 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial network analysis for personalized characterization and risk assessment of alcohol use disorders in adolescents using semantic technologies
Feb 14, 2024



Alcohol Use Disorder (AUD) is a major concern for public health organizations worldwide, especially as regards the adolescent population. The consumption of alcohol in adolescents is known to be influenced by seeing friends and even parents drinking alcohol. Building on this fact, a number of studies into alcohol consumption among adolescents have made use of Social Network Analysis (SNA) techniques to study the different social networks (peers, friends, family, etc.) with whom the adolescent is involved. These kinds of studies need an initial phase of data gathering by means of questionnaires and a subsequent analysis phase using the SNA techniques. The process involves a number of manual data handling stages that are time consuming and error-prone. The use of knowledge engineering techniques (including the construction of a domain ontology) to represent the information, allows the automation of all the activities, from the initial data collection to the results of the SNA study. This paper shows how a knowledge model is constructed, and compares the results obtained using the traditional method with this, fully automated model, detailing the main advantages of the latter. In the case of the SNA analysis, the validity of the results obtained with the knowledge engineering approach are compared to those obtained manually using the UCINET, Cytoscape, Pajek and Gephi to test the accuracy of the knowledge model.
Clustering Techniques Selection for a Hybrid Regression Model: A Case Study Based on a Solar Thermal System
Feb 10, 2024This work addresses the performance comparison between four clustering techniques with the objective of achieving strong hybrid models in supervised learning tasks. A real dataset from a bio-climatic house named Sotavento placed on experimental wind farm and located in Xermade (Lugo) in Galicia (Spain) has been collected. Authors have chosen the thermal solar generation system in order to study how works applying several cluster methods followed by a regression technique to predict the output temperature of the system. With the objective of defining the quality of each clustering method two possible solutions have been implemented. The first one is based on three unsupervised learning metrics (Silhouette, Calinski-Harabasz and Davies-Bouldin) while the second one, employs the most common error measurements for a regression algorithm such as Multi Layer Perceptron.
Multispecies bird sound recognition using a fully convolutional neural network
Feb 08, 2024This study proposes a method based on fully convolutional neural networks (FCNs) to identify migratory birds from their songs, with the objective of recognizing which birds pass through certain areas and at what time. To determine the best FCN architecture, extensive experimentation was conducted through a grid search, exploring the optimal depth, width, and activation function of the network. The results showed that the optimal number of filters is 400 in the widest layer, with 4 convolutional blocks with maxpooling and an adaptive activation function. The proposed FCN offers a significant advantage over other techniques, as it can recognize the sound of a bird in audio of any length with an accuracy greater than 85%. Furthermore, due to its architecture, the network can detect more than one species from audio and can carry out near-real-time sound recognition. Additionally, the proposed method is lightweight, making it ideal for deployment and use in IoT devices. The study also presents a comparative analysis of the proposed method against other techniques, demonstrating an improvement of over 67% in the best-case scenario. These findings contribute to advancing the field of bird sound recognition and provide valuable insights into the practical application of FCNs in real-world scenarios.
An Ontology-Based multi-domain model in Social Network Analysis: Experimental validation and case study
Feb 03, 2024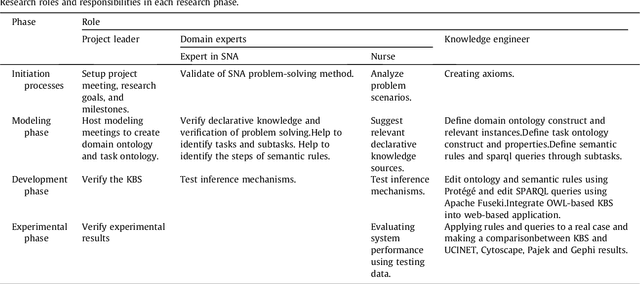
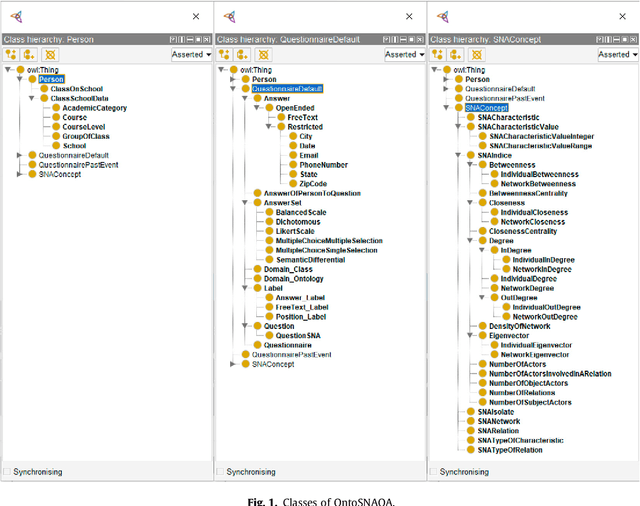
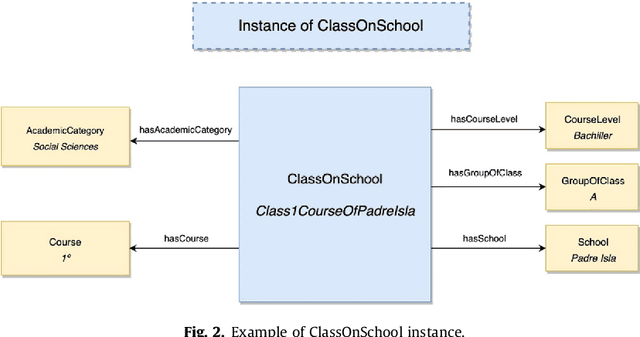
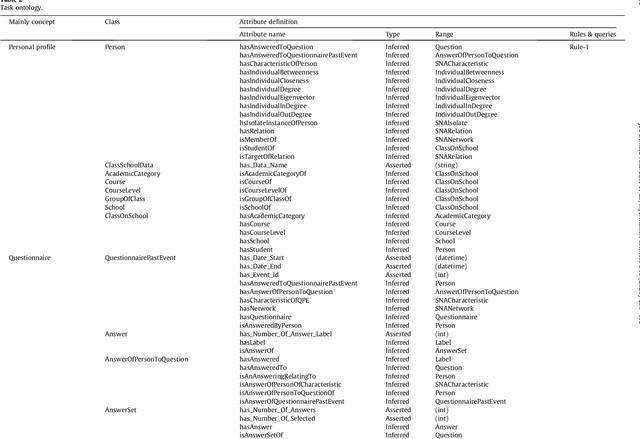
The use of social network theory and methods of analysis have been applied to different domains in recent years, including public health. The complete procedure for carrying out a social network analysis (SNA) is a time-consuming task that entails a series of steps in which the expert in social network analysis could make mistakes. This research presents a multi-domain knowledge model capable of automatically gathering data and carrying out different social network analyses in different domains, without errors and obtaining the same conclusions that an expert in SNA would obtain. The model is represented in an ontology called OntoSNAQA, which is made up of classes, properties and rules representing the domains of People, Questionnaires and Social Network Analysis. Besides the ontology itself, different rules are represented by SWRL and SPARQL queries. A Knowledge Based System was created using OntoSNAQA and applied to a real case study in order to show the advantages of the approach. Finally, the results of an SNA analysis obtained through the model were compared to those obtained from some of the most widely used SNA applications: UCINET, Pajek, Cytoscape and Gephi, to test and confirm the validity of the model.
Sentiment analysis in non-fixed length audios using a Fully Convolutional Neural Network
Feb 03, 2024



In this work, a sentiment analysis method that is capable of accepting audio of any length, without being fixed a priori, is proposed. Mel spectrogram and Mel Frequency Cepstral Coefficients are used as audio description methods and a Fully Convolutional Neural Network architecture is proposed as a classifier. The results have been validated using three well known datasets: EMODB, RAVDESS, and TESS. The results obtained were promising, outperforming the state-of-the-art methods. Also, thanks to the fact that the proposed method admits audios of any size, it allows a sentiment analysis to be made in near real time, which is very interesting for a wide range of fields such as call centers, medical consultations, or financial brokers.
Diabetes detection using deep learning techniques with oversampling and feature augmentation
Feb 03, 2024Background and objective: Diabetes is a chronic pathology which is affecting more and more people over the years. It gives rise to a large number of deaths each year. Furthermore, many people living with the disease do not realize the seriousness of their health status early enough. Late diagnosis brings about numerous health problems and a large number of deaths each year so the development of methods for the early diagnosis of this pathology is essential. Methods: In this paper, a pipeline based on deep learning techniques is proposed to predict diabetic people. It includes data augmentation using a variational autoencoder (VAE), feature augmentation using an sparse autoencoder (SAE) and a convolutional neural network for classification. Pima Indians Diabetes Database, which takes into account information on the patients such as the number of pregnancies, glucose or insulin level, blood pressure or age, has been evaluated. Results: A 92.31% of accuracy was obtained when CNN classifier is trained jointly the SAE for featuring augmentation over a well balanced dataset. This means an increment of 3.17% of accuracy with respect the state-of-the-art. Conclusions: Using a full deep learning pipeline for data preprocessing and classification has demonstrate to be very promising in the diabetes detection field outperforming the state-of-the-art proposals.
Detecting Respiratory Pathologies Using Convolutional Neural Networks and Variational Autoencoders for Unbalancing Data
Feb 03, 2024



The aim of this paper was the detection of pathologies through respiratory sounds. The ICBHI (International Conference on Biomedical and Health Informatics) Benchmark was used. This dataset is composed of 920 sounds of which 810 are of chronic diseases, 75 of non-chronic diseases and only 35 of healthy individuals. As more than 88% of the samples of the dataset are from the same class (Chronic), the use of a Variational Convolutional Autoencoder was proposed to generate new labeled data and other well known oversampling techniques after determining that the dataset classes are unbalanced. Once the preprocessing step was carried out, a Convolutional Neural Network (CNN) was used to classify the respiratory sounds into healthy, chronic, and non-chronic disease. In addition, we carried out a more challenging classification trying to distinguish between the different types of pathologies or healthy: URTI, COPD, Bronchiectasis, Pneumonia, and Bronchiolitis. We achieved results up to 0.993 F-Score in the three-label classification and 0.990 F-Score in the more challenging six-class classification.