 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification of Psychiatry Clinical Notes by Diagnosis: A Deep Learning and Machine Learning Approach
Aug 01, 2025The classification of clinical notes into specific diagnostic categories is critical in healthcare, especially for mental health conditions like Anxiety and Adjustment Disorder. In this study, we compare the performance of various Artificial Intelligence models, including both traditional Machine Learning approaches (Random Forest, Support Vector Machine, K-nearest neighbors, Decision Tree, and eXtreme Gradient Boost) and Deep Learning models (DistilBERT and SciBERT), to classify clinical notes into these two diagnoses. Additionally, we implemented three oversampling strategies: No Oversampling, Random Oversampling, and Synthetic Minority Oversampling Technique (SMOTE), to assess their impact on model performance. Hyperparameter tuning was also applied to optimize model accuracy. Our results indicate that oversampling techniques had minimal impact on model performance overall. The only exception was SMOTE, which showed a positive effect specifically with BERT-based models. However, hyperparameter optimization significantly improved accuracy across the models, enhancing their ability to generalize and perform on the dataset. The Decision Tree and eXtreme Gradient Boost models achieved the highest accuracy among machine learning approaches, both reaching 96%, while the DistilBERT and SciBERT models also attained 96% accuracy in the deep learning category. These findings underscore the importance of hyperparameter tuning in maximizing model performance. This study contributes to the ongoing research on AI-assisted diagnostic tools in mental health by providing insights into the efficacy of different model architectures and data balancing methods.
TEDNet: Twin Encoder Decoder Neural Network for 2D Camera and LiDAR Road Detection
May 14, 2024Robust road surface estimation is required for autonomous ground vehicles to navigate safely. Despite it becoming one of the main targets for autonomous mobility researchers in recent years, it is still an open problem in which cameras and LiDAR sensors have demonstrated to be adequate to predict the position, size and shape of the road a vehicle is driving on in different environments. In this work, a novel Convolutional Neural Network model is proposed for the accurate estimation of the roadway surface. Furthermore, an ablation study has been conducted to investigate how different encoding strategies affect model performance, testing 6 slightly different neural network architectures. Our model is based on the use of a Twin Encoder-Decoder Neural Network (TEDNet) for independent camera and LiDAR feature extraction, and has been trained and evaluated on the Kitti-Road dataset. Bird's Eye View projections of the camera and LiDAR data are used in this model to perform semantic segmentation on whether each pixel belongs to the road surface. The proposed method performs among other state-of-the-art methods and operates at the same frame-rate as the LiDAR and cameras, so it is adequate for its use in real-time applications.
* Source code: https://github.com/martin-bayon/TEDNet
Enhancing ASD detection accuracy: a combined approach of machine learning and deep learning models with natural language processing
Mar 06, 2024Purpose: Our study explored the use of artificial intelligence (AI) to diagnose autism spectrum disorder (ASD). It focused on machine learning (ML) and deep learning (DL) to detect ASD from text inputs on social media, addressing challenges in traditional ASD diagnosis. Methods: We used natural language processing (NLP), ML, and DL models (including decision trees, XGB, KNN, RNN, LSTM, Bi-LSTM, BERT, and BERTweet) to analyze 404,627 tweets, classifying them based on ASD or non-ASD authors. A subset of 90,000 tweets was used for model training and testing. Results: Our AI models showed high accuracy, with an 88% success rate in identifying texts from individuals with ASD. Conclusion: The study demonstrates AI's potential in improving ASD diagnosis, especially in children, highlighting the importance of early detection.
Evaluation of Country Dietary Habits Using Machine Learning Techniques in Relation to Deaths from COVID-19
Feb 19, 2024



COVID-19 disease has affected almost every country in the world. The large number of infected people and the different mortality rates between countries has given rise to many hypotheses about the key points that make the virus so lethal in some places. In this study, the eating habits of 170 countries were evaluated in order to find correlations between these habits and mortality rates caused by COVID-19 using machine learning techniques that group the countries together according to the different distribution of fat, energy, and protein across 23 different types of food, as well as the amount ingested in kilograms. Results shown how obesity and the high consumption of fats appear in countries with the highest death rates, whereas countries with a lower rate have a higher level of cereal consumption accompanied by a lower total average intake of kilocalories.
Implementing local-explainability in Gradient Boosting Trees: Feature Contribution
Feb 14, 2024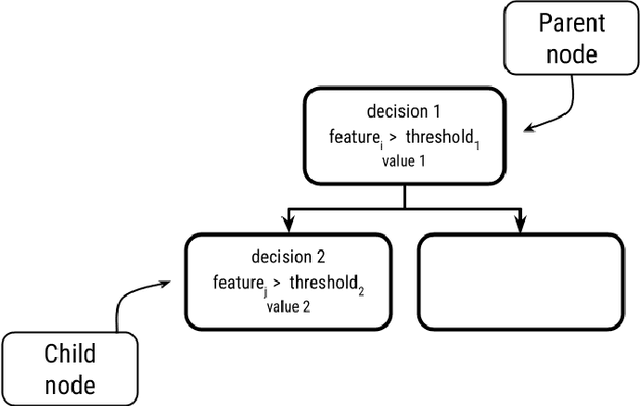
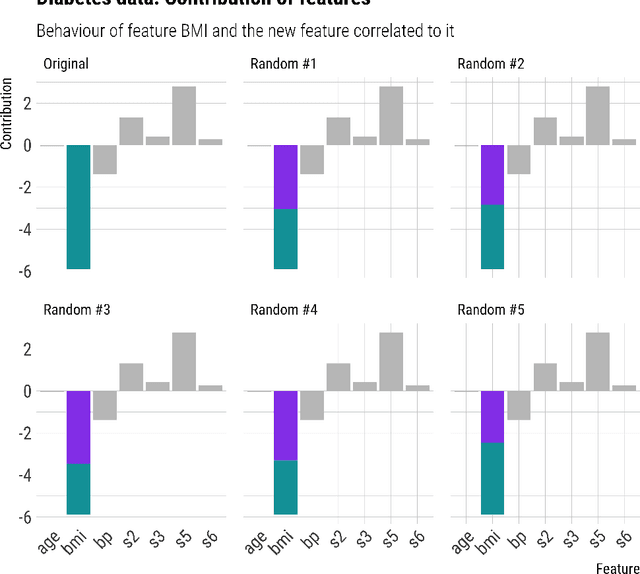
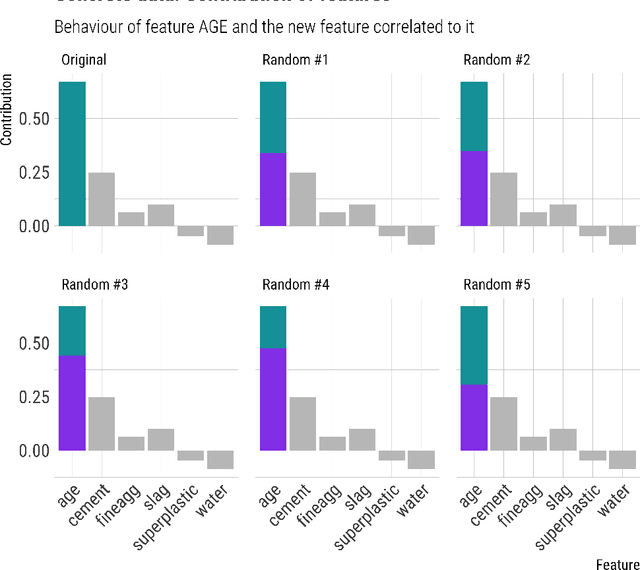
Gradient Boost Decision Trees (GBDT) is a powerful additive model based on tree ensembles. Its nature makes GBDT a black-box model even though there are multiple explainable artificial intelligence (XAI) models obtaining information by reinterpreting the model globally and locally. Each tree of the ensemble is a transparent model itself but the final outcome is the result of a sum of these trees and it is not easy to clarify. In this paper, a feature contribution method for GBDT is developed. The proposed method takes advantage of the GBDT architecture to calculate the contribution of each feature using the residue of each node. This algorithm allows to calculate the sequence of node decisions given a prediction. Theoretical proofs and multiple experiments have been carried out to demonstrate the performance of our method which is not only a local explicability model for the GBDT algorithm but also a unique option that reflects GBDTs internal behavior. The proposal is aligned to the contribution of characteristics having impact in some artificial intelligence problems such as ethical analysis of Artificial Intelligence (AI) and comply with the new European laws such as the General Data Protection Regulation (GDPR) about the right to explain and nondiscrimination.
Detection of the most influential variables for preventing postpartum urinary incontinence using machine learning techniques
Feb 14, 2024



Background: Postpartum urinary incontinence (PUI) is a common issue among postnatal women. Previous studies identified potential related variables, but lacked analysis on certain intrinsic and extrinsic patient variables during pregnancy. Objective: The study aims to evaluate the most influential variables in PUI using machine learning, focusing on intrinsic, extrinsic, and combined variable groups. Methods: Data from 93 pregnant women were analyzed using machine learning and oversampling techniques. Four key variables were predicted: occurrence, frequency, intensity of urinary incontinence, and stress urinary incontinence. Results: Models using extrinsic variables were most accurate, with 70% accuracy for urinary incontinence, 77% for frequency, 71% for intensity, and 93% for stress urinary incontinence. Conclusions: The study highlights extrinsic variables as significant predictors of PUI issues. This suggests that PUI prevention might be achievable through healthy habits during pregnancy, although further research is needed for confirmation.
Clustering Techniques Selection for a Hybrid Regression Model: A Case Study Based on a Solar Thermal System
Feb 10, 2024This work addresses the performance comparison between four clustering techniques with the objective of achieving strong hybrid models in supervised learning tasks. A real dataset from a bio-climatic house named Sotavento placed on experimental wind farm and located in Xermade (Lugo) in Galicia (Spain) has been collected. Authors have chosen the thermal solar generation system in order to study how works applying several cluster methods followed by a regression technique to predict the output temperature of the system. With the objective of defining the quality of each clustering method two possible solutions have been implemented. The first one is based on three unsupervised learning metrics (Silhouette, Calinski-Harabasz and Davies-Bouldin) while the second one, employs the most common error measurements for a regression algorithm such as Multi Layer Perceptron.
Determining the severity of Parkinson's disease in patients using a multi task neural network
Feb 08, 2024Parkinson's disease is easy to diagnose when it is advanced, but it is very difficult to diagnose in its early stages. Early diagnosis is essential to be able to treat the symptoms. It impacts on daily activities and reduces the quality of life of both the patients and their families and it is also the second most prevalent neurodegenerative disorder after Alzheimer in people over the age of 60. Most current studies on the prediction of Parkinson's severity are carried out in advanced stages of the disease. In this work, the study analyzes a set of variables that can be easily extracted from voice analysis, making it a very non-intrusive technique. In this paper, a method based on different deep learning techniques is proposed with two purposes. On the one hand, to find out if a person has severe or non-severe Parkinson's disease, and on the other hand, to determine by means of regression techniques the degree of evolution of the disease in a given patient. The UPDRS (Unified Parkinson's Disease Rating Scale) has been used by taking into account both the motor and total labels, and the best results have been obtained using a mixed multi-layer perceptron (MLP) that classifies and regresses at the same time and the most important features of the data obtained are taken as input, using an autoencoder. A success rate of 99.15% has been achieved in the problem of predicting whether a person suffers from severe Parkinson's disease or non-severe Parkinson's disease. In the degree of disease involvement prediction problem case, a MSE (Mean Squared Error) of 0.15 has been obtained. Using a full deep learning pipeline for data preprocessing and classification has proven to be very promising in the field Parkinson's outperforming the state-of-the-art proposals.
Traditional Machine Learning Models and Bidirectional Encoder Representations From Transformer (BERT)-Based Automatic Classification of Tweets About Eating Disorders: Algorithm Development and Validation Study
Feb 08, 2024



Background: Eating disorders are increasingly prevalent, and social networks offer valuable information. Objective: Our goal was to identify efficient machine learning models for categorizing tweets related to eating disorders. Methods: Over three months, we collected tweets about eating disorders. A 2,000-tweet subset was labeled for: (1) being written by individuals with eating disorders, (2) promoting eating disorders, (3) informativeness, and (4) scientific content. Both traditional machine learning and deep learning models were employed for classification, assessing accuracy, F1 score, and computational time. Results: From 1,058,957 collected tweets, transformer-based bidirectional encoder representations achieved the highest F1 scores (71.1%-86.4%) across all four categories. Conclusions: Transformer-based models outperform traditional techniques in classifying eating disorder-related tweets, though they require more computational resources.
Multispecies bird sound recognition using a fully convolutional neural network
Feb 08, 2024This study proposes a method based on fully convolutional neural networks (FCNs) to identify migratory birds from their songs, with the objective of recognizing which birds pass through certain areas and at what time. To determine the best FCN architecture, extensive experimentation was conducted through a grid search, exploring the optimal depth, width, and activation function of the network. The results showed that the optimal number of filters is 400 in the widest layer, with 4 convolutional blocks with maxpooling and an adaptive activation function. The proposed FCN offers a significant advantage over other techniques, as it can recognize the sound of a bird in audio of any length with an accuracy greater than 85%. Furthermore, due to its architecture, the network can detect more than one species from audio and can carry out near-real-time sound recognition. Additionally, the proposed method is lightweight, making it ideal for deployment and use in IoT devices. The study also presents a comparative analysis of the proposed method against other techniques, demonstrating an improvement of over 67% in the best-case scenario. These findings contribute to advancing the field of bird sound recognition and provide valuable insights into the practical application of FCNs in real-world scenarios.