledge extraction functions in addition to expressing correspondences among data sources and a unified schema. Combining mapping rules and functions represents a powerful formalism to specify pipelines for integrating data into a knowledge graph transparently. Surprisingly, these formalisms are not fully adapted, and many knowledge graphs are created by executing ad-hoc programs to pre-process and integrate data. In this paper, we present EABlock, an approach integrating Entity Alignment (EA) as part of RML mapping rules. EABlock includes a block of functions performing entity recognition from textual attributes and link the recognized entities to the corresponding resources in Wikidata, DBpedia, and domain specific thesaurus, e.g., UMLS. EABlock provides agnostic and efficient techniques to evaluate the functions and transfer the mappings to facilitate its application in any RML-compliant engine. We have empirically evaluated EABlock performance, and results indicate that EABlock speeds up knowledge graph creation pipelines that require entity recognition and linking in state-of-the-art RML-compliant engines. EABlock is also publicly available as a tool through a GitHub repository(https://github.com/SDM-TIB/EABlock) and a DOI(https://doi.org/10.5281/zenodo.5779773).
Knowledge Graphs Evolution and Preservation -- A Technical Report from ISWS 2019
Dec 22, 2020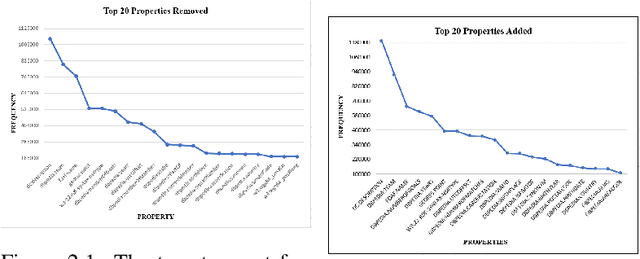
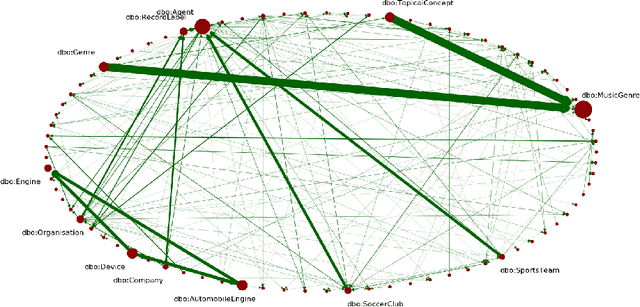

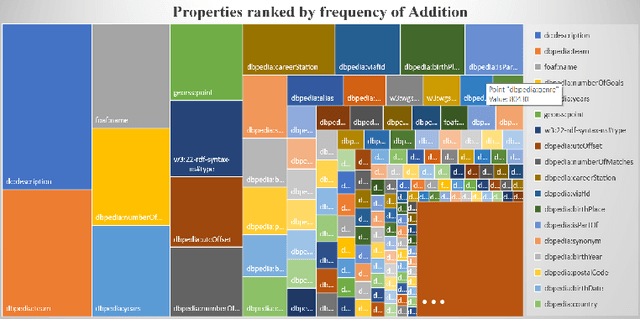
One of the grand challenges discussed during the Dagstuhl Seminar "Knowledge Graphs: New Directions for Knowledge Representation on the Semantic Web" and described in its report is that of a: "Public FAIR Knowledge Graph of Everything: We increasingly see the creation of knowledge graphs that capture information about the entirety of a class of entities. [...] This grand challenge extends this further by asking if we can create a knowledge graph of "everything" ranging from common sense concepts to location based entities. This knowledge graph should be "open to the public" in a FAIR manner democratizing this mass amount of knowledge." Although linked open data (LOD) is one knowledge graph, it is the closest realisation (and probably the only one) to a public FAIR Knowledge Graph (KG) of everything. Surely, LOD provides a unique testbed for experimenting and evaluating research hypotheses on open and FAIR KG. One of the most neglected FAIR issues about KGs is their ongoing evolution and long term preservation. We want to investigate this problem, that is to understand what preserving and supporting the evolution of KGs means and how these problems can be addressed. Clearly, the problem can be approached from different perspectives and may require the development of different approaches, including new theories, ontologies, metrics, strategies, procedures, etc. This document reports a collaborative effort performed by 9 teams of students, each guided by a senior researcher as their mentor, attending the International Semantic Web Research School (ISWS 2019). Each team provides a different perspective to the problem of knowledge graph evolution substantiated by a set of research questions as the main subject of their investigation. In addition, they provide their working definition for KG preservation and evolution.
FALCON 2.0: An Entity and Relation Linking Tool over Wikidata
Feb 12, 2020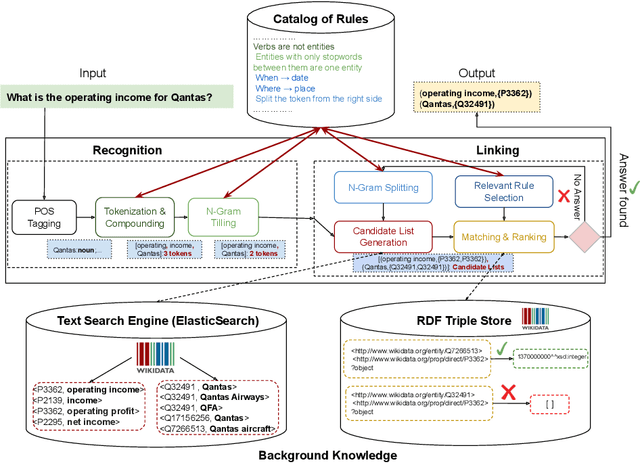

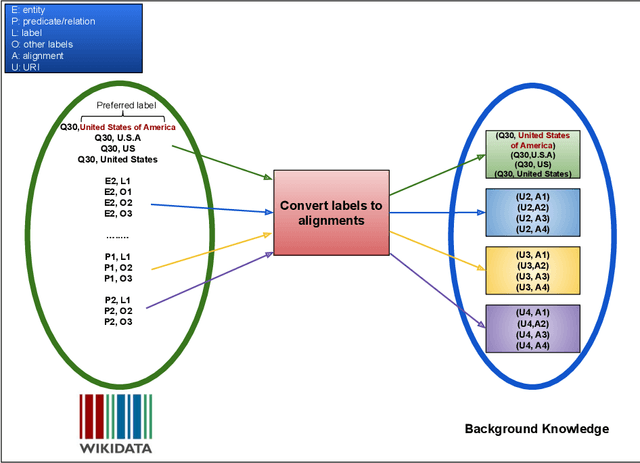

Natural Language Processing (NLP) tools and frameworks have significantly contributed with solutions to the problems of extracting entities and relations and linking them to the related knowledge graphs. Albeit effective, the majority of existing tools are available for only one knowledge graph. In this paper, we present Falcon 2.0, a rule-based tool capable of accurately mapping entities and relations in short texts to resources in both DBpedia and Wikidata following the same approach in both cases. The input of Falcon 2.0 is a short natural language text in the English language. Falcon 2.0 resorts to fundamental principles of the English morphology (e.g., N-Gram tiling and N-Gram splitting) and background knowledge of labels alignments obtained from studied knowledge graph to return as an output; the resulting entity and relation resources are either in the DBpedia or Wikidata knowledge graphs. We have empirically studied the impact using only Wikidata on Falcon 2.0, and observed it is knowledge graph agnostic, i.e., Falcon 2.0 performance and behavior are not affected by the knowledge graph used as background knowledge. Falcon 2.0 is public and can be reused by the community. Additionally, Falcon 2.0 and its background knowledge bases are available as resources at https://labs.tib.eu/falcon/falcon2/.
Context-aware Entity Linking with Attentive Neural Networks on Wikidata Knowledge Graph
Dec 12, 2019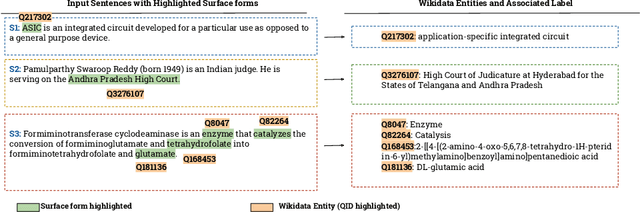
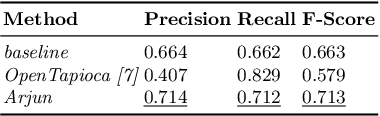
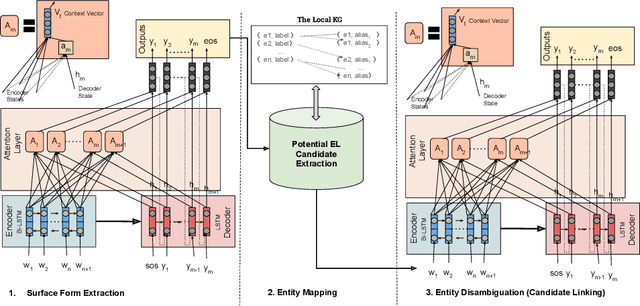
The Entity Linking (EL) approaches have been a long-standing research field and find applicability in various use cases such as semantic search, text annotation, question answering, etc. Although effective and robust, current approaches are still limited to particular knowledge repositories (e.g. Wikipedia) or specific knowledge graphs (e.g. Freebase, DBpedia, and YAGO). The collaborative knowledge graphs such as Wikidata excessively rely on the crowd to author the information. Since the crowd is not bound to a standard protocol for assigning entity titles, the knowledge graph is populated by non-standard, noisy, long or even sometimes awkward titles. The issue of long, implicit, and nonstandard entity representations is a challenge in EL approaches for gaining high precision and recall. In this paper, we advance the state-of-the-art approaches by developing a context-aware attentive neural network approach for entity linking on Wikidata. Our approach contributes by exploiting the sufficient context from a Knowledge Graph as a source of background knowledge, which is then fed into the neural network. This approach demonstrates merit to address challenges associated with entity titles (multi-word, long, implicit, case-sensitive). Our experimental study shows $\approx$8\% improvements over the baseline approach, and significantly outperform an end to end approach for Wikidata entity linking. This work, first of its kind, opens a new direction for the research community to pay attention to developing context-aware EL approaches for collaborative knowledge graphs.