 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairFlow: An Automated Approach to Model-based Counterfactual Data Augmentation For NLP
Jul 23, 2024



Despite the evolution of language models, they continue to portray harmful societal biases and stereotypes inadvertently learned from training data. These inherent biases often result in detrimental effects in various applications. Counterfactual Data Augmentation (CDA), which seeks to balance demographic attributes in training data, has been a widely adopted approach to mitigate bias in natural language processing. However, many existing CDA approaches rely on word substitution techniques using manually compiled word-pair dictionaries. These techniques often lead to out-of-context substitutions, resulting in potential quality issues. The advancement of model-based techniques, on the other hand, has been challenged by the need for parallel training data. Works in this area resort to manually generated parallel data that are expensive to collect and are consequently limited in scale. This paper proposes FairFlow, an automated approach to generating parallel data for training counterfactual text generator models that limits the need for human intervention. Furthermore, we show that FairFlow significantly overcomes the limitations of dictionary-based word-substitution approaches whilst maintaining good performance.
Model-based Counterfactual Generator for Gender Bias Mitigation
Nov 06, 2023



Counterfactual Data Augmentation (CDA) has been one of the preferred techniques for mitigating gender bias in natural language models. CDA techniques have mostly employed word substitution based on dictionaries. Although such dictionary-based CDA techniques have been shown to significantly improve the mitigation of gender bias, in this paper, we highlight some limitations of such dictionary-based counterfactual data augmentation techniques, such as susceptibility to ungrammatical compositions, and lack of generalization outside the set of predefined dictionary words. Model-based solutions can alleviate these problems, yet the lack of qualitative parallel training data hinders development in this direction. Therefore, we propose a combination of data processing techniques and a bi-objective training regime to develop a model-based solution for generating counterfactuals to mitigate gender bias. We implemented our proposed solution and performed an empirical evaluation which shows how our model alleviates the shortcomings of dictionary-based solutions.
Text Style Transfer for Bias Mitigation using Masked Language Modeling
Jan 21, 2022

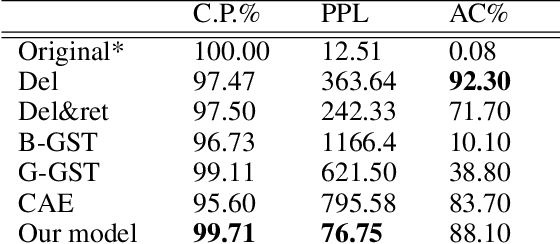
It is well known that textual data on the internet and other digital platforms contain significant levels of bias and stereotypes. Although many such texts contain stereotypes and biases that inherently exist in natural language for reasons that are not necessarily malicious, there are crucial reasons to mitigate these biases. For one, these texts are being used as training corpus to train language models for salient applications like cv-screening, search engines, and chatbots; such applications are turning out to produce discriminatory results. Also, several research findings have concluded that biased texts have significant effects on the target demographic groups. For instance, masculine-worded job advertisements tend to be less appealing to female applicants. In this paper, we present a text style transfer model that can be used to automatically debias textual data. Our style transfer model improves on the limitations of many existing style transfer techniques such as loss of content information. Our model solves such issues by combining latent content encoding with explicit keyword replacement. We will show that this technique produces better content preservation whilst maintaining good style transfer accuracy.
Measuring Fairness with Biased Rulers: A Survey on Quantifying Biases in Pretrained Language Models
Dec 14, 2021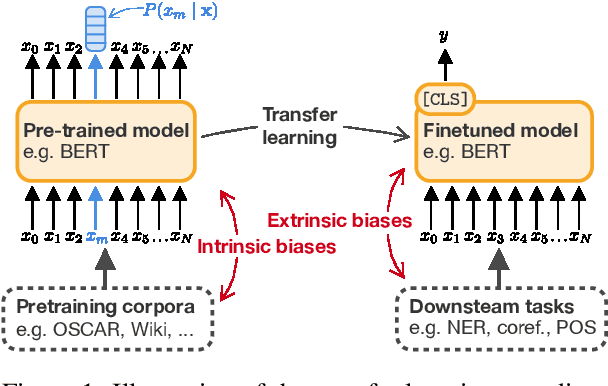

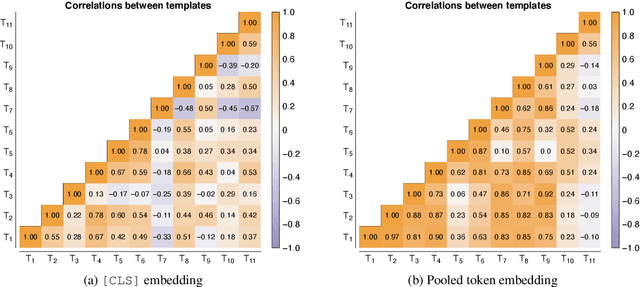

An increasing awareness of biased patterns in natural language processing resources, like BERT, has motivated many metrics to quantify `bias' and `fairness'. But comparing the results of different metrics and the works that evaluate with such metrics remains difficult, if not outright impossible. We survey the existing literature on fairness metrics for pretrained language models and experimentally evaluate compatibility, including both biases in language models as in their downstream tasks. We do this by a mixture of traditional literature survey and correlation analysis, as well as by running empirical evaluations. We find that many metrics are not compatible and highly depend on (i) templates, (ii) attribute and target seeds and (iii) the choice of embeddings. These results indicate that fairness or bias evaluation remains challenging for contextualized language models, if not at least highly subjective. To improve future comparisons and fairness evaluations, we recommend avoiding embedding-based metrics and focusing on fairness evaluations in downstream tasks.