 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBye Bye Perspective API: Lessons for Measurement Infrastructure in NLP, CSS and LLM Evaluation
Apr 28, 2026The closure of Perspective API at the end of 2026 discards what has functioned as the de facto standard for automated toxicity measurement in NLP, CSS, and LLM evaluation research. We document the structural dependence that the communities built on this single proprietary tool and discuss how this dependence caused epistemic problems that have affected - and will likely continue to affect - collective research efforts. Perspective's model was periodically updated without versioning or disclosure, its annotation structure reflected a single corporate operationalisation of a contested concept, and its scores were used simultaneously as an evaluation target and an evaluation standard. Its closure leaves behind non-updatable benchmarks, irreproducible results, and ultimately a field at risk of perpetuating these issues by turning to closed-source LLMs. We use Perspective's announced termination as an opportunity to call for an independent, valid, adaptable, and reproducible toxicity and hate speech measurement infrastructure, with the technical and governance requirements outlined in this paper.
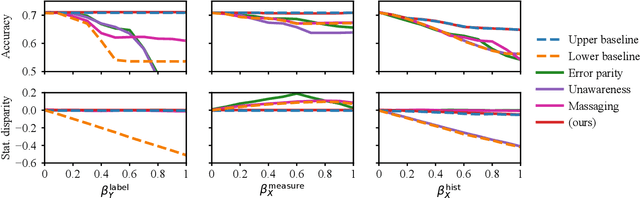
Audit Me If You Can: Query-Efficient Active Fairness Auditing of Black-Box LLMs
Jan 06, 2026Large Language Models (LLMs) exhibit systematic biases across demographic groups. Auditing is proposed as an accountability tool for black-box LLM applications, but suffers from resource-intensive query access. We conceptualise auditing as uncertainty estimation over a target fairness metric and introduce BAFA, the Bounded Active Fairness Auditor for query-efficient auditing of black-box LLMs. BAFA maintains a version space of surrogate models consistent with queried scores and computes uncertainty intervals for fairness metrics (e.g., $Δ$ AUC) via constrained empirical risk minimisation. Active query selection narrows these intervals to reduce estimation error. We evaluate BAFA on two standard fairness dataset case studies: \textsc{CivilComments} and \textsc{Bias-in-Bios}, comparing against stratified sampling, power sampling, and ablations. BAFA achieves target error thresholds with up to 40$\times$ fewer queries than stratified sampling (e.g., 144 vs 5,956 queries at $\varepsilon=0.02$ for \textsc{CivilComments}) for tight thresholds, demonstrates substantially better performance over time, and shows lower variance across runs. These results suggest that active sampling can reduce resources needed for independent fairness auditing with LLMs, supporting continuous model evaluations.
ProbLog4Fairness: A Neurosymbolic Approach to Modeling and Mitigating Bias
Nov 12, 2025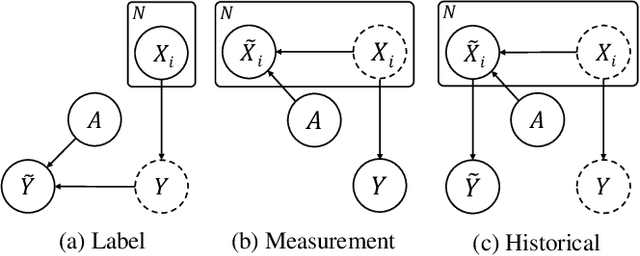


Operationalizing definitions of fairness is difficult in practice, as multiple definitions can be incompatible while each being arguably desirable. Instead, it may be easier to directly describe algorithmic bias through ad-hoc assumptions specific to a particular real-world task, e.g., based on background information on systemic biases in its context. Such assumptions can, in turn, be used to mitigate this bias during training. Yet, a framework for incorporating such assumptions that is simultaneously principled, flexible, and interpretable is currently lacking. Our approach is to formalize bias assumptions as programs in ProbLog, a probabilistic logic programming language that allows for the description of probabilistic causal relationships through logic. Neurosymbolic extensions of ProbLog then allow for easy integration of these assumptions in a neural network's training process. We propose a set of templates to express different types of bias and show the versatility of our approach on synthetic tabular datasets with known biases. Using estimates of the bias distortions present, we also succeed in mitigating algorithmic bias in real-world tabular and image data. We conclude that ProbLog4Fairness outperforms baselines due to its ability to flexibly model the relevant bias assumptions, where other methods typically uphold a fixed bias type or notion of fairness.
ChocoLlama: Lessons Learned From Teaching Llamas Dutch
Dec 10, 2024While Large Language Models (LLMs) have shown remarkable capabilities in natural language understanding and generation, their performance often lags in lower-resource, non-English languages due to biases in the training data. In this work, we explore strategies for adapting the primarily English LLMs (Llama-2 and Llama-3) to Dutch, a language spoken by 30 million people worldwide yet often underrepresented in LLM development. We collect 104GB of Dutch text ($32$B tokens) from various sources to first apply continued pretraining using low-rank adaptation (LoRA), complemented with Dutch posttraining strategies provided by prior work. For Llama-2, we consider using (i) the tokenizer of the original model, and (ii) training a new, Dutch-specific tokenizer combined with embedding reinitialization. We evaluate our adapted models, ChocoLlama-2, both on standard benchmarks and a novel Dutch benchmark, ChocoLlama-Bench. Our results demonstrate that LoRA can effectively scale for language adaptation, and that tokenizer modification with careful weight reinitialization can improve performance. Notably, Llama-3 was released during the course of this project and, upon evaluation, demonstrated superior Dutch capabilities compared to our Dutch-adapted versions of Llama-2. We hence apply the same adaptation technique to Llama-3, using its original tokenizer. While our adaptation methods enhanced Llama-2's Dutch capabilities, we found limited gains when applying the same techniques to Llama-3. This suggests that for ever improving, multilingual foundation models, language adaptation techniques may benefit more from focusing on language-specific posttraining rather than on continued pretraining. We hope this work contributes to the broader understanding of adapting LLMs to lower-resource languages, and to the development of Dutch LLMs in particular.
Trans-Tokenization and Cross-lingual Vocabulary Transfers: Language Adaptation of LLMs for Low-Resource NLP
Aug 08, 2024The development of monolingual language models for low and mid-resource languages continues to be hindered by the difficulty in sourcing high-quality training data. In this study, we present a novel cross-lingual vocabulary transfer strategy, trans-tokenization, designed to tackle this challenge and enable more efficient language adaptation. Our approach focuses on adapting a high-resource monolingual LLM to an unseen target language by initializing the token embeddings of the target language using a weighted average of semantically similar token embeddings from the source language. For this, we leverage a translation resource covering both the source and target languages. We validate our method with the Tweeties, a series of trans-tokenized LLMs, and demonstrate their competitive performance on various downstream tasks across a small but diverse set of languages. Additionally, we introduce Hydra LLMs, models with multiple swappable language modeling heads and embedding tables, which further extend the capabilities of our trans-tokenization strategy. By designing a Hydra LLM based on the multilingual model TowerInstruct, we developed a state-of-the-art machine translation model for Tatar, in a zero-shot manner, completely bypassing the need for high-quality parallel data. This breakthrough is particularly significant for low-resource languages like Tatar, where high-quality parallel data is hard to come by. By lowering the data and time requirements for training high-quality models, our trans-tokenization strategy allows for the development of LLMs for a wider range of languages, especially those with limited resources. We hope that our work will inspire further research and collaboration in the field of cross-lingual vocabulary transfer and contribute to the empowerment of languages on a global scale.
OneLove beyond the field -- A few-shot pipeline for topic and sentiment analysis during the FIFA World Cup in Qatar
Aug 05, 2024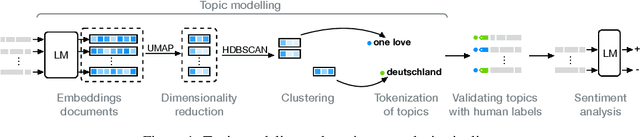

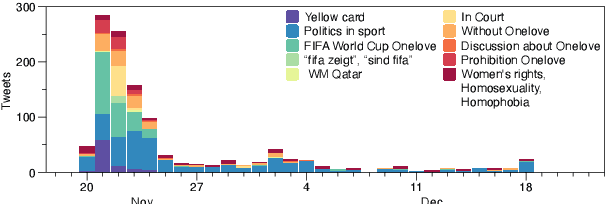
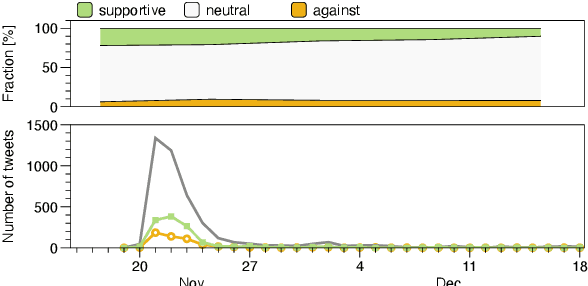
The FIFA World Cup in Qatar was discussed extensively in the news and on social media. Due to news reports with allegations of human rights violations, there were calls to boycott it. Wearing a OneLove armband was part of a planned protest activity. Controversy around the armband arose when FIFA threatened to sanction captains who wear it. To understand what topics Twitter users Tweeted about and what the opinion of German Twitter users was towards the OneLove armband, we performed an analysis of German Tweets published during the World Cup using in-context learning with LLMs. We validated the labels on human annotations. We found that Twitter users initially discussed the armband's impact, LGBT rights, and politics; after the ban, the conversation shifted towards politics in sports in general, accompanied by a subtle shift in sentiment towards neutrality. Our evaluation serves as a framework for future research to explore the impact of sports activism and evolving public sentiment. This is especially useful in settings where labeling datasets for specific opinions is unfeasible, such as when events are unfolding.
Tik-to-Tok: Translating Language Models One Token at a Time: An Embedding Initialization Strategy for Efficient Language Adaptation
Oct 05, 2023



Training monolingual language models for low and mid-resource languages is made challenging by limited and often inadequate pretraining data. In this study, we propose a novel model conversion strategy to address this issue, adapting high-resources monolingual language models to a new target language. By generalizing over a word translation dictionary encompassing both the source and target languages, we map tokens from the target tokenizer to semantically similar tokens from the source language tokenizer. This one-to-many token mapping improves tremendously the initialization of the embedding table for the target language. We conduct experiments to convert high-resource models to mid- and low-resource languages, namely Dutch and Frisian. These converted models achieve a new state-of-the-art performance on these languages across all sorts of downstream tasks. By reducing significantly the amount of data and time required for training state-of-the-art models, our novel model conversion strategy has the potential to benefit many languages worldwide.
How Far Can It Go?: On Intrinsic Gender Bias Mitigation for Text Classification
Jan 30, 2023



To mitigate gender bias in contextualized language models, different intrinsic mitigation strategies have been proposed, alongside many bias metrics. Considering that the end use of these language models is for downstream tasks like text classification, it is important to understand how these intrinsic bias mitigation strategies actually translate to fairness in downstream tasks and the extent of this. In this work, we design a probe to investigate the effects that some of the major intrinsic gender bias mitigation strategies have on downstream text classification tasks. We discover that instead of resolving gender bias, intrinsic mitigation techniques and metrics are able to hide it in such a way that significant gender information is retained in the embeddings. Furthermore, we show that each mitigation technique is able to hide the bias from some of the intrinsic bias measures but not all, and each intrinsic bias measure can be fooled by some mitigation techniques, but not all. We confirm experimentally, that none of the intrinsic mitigation techniques used without any other fairness intervention is able to consistently impact extrinsic bias. We recommend that intrinsic bias mitigation techniques should be combined with other fairness interventions for downstream tasks.
RobBERT-2022: Updating a Dutch Language Model to Account for Evolving Language Use
Nov 15, 2022Large transformer-based language models, e.g. BERT and GPT-3, outperform previous architectures on most natural language processing tasks. Such language models are first pre-trained on gigantic corpora of text and later used as base-model for finetuning on a particular task. Since the pre-training step is usually not repeated, base models are not up-to-date with the latest information. In this paper, we update RobBERT, a RoBERTa-based state-of-the-art Dutch language model, which was trained in 2019. First, the tokenizer of RobBERT is updated to include new high-frequent tokens present in the latest Dutch OSCAR corpus, e.g. corona-related words. Then we further pre-train the RobBERT model using this dataset. To evaluate if our new model is a plug-in replacement for RobBERT, we introduce two additional criteria based on concept drift of existing tokens and alignment for novel tokens.We found that for certain language tasks this update results in a significant performance increase. These results highlight the benefit of continually updating a language model to account for evolving language use.
FairDistillation: Mitigating Stereotyping in Language Models
Jul 10, 2022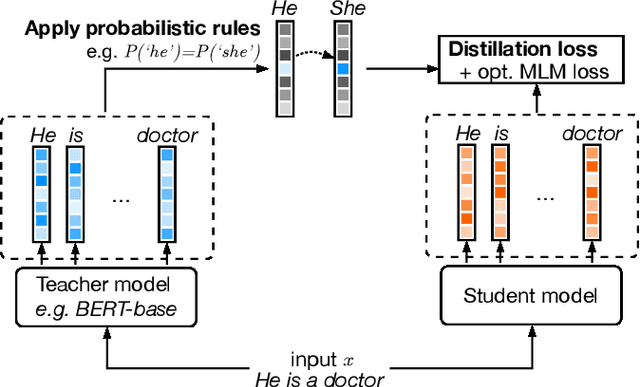


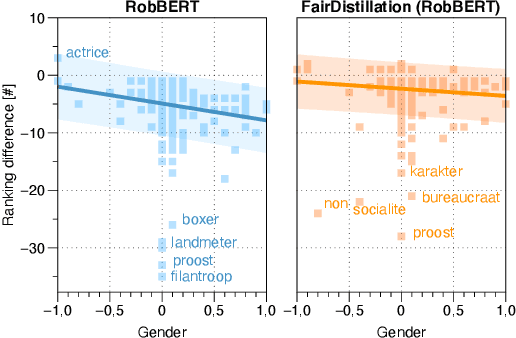
Large pre-trained language models are successfully being used in a variety of tasks, across many languages. With this ever-increasing usage, the risk of harmful side effects also rises, for example by reproducing and reinforcing stereotypes. However, detecting and mitigating these harms is difficult to do in general and becomes computationally expensive when tackling multiple languages or when considering different biases. To address this, we present FairDistillation: a cross-lingual method based on knowledge distillation to construct smaller language models while controlling for specific biases. We found that our distillation method does not negatively affect the downstream performance on most tasks and successfully mitigates stereotyping and representational harms. We demonstrate that FairDistillation can create fairer language models at a considerably lower cost than alternative approaches.