 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Country Dietary Habits Using Machine Learning Techniques in Relation to Deaths from COVID-19
Feb 19, 2024



COVID-19 disease has affected almost every country in the world. The large number of infected people and the different mortality rates between countries has given rise to many hypotheses about the key points that make the virus so lethal in some places. In this study, the eating habits of 170 countries were evaluated in order to find correlations between these habits and mortality rates caused by COVID-19 using machine learning techniques that group the countries together according to the different distribution of fat, energy, and protein across 23 different types of food, as well as the amount ingested in kilograms. Results shown how obesity and the high consumption of fats appear in countries with the highest death rates, whereas countries with a lower rate have a higher level of cereal consumption accompanied by a lower total average intake of kilocalories.
Social network analysis for personalized characterization and risk assessment of alcohol use disorders in adolescents using semantic technologies
Feb 14, 2024



Alcohol Use Disorder (AUD) is a major concern for public health organizations worldwide, especially as regards the adolescent population. The consumption of alcohol in adolescents is known to be influenced by seeing friends and even parents drinking alcohol. Building on this fact, a number of studies into alcohol consumption among adolescents have made use of Social Network Analysis (SNA) techniques to study the different social networks (peers, friends, family, etc.) with whom the adolescent is involved. These kinds of studies need an initial phase of data gathering by means of questionnaires and a subsequent analysis phase using the SNA techniques. The process involves a number of manual data handling stages that are time consuming and error-prone. The use of knowledge engineering techniques (including the construction of a domain ontology) to represent the information, allows the automation of all the activities, from the initial data collection to the results of the SNA study. This paper shows how a knowledge model is constructed, and compares the results obtained using the traditional method with this, fully automated model, detailing the main advantages of the latter. In the case of the SNA analysis, the validity of the results obtained with the knowledge engineering approach are compared to those obtained manually using the UCINET, Cytoscape, Pajek and Gephi to test the accuracy of the knowledge model.
A Web-Based Tool for Automatic Data Collection, Curation, and Visualization of Complex Healthcare Survey Studies including Social Network Analysis
Feb 14, 2024


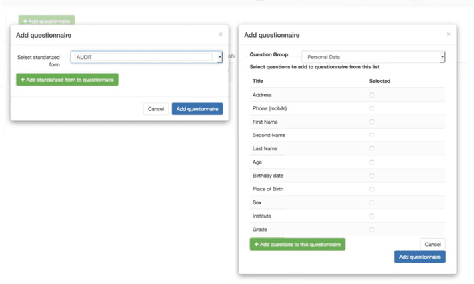
There is a great concern nowadays regarding alcohol consumption and drug abuse, especially in young people. Analyzing the social environment where these adolescents are immersed, as well as a series of measures determining the alcohol abuse risk or personal situation and perception using a number of questionnaires like AUDIT, FAS, KIDSCREEN, and others, it is possible to gain insight into the current situation of a given individual regarding his/her consumption behavior. But this analysis, in order to be achieved, requires the use of tools that can ease the process of questionnaire creation, data gathering, curation and representation, and later analysis and visualization to the user. This research presents the design and construction of a web-based platform able to facilitate each of the mentioned processes by integrating the different phases into an intuitive system with a graphical user interface that hides the complexity underlying each of the questionnaires and techniques used and presenting the results in a flexible and visual way, avoiding any manual handling of data during the process. Advantages of this approach are shown and compared to the previous situation where some of the tasks were accomplished by time consuming and error prone manipulations of data.
A Semantic Social Network Analysis Tool for Sensitivity Analysis and What-If Scenario Testing in Alcohol Consumption Studies
Feb 14, 2024



Social Network Analysis (SNA) is a set of techniques developed in the field of social and behavioral sciences research, in order to characterize and study the social relationships that are established among a set of individuals. When building a social network for performing an SNA analysis, an initial process of data gathering is achieved in order to extract the characteristics of the individuals and their relationships. This is usually done by completing a questionnaire containing different types of questions that will be later used to obtain the SNA measures needed to perform the study. There are, then, a great number of different possible network generating questions and also many possibilities for mapping the responses to the corresponding characteristics and relationships. Many variations may be introduced into these questions (the way they are posed, the weights given to each of the responses, etc.) that may have an effect on the resulting networks. All these different variations are difficult to achieve manually, because the process is time-consuming and error prone. The tool described in this paper uses semantic knowledge representation techniques in order to facilitate this kind of sensitivity studies. The base of the tool is a conceptual structure, called "ontology" that is able to represent the different concepts and their definitions. The tool is compared to other similar ones, and the advantages of the approach are highlighted, giving some particular examples from an ongoing SNA study about alcohol consumption habits in adolescents.
Determining the severity of Parkinson's disease in patients using a multi task neural network
Feb 08, 2024Parkinson's disease is easy to diagnose when it is advanced, but it is very difficult to diagnose in its early stages. Early diagnosis is essential to be able to treat the symptoms. It impacts on daily activities and reduces the quality of life of both the patients and their families and it is also the second most prevalent neurodegenerative disorder after Alzheimer in people over the age of 60. Most current studies on the prediction of Parkinson's severity are carried out in advanced stages of the disease. In this work, the study analyzes a set of variables that can be easily extracted from voice analysis, making it a very non-intrusive technique. In this paper, a method based on different deep learning techniques is proposed with two purposes. On the one hand, to find out if a person has severe or non-severe Parkinson's disease, and on the other hand, to determine by means of regression techniques the degree of evolution of the disease in a given patient. The UPDRS (Unified Parkinson's Disease Rating Scale) has been used by taking into account both the motor and total labels, and the best results have been obtained using a mixed multi-layer perceptron (MLP) that classifies and regresses at the same time and the most important features of the data obtained are taken as input, using an autoencoder. A success rate of 99.15% has been achieved in the problem of predicting whether a person suffers from severe Parkinson's disease or non-severe Parkinson's disease. In the degree of disease involvement prediction problem case, a MSE (Mean Squared Error) of 0.15 has been obtained. Using a full deep learning pipeline for data preprocessing and classification has proven to be very promising in the field Parkinson's outperforming the state-of-the-art proposals.
Heart disease risk prediction using deep learning techniques with feature augmentation
Feb 08, 2024Cardiovascular diseases state as one of the greatest risks of death for the general population. Late detection in heart diseases highly conditions the chances of survival for patients. Age, sex, cholesterol level, sugar level, heart rate, among other factors, are known to have an influence on life-threatening heart problems, but, due to the high amount of variables, it is often difficult for an expert to evaluate each patient taking this information into account. In this manuscript, the authors propose using deep learning methods, combined with feature augmentation techniques for evaluating whether patients are at risk of suffering cardiovascular disease. The results of the proposed methods outperform other state of the art methods by 4.4%, leading to a precision of a 90%, which presents a significant improvement, even more so when it comes to an affliction that affects a large population.
Multiclass Classification Procedure for Detecting Attacks on MQTT-IoT Protocol
Feb 05, 2024



The large number of sensors and actuators that make up the Internet of Things obliges these systems to use diverse technologies and protocols. This means that IoT networks are more heterogeneous than traditional networks. This gives rise to new challenges in cybersecurity to protect these systems and devices which are characterized by being connected continuously to the Internet. Intrusion detection systems (IDS) are used to protect IoT systems from the various anomalies and attacks at the network level. Intrusion Detection Systems (IDS) can be improved through machine learning techniques. Our work focuses on creating classification models that can feed an IDS using a dataset containing frames under attacks of an IoT system that uses the MQTT protocol. We have addressed two types of method for classifying the attacks, ensemble methods and deep learning models, more specifically recurrent networks with very satisfactory results.
Detecting Respiratory Pathologies Using Convolutional Neural Networks and Variational Autoencoders for Unbalancing Data
Feb 03, 2024



The aim of this paper was the detection of pathologies through respiratory sounds. The ICBHI (International Conference on Biomedical and Health Informatics) Benchmark was used. This dataset is composed of 920 sounds of which 810 are of chronic diseases, 75 of non-chronic diseases and only 35 of healthy individuals. As more than 88% of the samples of the dataset are from the same class (Chronic), the use of a Variational Convolutional Autoencoder was proposed to generate new labeled data and other well known oversampling techniques after determining that the dataset classes are unbalanced. Once the preprocessing step was carried out, a Convolutional Neural Network (CNN) was used to classify the respiratory sounds into healthy, chronic, and non-chronic disease. In addition, we carried out a more challenging classification trying to distinguish between the different types of pathologies or healthy: URTI, COPD, Bronchiectasis, Pneumonia, and Bronchiolitis. We achieved results up to 0.993 F-Score in the three-label classification and 0.990 F-Score in the more challenging six-class classification.
Sentiment analysis in non-fixed length audios using a Fully Convolutional Neural Network
Feb 03, 2024



In this work, a sentiment analysis method that is capable of accepting audio of any length, without being fixed a priori, is proposed. Mel spectrogram and Mel Frequency Cepstral Coefficients are used as audio description methods and a Fully Convolutional Neural Network architecture is proposed as a classifier. The results have been validated using three well known datasets: EMODB, RAVDESS, and TESS. The results obtained were promising, outperforming the state-of-the-art methods. Also, thanks to the fact that the proposed method admits audios of any size, it allows a sentiment analysis to be made in near real time, which is very interesting for a wide range of fields such as call centers, medical consultations, or financial brokers.
Diabetes detection using deep learning techniques with oversampling and feature augmentation
Feb 03, 2024Background and objective: Diabetes is a chronic pathology which is affecting more and more people over the years. It gives rise to a large number of deaths each year. Furthermore, many people living with the disease do not realize the seriousness of their health status early enough. Late diagnosis brings about numerous health problems and a large number of deaths each year so the development of methods for the early diagnosis of this pathology is essential. Methods: In this paper, a pipeline based on deep learning techniques is proposed to predict diabetic people. It includes data augmentation using a variational autoencoder (VAE), feature augmentation using an sparse autoencoder (SAE) and a convolutional neural network for classification. Pima Indians Diabetes Database, which takes into account information on the patients such as the number of pregnancies, glucose or insulin level, blood pressure or age, has been evaluated. Results: A 92.31% of accuracy was obtained when CNN classifier is trained jointly the SAE for featuring augmentation over a well balanced dataset. This means an increment of 3.17% of accuracy with respect the state-of-the-art. Conclusions: Using a full deep learning pipeline for data preprocessing and classification has demonstrate to be very promising in the diabetes detection field outperforming the state-of-the-art proposals.