 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplementing local-explainability in Gradient Boosting Trees: Feature Contribution
Feb 14, 2024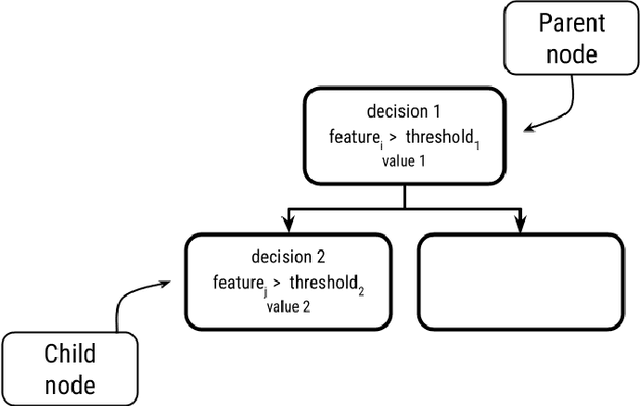
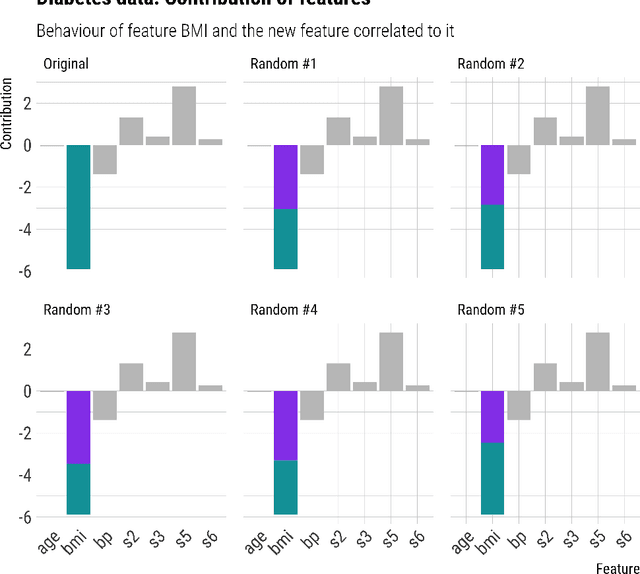
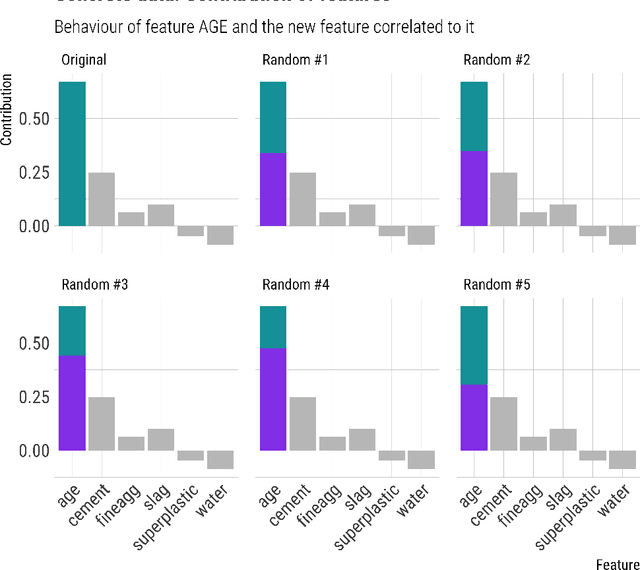
Gradient Boost Decision Trees (GBDT) is a powerful additive model based on tree ensembles. Its nature makes GBDT a black-box model even though there are multiple explainable artificial intelligence (XAI) models obtaining information by reinterpreting the model globally and locally. Each tree of the ensemble is a transparent model itself but the final outcome is the result of a sum of these trees and it is not easy to clarify. In this paper, a feature contribution method for GBDT is developed. The proposed method takes advantage of the GBDT architecture to calculate the contribution of each feature using the residue of each node. This algorithm allows to calculate the sequence of node decisions given a prediction. Theoretical proofs and multiple experiments have been carried out to demonstrate the performance of our method which is not only a local explicability model for the GBDT algorithm but also a unique option that reflects GBDTs internal behavior. The proposal is aligned to the contribution of characteristics having impact in some artificial intelligence problems such as ethical analysis of Artificial Intelligence (AI) and comply with the new European laws such as the General Data Protection Regulation (GDPR) about the right to explain and nondiscrimination.
A generalized decision tree ensemble based on the NeuralNetworks architecture: Distributed Gradient Boosting Forest
Feb 04, 2024Tree ensemble algorithms as RandomForest and GradientBoosting are currently the dominant methods for modeling discrete or tabular data, however, they are unable to perform a hierarchical representation learning from raw data as NeuralNetworks does thanks to its multi-layered structure, which is a key feature for DeepLearning problems and modeling unstructured data. This limitation is due to the fact that tree algorithms can not be trained with back-propagation because of their mathematical nature. However, in this work, we demonstrate that the mathematical formulation of bagging and boosting can be combined together to define a graph-structured-tree-ensemble algorithm with a distributed representation learning process between trees naturally (without using back-propagation). We call this novel approach Distributed Gradient Boosting Forest (DGBF) and we demonstrate that both RandomForest and GradientBoosting can be expressed as particular graph architectures of DGBT. Finally, we see that the distributed learning outperforms both RandomForest and GradientBoosting in 7 out of 9 datasets.