 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEST-STD2.0: Balanced and Efficient Speech Tokenizer for Spoken Term Detection
Dec 18, 2025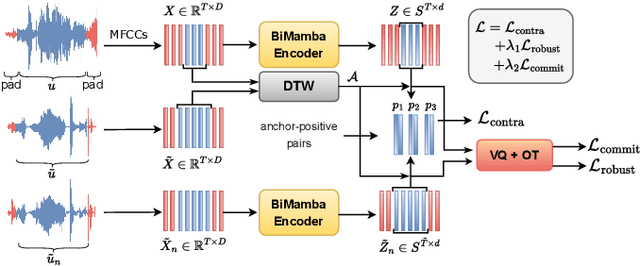
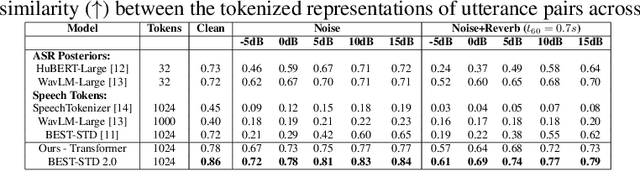
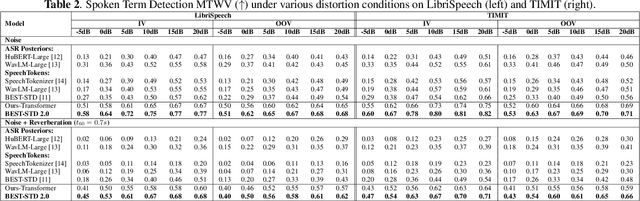
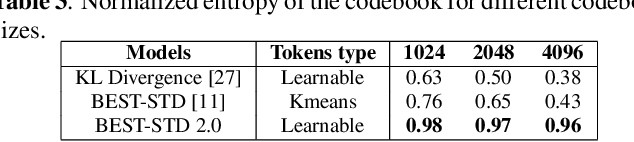
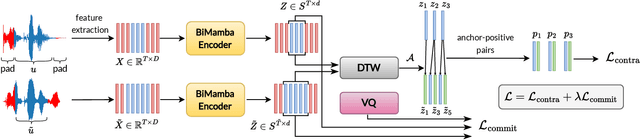
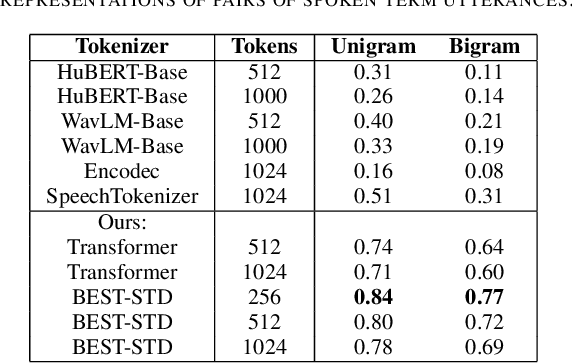
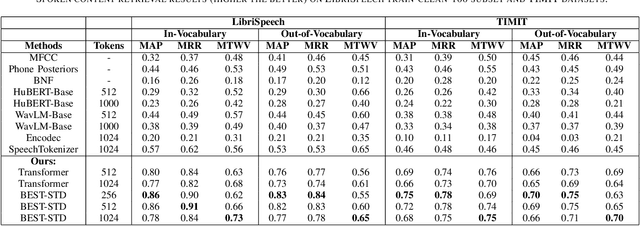
Fast and accurate spoken content retrieval is vital for applications such as voice search. Query-by-Example Spoken Term Detection (STD) involves retrieving matching segments from an audio database given a spoken query. Token-based STD systems, which use discrete speech representations, enable efficient search but struggle with robustness to noise and reverberation, and with inefficient token utilization. We address these challenges by proposing a noise and reverberation-augmented training strategy to improve tokenizer robustness. In addition, we introduce optimal transport-based regularization to ensure balanced token usage and enhance token efficiency. To further speed up retrieval, we adopt a TF-IDF-based search mechanism. Empirical evaluations demonstrate that the proposed method outperforms STD baselines across various distortion levels while maintaining high search efficiency.
BEST-STD: Bidirectional Mamba-Enhanced Speech Tokenization for Spoken Term Detection
Nov 21, 2024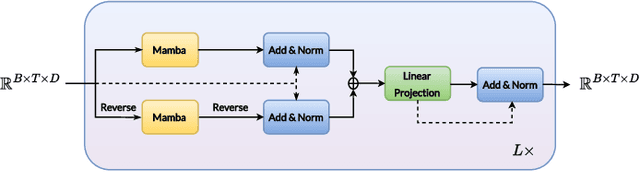
Spoken term detection (STD) is often hindered by reliance on frame-level features and the computationally intensive DTW-based template matching, limiting its practicality. To address these challenges, we propose a novel approach that encodes speech into discrete, speaker-agnostic semantic tokens. This facilitates fast retrieval using text-based search algorithms and effectively handles out-of-vocabulary terms. Our approach focuses on generating consistent token sequences across varying utterances of the same term. We also propose a bidirectional state space modeling within the Mamba encoder, trained in a self-supervised learning framework, to learn contextual frame-level features that are further encoded into discrete tokens. Our analysis shows that our speech tokens exhibit greater speaker invariance than those from existing tokenizers, making them more suitable for STD tasks. Empirical evaluation on LibriSpeech and TIMIT databases indicates that our method outperforms existing STD baselines while being more efficient.
Speaker Embeddings With Weakly Supervised Voice Activity Detection For Efficient Speaker Diarization
May 15, 2024



Current speaker diarization systems rely on an external voice activity detection model prior to speaker embedding extraction on the detected speech segments. In this paper, we establish that the attention system of a speaker embedding extractor acts as a weakly supervised internal VAD model and performs equally or better than comparable supervised VAD systems. Subsequently, speaker diarization can be performed efficiently by extracting the VAD logits and corresponding speaker embedding simultaneously, alleviating the need and computational overhead of an external VAD model. We provide an extensive analysis of the behavior of the frame-level attention system in current speaker verification models and propose a novel speaker diarization pipeline using ECAPA2 speaker embeddings for both VAD and embedding extraction. The proposed strategy gains state-of-the-art performance on the AMI, VoxConverse and DIHARD III diarization benchmarks.
ECAPA2: A Hybrid Neural Network Architecture and Training Strategy for Robust Speaker Embeddings
Jan 16, 2024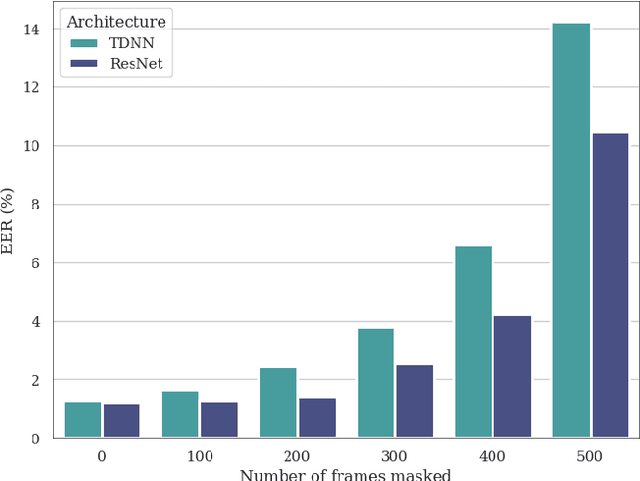
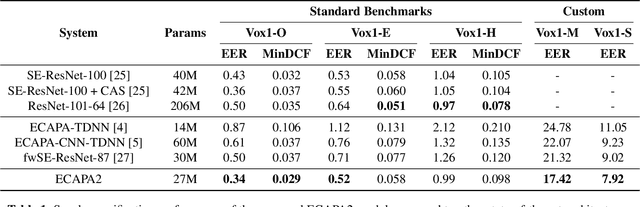
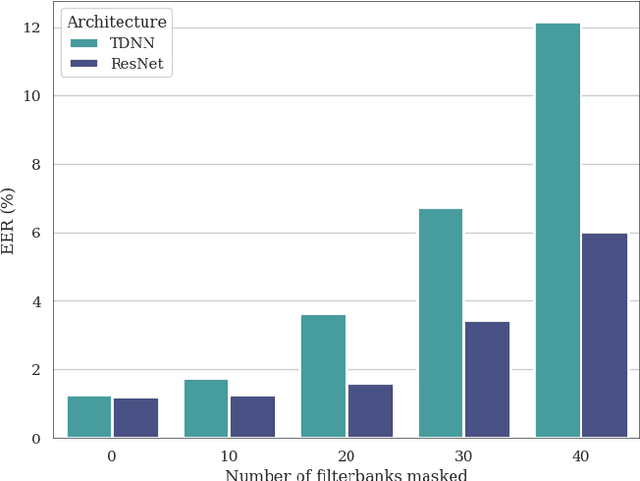
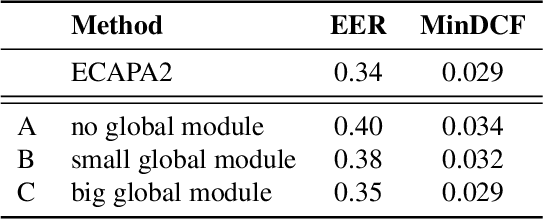
In this paper, we present ECAPA2, a novel hybrid neural network architecture and training strategy to produce robust speaker embeddings. Most speaker verification models are based on either the 1D- or 2D-convolutional operation, often manifested as Time Delay Neural Networks or ResNets, respectively. Hybrid models are relatively unexplored without an intuitive explanation what constitutes best practices in regard to its architectural choices. We motivate the proposed ECAPA2 model in this paper with an analysis of current speaker verification architectures. In addition, we propose a training strategy which makes the speaker embeddings more robust against overlapping speech and short utterance lengths. The presented ECAPA2 architecture and training strategy attains state-of-the-art performance on the VoxCeleb1 test sets with significantly less parameters than current models. Finally, we make a pre-trained model publicly available to promote research on downstream tasks.
BioLORD-2023: Semantic Textual Representations Fusing LLM and Clinical Knowledge Graph Insights
Nov 27, 2023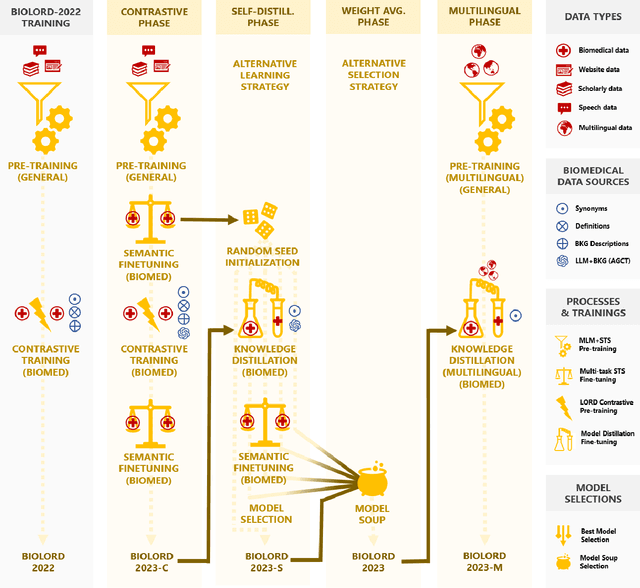
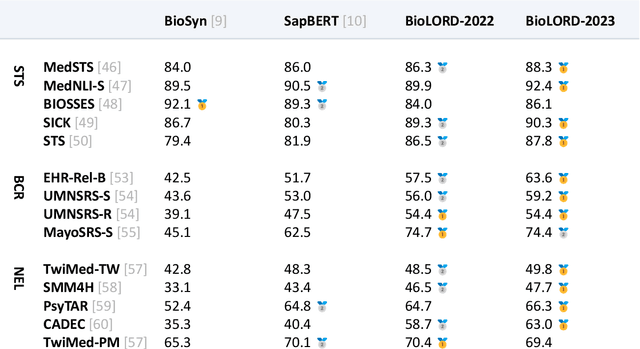

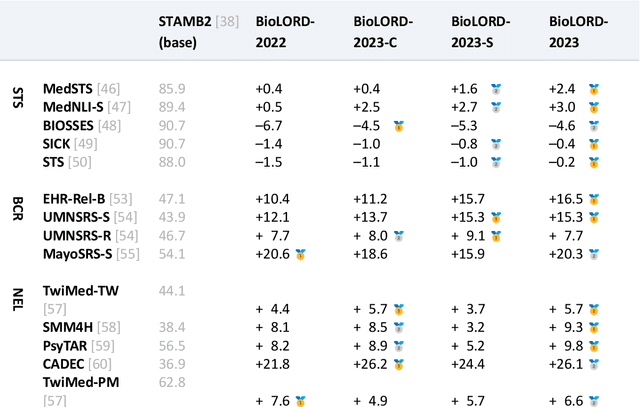
In this study, we investigate the potential of Large Language Models to complement biomedical knowledge graphs in the training of semantic models for the biomedical and clinical domains. Drawing on the wealth of the UMLS knowledge graph and harnessing cutting-edge Large Language Models, we propose a new state-of-the-art approach for obtaining high-fidelity representations of biomedical concepts and sentences, consisting of three steps: an improved contrastive learning phase, a novel self-distillation phase, and a weight averaging phase. Through rigorous evaluations via the extensive BioLORD testing suite and diverse downstream tasks, we demonstrate consistent and substantial performance improvements over the previous state of the art (e.g. +2pts on MedSTS, +2.5pts on MedNLI-S, +6.1pts on EHR-Rel-B). Besides our new state-of-the-art biomedical model for English, we also distill and release a multilingual model compatible with 50+ languages and finetuned on 7 European languages. Many clinical pipelines can benefit from our latest models. Our new multilingual model enables a range of languages to benefit from our advancements in biomedical semantic representation learning, opening a new avenue for bioinformatics researchers around the world. As a result, we hope to see BioLORD-2023 becoming a precious tool for future biomedical applications.
Tik-to-Tok: Translating Language Models One Token at a Time: An Embedding Initialization Strategy for Efficient Language Adaptation
Oct 05, 2023



Training monolingual language models for low and mid-resource languages is made challenging by limited and often inadequate pretraining data. In this study, we propose a novel model conversion strategy to address this issue, adapting high-resources monolingual language models to a new target language. By generalizing over a word translation dictionary encompassing both the source and target languages, we map tokens from the target tokenizer to semantically similar tokens from the source language tokenizer. This one-to-many token mapping improves tremendously the initialization of the embedding table for the target language. We conduct experiments to convert high-resource models to mid- and low-resource languages, namely Dutch and Frisian. These converted models achieve a new state-of-the-art performance on these languages across all sorts of downstream tasks. By reducing significantly the amount of data and time required for training state-of-the-art models, our novel model conversion strategy has the potential to benefit many languages worldwide.
Behavioral Analysis of Pathological Speaker Embeddings of Patients During Oncological Treatment of Oral Cancer
Jul 10, 2023In this paper, we analyze the behavior of speaker embeddings of patients during oral cancer treatment. First, we found that pre- and post-treatment speaker embeddings differ significantly, notifying a substantial change in voice characteristics. However, a partial recovery to pre-operative voice traits is observed after 12 months post-operation. Secondly, the same-speaker similarity at distinct treatment stages is similar to healthy speakers, indicating that the embeddings can capture characterizing features of even severely impaired speech. Finally, a speaker verification analysis signifies a stable false positive rate and variable false negative rate when combining speech samples of different treatment stages. This indicates robustness of the embeddings towards other speakers, while still capturing the changing voice characteristics during treatment. To the best of our knowledge, this is the first analysis of speaker embeddings during oral cancer treatment of patients.
Margin-Mixup: A Method for Robust Speaker Verification in Multi-Speaker Audio
Apr 07, 2023



This paper is concerned with the task of speaker verification on audio with multiple overlapping speakers. Most speaker verification systems are designed with the assumption of a single speaker being present in a given audio segment. However, in a real-world setting this assumption does not always hold. In this paper, we demonstrate that current speaker verification systems are not robust against audio with noticeable speaker overlap. To alleviate this issue, we propose margin-mixup, a simple training strategy that can easily be adopted by existing speaker verification pipelines to make the resulting speaker embeddings robust against multi-speaker audio. In contrast to other methods, margin-mixup requires no alterations to regular speaker verification architectures, while attaining better results. On our multi-speaker test set based on VoxCeleb1, the proposed margin-mixup strategy improves the EER on average with 44.4% relative to our state-of-the-art speaker verification baseline systems.
Simultaneously Learning Robust Audio Embeddings and balanced Hash codes for Query-by-Example
Nov 20, 2022Audio fingerprinting systems must efficiently and robustly identify query snippets in an extensive database. To this end, state-of-the-art systems use deep learning to generate compact audio fingerprints. These systems deploy indexing methods, which quantize fingerprints to hash codes in an unsupervised manner to expedite the search. However, these methods generate imbalanced hash codes, leading to their suboptimal performance. Therefore, we propose a self-supervised learning framework to compute fingerprints and balanced hash codes in an end-to-end manner to achieve both fast and accurate retrieval performance. We model hash codes as a balanced clustering process, which we regard as an instance of the optimal transport problem. Experimental results indicate that the proposed approach improves retrieval efficiency while preserving high accuracy, particularly at high distortion levels, compared to the competing methods. Moreover, our system is efficient and scalable in computational load and memory storage.
Attention-Based Audio Embeddings for Query-by-Example
Oct 16, 2022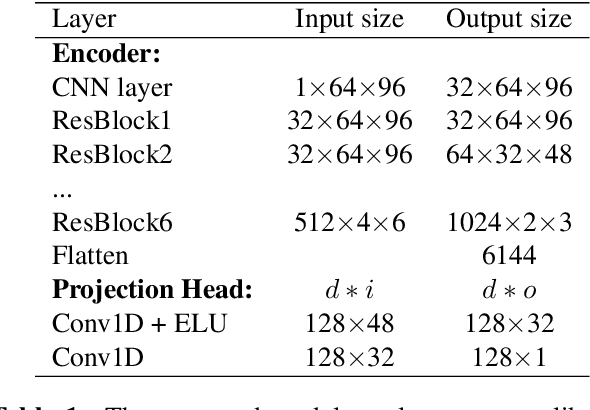


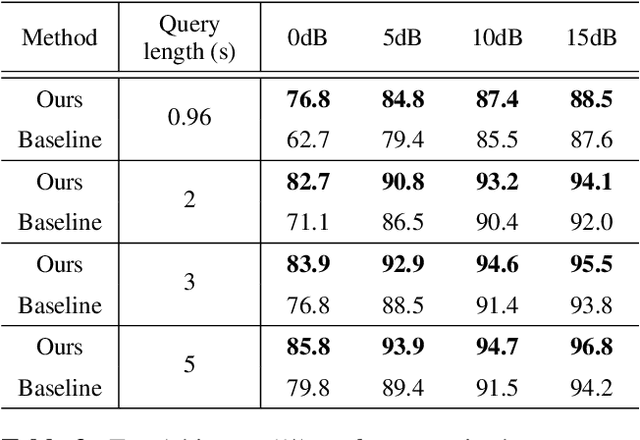
An ideal audio retrieval system efficiently and robustly recognizes a short query snippet from an extensive database. However, the performance of well-known audio fingerprinting systems falls short at high signal distortion levels. This paper presents an audio retrieval system that generates noise and reverberation robust audio fingerprints using the contrastive learning framework. Using these fingerprints, the method performs a comprehensive search to identify the query audio and precisely estimate its timestamp in the reference audio. Our framework involves training a CNN to maximize the similarity between pairs of embeddings extracted from clean audio and its corresponding distorted and time-shifted version. We employ a channel-wise spectral-temporal attention mechanism to better discriminate the audio by giving more weight to the salient spectral-temporal patches in the signal. Experimental results indicate that our system is efficient in computation and memory usage while being more accurate, particularly at higher distortion levels, than competing state-of-the-art systems and scalable to a larger database.