 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArticulation Work and Tinkering for Fairness in Machine Learning
Jul 23, 2024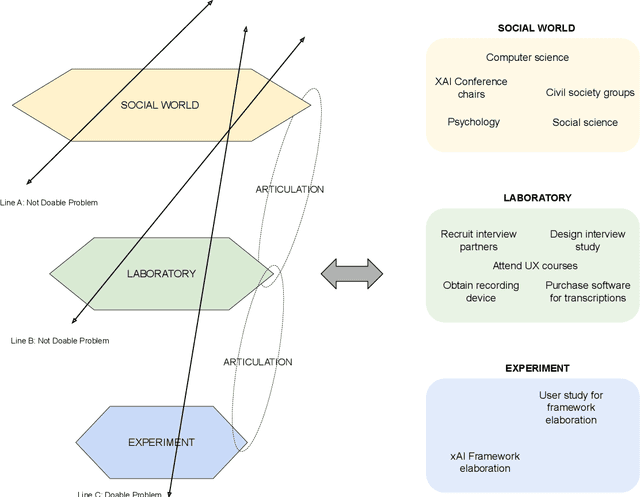

The field of fair AI aims to counter biased algorithms through computational modelling. However, it faces increasing criticism for perpetuating the use of overly technical and reductionist methods. As a result, novel approaches appear in the field to address more socially-oriented and interdisciplinary (SOI) perspectives on fair AI. In this paper, we take this dynamic as the starting point to study the tension between computer science (CS) and SOI research. By drawing on STS and CSCW theory, we position fair AI research as a matter of 'organizational alignment': what makes research 'doable' is the successful alignment of three levels of work organization (the social world, the laboratory and the experiment). Based on qualitative interviews with CS researchers, we analyze the tasks, resources, and actors required for doable research in the case of fair AI. We find that CS researchers engage with SOI to some extent, but organizational conditions, articulation work, and ambiguities of the social world constrain the doability of SOI research. Based on our findings, we identify and discuss problems for aligning CS and SOI as fair AI continues to evolve.
Leveraging Ontologies to Document Bias in Data
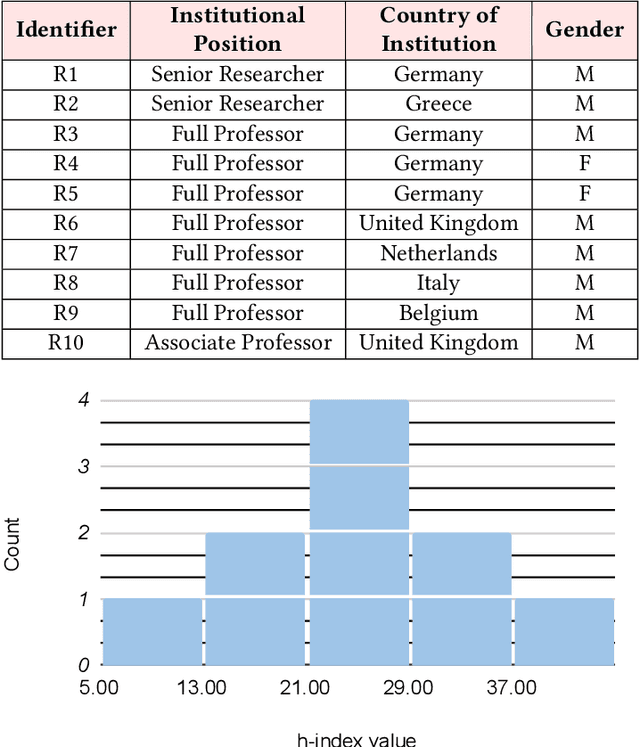
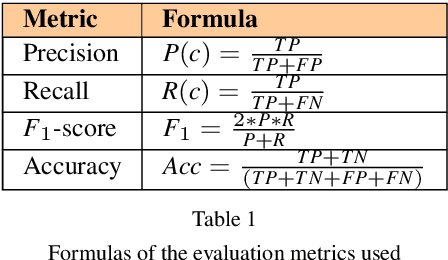
Jun 29, 2024Machine Learning (ML) systems are capable of reproducing and often amplifying undesired biases. This puts emphasis on the importance of operating under practices that enable the study and understanding of the intrinsic characteristics of ML pipelines, prompting the emergence of documentation frameworks with the idea that ``any remedy for bias starts with awareness of its existence''. However, a resource that can formally describe these pipelines in terms of biases detected is still amiss. To fill this gap, we present the Doc-BiasO ontology, a resource that aims to create an integrated vocabulary of biases defined in the \textit{fair-ML} literature and their measures, as well as to incorporate relevant terminology and the relationships between them. Overseeing ontology engineering best practices, we re-use existing vocabulary on machine learning and AI, to foster knowledge sharing and interoperability between the actors concerned with its research, development, regulation, among others. Overall, our main objective is to contribute towards clarifying existing terminology on bias research as it rapidly expands to all areas of AI and to improve the interpretation of bias in data and downstream impact.
Empowering machine learning models with contextual knowledge for enhancing the detection of eating disorders in social media posts
Feb 08, 2024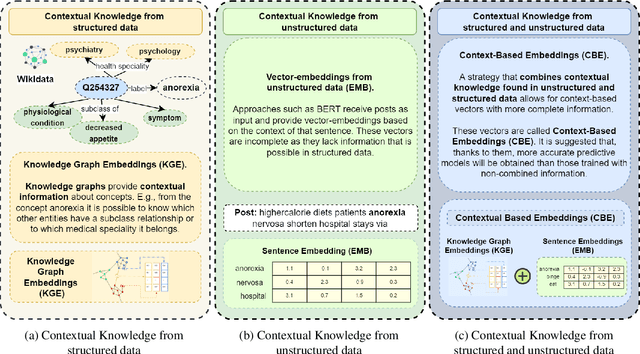
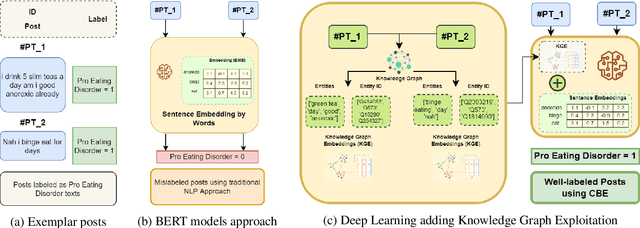
Social networks are vital for information sharing, especially in the health sector for discussing diseases and treatments. These platforms, however, often feature posts as brief texts, posing challenges for Artificial Intelligence (AI) in understanding context. We introduce a novel hybrid approach combining community-maintained knowledge graphs (like Wikidata) with deep learning to enhance the categorization of social media posts. This method uses advanced entity recognizers and linkers (like Falcon 2.0) to connect short post entities to knowledge graphs. Knowledge graph embeddings (KGEs) and contextualized word embeddings (like BERT) are then employed to create rich, context-based representations of these posts. Our focus is on the health domain, particularly in identifying posts related to eating disorders (e.g., anorexia, bulimia) to aid healthcare providers in early diagnosis. We tested our approach on a dataset of 2,000 tweets about eating disorders, finding that merging word embeddings with knowledge graph information enhances the predictive models' reliability. This methodology aims to assist health experts in spotting patterns indicative of mental disorders, thereby improving early detection and accurate diagnosis for personalized medicine.
Bound by the Bounty: Collaboratively Shaping Evaluation Processes for Queer AI Harms
Jul 25, 2023

Bias evaluation benchmarks and dataset and model documentation have emerged as central processes for assessing the biases and harms of artificial intelligence (AI) systems. However, these auditing processes have been criticized for their failure to integrate the knowledge of marginalized communities and consider the power dynamics between auditors and the communities. Consequently, modes of bias evaluation have been proposed that engage impacted communities in identifying and assessing the harms of AI systems (e.g., bias bounties). Even so, asking what marginalized communities want from such auditing processes has been neglected. In this paper, we ask queer communities for their positions on, and desires from, auditing processes. To this end, we organized a participatory workshop to critique and redesign bias bounties from queer perspectives. We found that when given space, the scope of feedback from workshop participants goes far beyond what bias bounties afford, with participants questioning the ownership, incentives, and efficacy of bounties. We conclude by advocating for community ownership of bounties and complementing bounties with participatory processes (e.g., co-creation).
* To appear at AIES 2023