 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Centred LLM Privacy Audits: Findings and Frictions
Mar 12, 2026Large language models (LLMs) learn statistical associations from massive training corpora and user interactions, and deployed systems can surface or infer information about individuals. Yet people lack practical ways to inspect what a model associates with their name. We report interim findings from an ongoing study and introduce LMP2, a browser-based self-audit tool. In two user studies ($N_{total}{=}458$), GPT-4o predicts 11 of 50 features for everyday people with $\ge$60\% accuracy, and participants report wanting control over LLM-generated associations despite not considering all outputs privacy violations. To validate our probing method, we evaluate eight LLMs on public figures and non-existent names, observing clear separation between stable name-conditioned associations and model defaults. Our findings also contribute to exposing a broader generative AI evaluation crisis: when outputs are probabilistic, context-dependent, and user-mediated through elicitation, what model--individual associations even include is under-specified and operationalisation relies on crafting probes and metrics that are hard to validate or compare. To move towards reliable, actionable human-centred LLM privacy audits, we identify nine frictions that emerged in our study and offer recommendations for future work and the design of human-centred LLM privacy audits.
Audit Me If You Can: Query-Efficient Active Fairness Auditing of Black-Box LLMs
Jan 06, 2026Large Language Models (LLMs) exhibit systematic biases across demographic groups. Auditing is proposed as an accountability tool for black-box LLM applications, but suffers from resource-intensive query access. We conceptualise auditing as uncertainty estimation over a target fairness metric and introduce BAFA, the Bounded Active Fairness Auditor for query-efficient auditing of black-box LLMs. BAFA maintains a version space of surrogate models consistent with queried scores and computes uncertainty intervals for fairness metrics (e.g., $Δ$ AUC) via constrained empirical risk minimisation. Active query selection narrows these intervals to reduce estimation error. We evaluate BAFA on two standard fairness dataset case studies: \textsc{CivilComments} and \textsc{Bias-in-Bios}, comparing against stratified sampling, power sampling, and ablations. BAFA achieves target error thresholds with up to 40$\times$ fewer queries than stratified sampling (e.g., 144 vs 5,956 queries at $\varepsilon=0.02$ for \textsc{CivilComments}) for tight thresholds, demonstrates substantially better performance over time, and shows lower variance across runs. These results suggest that active sampling can reduce resources needed for independent fairness auditing with LLMs, supporting continuous model evaluations.
Articulation Work and Tinkering for Fairness in Machine Learning
Jul 23, 2024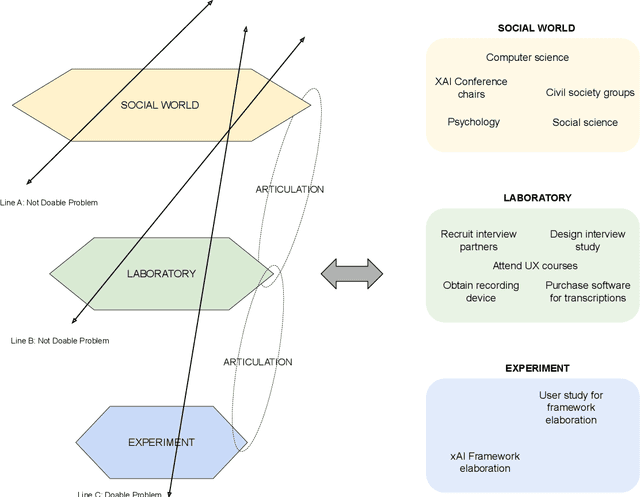
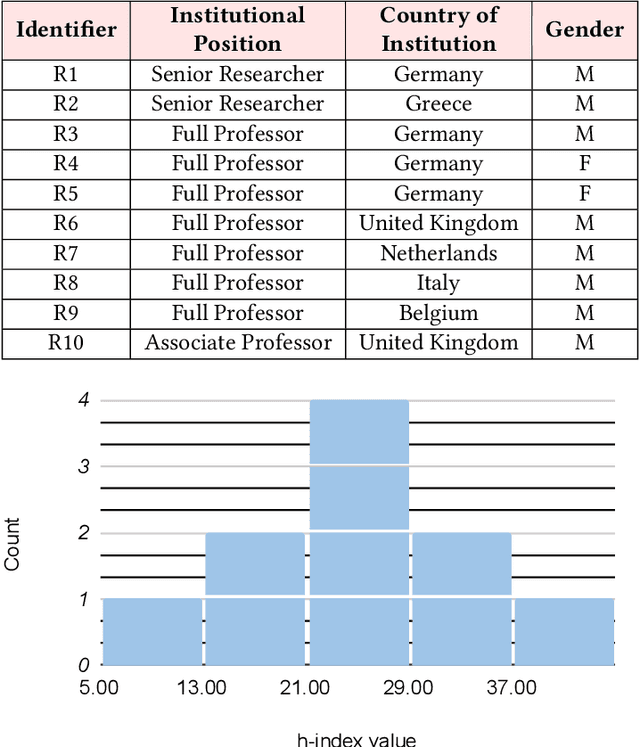

The field of fair AI aims to counter biased algorithms through computational modelling. However, it faces increasing criticism for perpetuating the use of overly technical and reductionist methods. As a result, novel approaches appear in the field to address more socially-oriented and interdisciplinary (SOI) perspectives on fair AI. In this paper, we take this dynamic as the starting point to study the tension between computer science (CS) and SOI research. By drawing on STS and CSCW theory, we position fair AI research as a matter of 'organizational alignment': what makes research 'doable' is the successful alignment of three levels of work organization (the social world, the laboratory and the experiment). Based on qualitative interviews with CS researchers, we analyze the tasks, resources, and actors required for doable research in the case of fair AI. We find that CS researchers engage with SOI to some extent, but organizational conditions, articulation work, and ambiguities of the social world constrain the doability of SOI research. Based on our findings, we identify and discuss problems for aligning CS and SOI as fair AI continues to evolve.
Silencing the Risk, Not the Whistle: A Semi-automated Text Sanitization Tool for Mitigating the Risk of Whistleblower Re-Identification
May 02, 2024Whistleblowing is essential for ensuring transparency and accountability in both public and private sectors. However, (potential) whistleblowers often fear or face retaliation, even when reporting anonymously. The specific content of their disclosures and their distinct writing style may re-identify them as the source. Legal measures, such as the EU WBD, are limited in their scope and effectiveness. Therefore, computational methods to prevent re-identification are important complementary tools for encouraging whistleblowers to come forward. However, current text sanitization tools follow a one-size-fits-all approach and take an overly limited view of anonymity. They aim to mitigate identification risk by replacing typical high-risk words (such as person names and other NE labels) and combinations thereof with placeholders. Such an approach, however, is inadequate for the whistleblowing scenario since it neglects further re-identification potential in textual features, including writing style. Therefore, we propose, implement, and evaluate a novel classification and mitigation strategy for rewriting texts that involves the whistleblower in the assessment of the risk and utility. Our prototypical tool semi-automatically evaluates risk at the word/term level and applies risk-adapted anonymization techniques to produce a grammatically disjointed yet appropriately sanitized text. We then use a LLM that we fine-tuned for paraphrasing to render this text coherent and style-neutral. We evaluate our tool's effectiveness using court cases from the ECHR and excerpts from a real-world whistleblower testimony and measure the protection against authorship attribution (AA) attacks and utility loss statistically using the popular IMDb62 movie reviews dataset. Our method can significantly reduce AA accuracy from 98.81% to 31.22%, while preserving up to 73.1% of the original content's semantics.
Tik-to-Tok: Translating Language Models One Token at a Time: An Embedding Initialization Strategy for Efficient Language Adaptation
Oct 05, 2023



Training monolingual language models for low and mid-resource languages is made challenging by limited and often inadequate pretraining data. In this study, we propose a novel model conversion strategy to address this issue, adapting high-resources monolingual language models to a new target language. By generalizing over a word translation dictionary encompassing both the source and target languages, we map tokens from the target tokenizer to semantically similar tokens from the source language tokenizer. This one-to-many token mapping improves tremendously the initialization of the embedding table for the target language. We conduct experiments to convert high-resource models to mid- and low-resource languages, namely Dutch and Frisian. These converted models achieve a new state-of-the-art performance on these languages across all sorts of downstream tasks. By reducing significantly the amount of data and time required for training state-of-the-art models, our novel model conversion strategy has the potential to benefit many languages worldwide.
Bias, diversity, and challenges to fairness in classification and automated text analysis. From libraries to AI and back
Mar 07, 2023Libraries are increasingly relying on computational methods, including methods from Artificial Intelligence (AI). This increasing usage raises concerns about the risks of AI that are currently broadly discussed in scientific literature, the media and law-making. In this article we investigate the risks surrounding bias and unfairness in AI usage in classification and automated text analysis within the context of library applications. We describe examples that show how the library community has been aware of such risks for a long time, and how it has developed and deployed countermeasures. We take a closer look at the notion of '(un)fairness' in relation to the notion of 'diversity', and we investigate a formalisation of diversity that models both inclusion and distribution. We argue that many of the unfairness problems of automated content analysis can also be regarded through the lens of diversity and the countermeasures taken to enhance diversity.
Domain Adaptive Decision Trees: Implications for Accuracy and Fairness
Feb 27, 2023
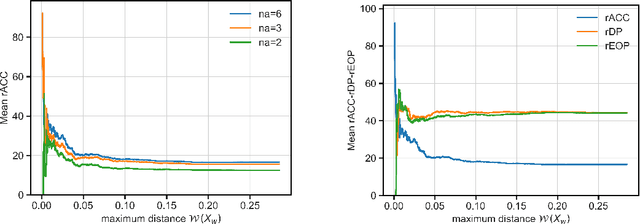
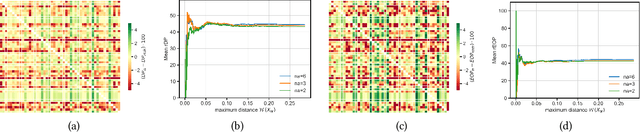
In uses of pre-trained machine learning models, it is a known issue that the target population in which the model is being deployed may not have been reflected in the source population with which the model was trained. This can result in a biased model when deployed, leading to a reduction in model performance. One risk is that, as the population changes, certain demographic groups will be under-served or otherwise disadvantaged by the model, even as they become more represented in the target population. The field of domain adaptation proposes techniques for a situation where label data for the target population does not exist, but some information about the target distribution does exist. In this paper we contribute to the domain adaptation literature by introducing domain-adaptive decision trees (DADT). We focus on decision trees given their growing popularity due to their interpretability and performance relative to other more complex models. With DADT we aim to improve the accuracy of models trained in a source domain (or training data) that differs from the target domain (or test data). We propose an in-processing step that adjusts the information gain split criterion with outside information corresponding to the distribution of the target population. We demonstrate DADT on real data and find that it improves accuracy over a standard decision tree when testing in a shifted target population. We also study the change in fairness under demographic parity and equal opportunity. Results show an improvement in fairness with the use of DADT.
How Far Can It Go?: On Intrinsic Gender Bias Mitigation for Text Classification
Jan 30, 2023



To mitigate gender bias in contextualized language models, different intrinsic mitigation strategies have been proposed, alongside many bias metrics. Considering that the end use of these language models is for downstream tasks like text classification, it is important to understand how these intrinsic bias mitigation strategies actually translate to fairness in downstream tasks and the extent of this. In this work, we design a probe to investigate the effects that some of the major intrinsic gender bias mitigation strategies have on downstream text classification tasks. We discover that instead of resolving gender bias, intrinsic mitigation techniques and metrics are able to hide it in such a way that significant gender information is retained in the embeddings. Furthermore, we show that each mitigation technique is able to hide the bias from some of the intrinsic bias measures but not all, and each intrinsic bias measure can be fooled by some mitigation techniques, but not all. We confirm experimentally, that none of the intrinsic mitigation techniques used without any other fairness intervention is able to consistently impact extrinsic bias. We recommend that intrinsic bias mitigation techniques should be combined with other fairness interventions for downstream tasks.
Political representation bias in DBpedia and Wikidata as a challenge for downstream processing
Dec 29, 2022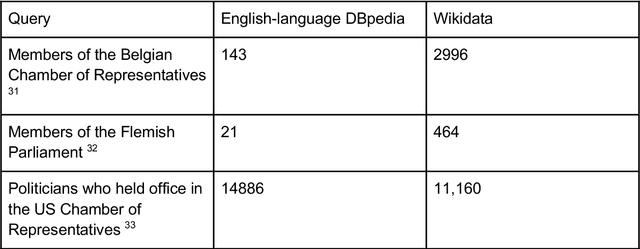
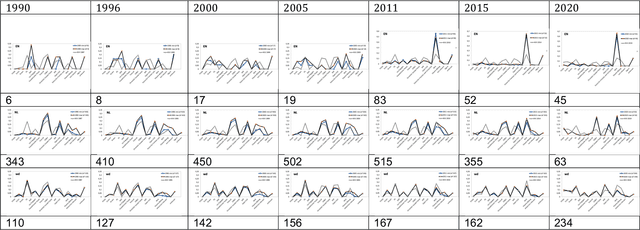

Diversity Searcher is a tool originally developed to help analyse diversity in news media texts. It relies on a form of automated content analysis and thus rests on prior assumptions and depends on certain design choices related to diversity and fairness. One such design choice is the external knowledge source(s) used. In this article, we discuss implications that these sources can have on the results of content analysis. We compare two data sources that Diversity Searcher has worked with - DBpedia and Wikidata - with respect to their ontological coverage and diversity, and describe implications for the resulting analyses of text corpora. We describe a case study of the relative over- or under-representation of Belgian political parties between 1990 and 2020 in the English-language DBpedia, the Dutch-language DBpedia, and Wikidata, and highlight the many decisions needed with regard to the design of this data analysis and the assumptions behind it, as well as implications from the results. In particular, we came across a staggering over-representation of the political right in the English-language DBpedia.
RobBERT-2022: Updating a Dutch Language Model to Account for Evolving Language Use
Nov 15, 2022Large transformer-based language models, e.g. BERT and GPT-3, outperform previous architectures on most natural language processing tasks. Such language models are first pre-trained on gigantic corpora of text and later used as base-model for finetuning on a particular task. Since the pre-training step is usually not repeated, base models are not up-to-date with the latest information. In this paper, we update RobBERT, a RoBERTa-based state-of-the-art Dutch language model, which was trained in 2019. First, the tokenizer of RobBERT is updated to include new high-frequent tokens present in the latest Dutch OSCAR corpus, e.g. corona-related words. Then we further pre-train the RobBERT model using this dataset. To evaluate if our new model is a plug-in replacement for RobBERT, we introduce two additional criteria based on concept drift of existing tokens and alignment for novel tokens.We found that for certain language tasks this update results in a significant performance increase. These results highlight the benefit of continually updating a language model to account for evolving language use.