 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEST-STD2.0: Balanced and Efficient Speech Tokenizer for Spoken Term Detection
Dec 18, 2025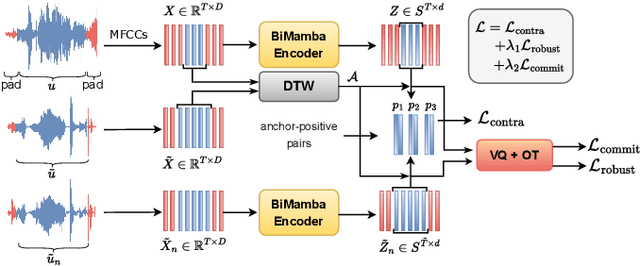
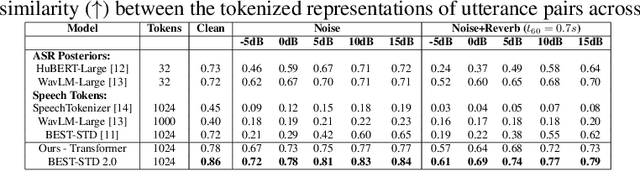
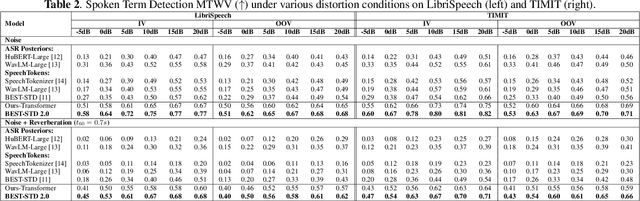
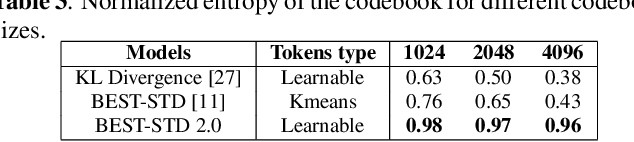
Fast and accurate spoken content retrieval is vital for applications such as voice search. Query-by-Example Spoken Term Detection (STD) involves retrieving matching segments from an audio database given a spoken query. Token-based STD systems, which use discrete speech representations, enable efficient search but struggle with robustness to noise and reverberation, and with inefficient token utilization. We address these challenges by proposing a noise and reverberation-augmented training strategy to improve tokenizer robustness. In addition, we introduce optimal transport-based regularization to ensure balanced token usage and enhance token efficiency. To further speed up retrieval, we adopt a TF-IDF-based search mechanism. Empirical evaluations demonstrate that the proposed method outperforms STD baselines across various distortion levels while maintaining high search efficiency.
BEST-STD: Bidirectional Mamba-Enhanced Speech Tokenization for Spoken Term Detection
Nov 21, 2024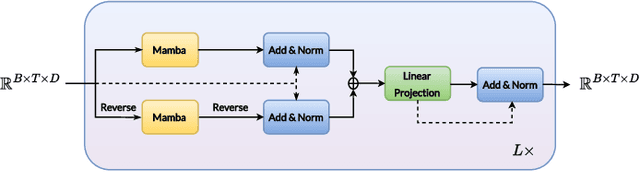
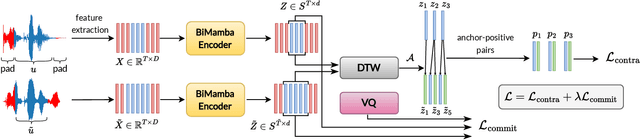
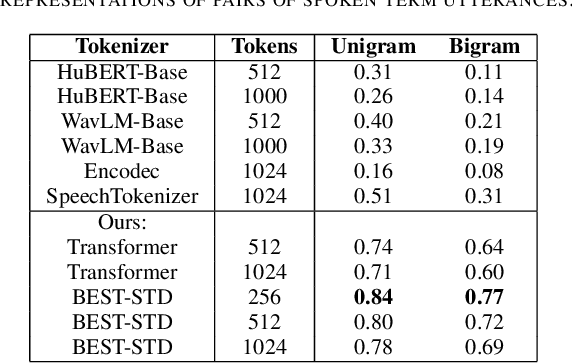
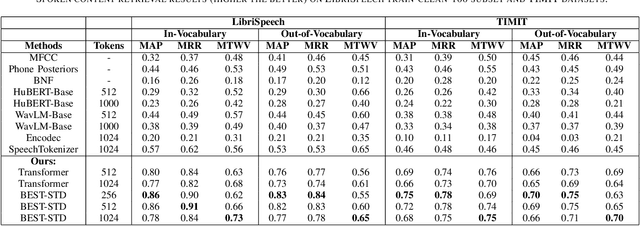
Spoken term detection (STD) is often hindered by reliance on frame-level features and the computationally intensive DTW-based template matching, limiting its practicality. To address these challenges, we propose a novel approach that encodes speech into discrete, speaker-agnostic semantic tokens. This facilitates fast retrieval using text-based search algorithms and effectively handles out-of-vocabulary terms. Our approach focuses on generating consistent token sequences across varying utterances of the same term. We also propose a bidirectional state space modeling within the Mamba encoder, trained in a self-supervised learning framework, to learn contextual frame-level features that are further encoded into discrete tokens. Our analysis shows that our speech tokens exhibit greater speaker invariance than those from existing tokenizers, making them more suitable for STD tasks. Empirical evaluation on LibriSpeech and TIMIT databases indicates that our method outperforms existing STD baselines while being more efficient.
Simultaneously Learning Robust Audio Embeddings and balanced Hash codes for Query-by-Example
Nov 20, 2022Audio fingerprinting systems must efficiently and robustly identify query snippets in an extensive database. To this end, state-of-the-art systems use deep learning to generate compact audio fingerprints. These systems deploy indexing methods, which quantize fingerprints to hash codes in an unsupervised manner to expedite the search. However, these methods generate imbalanced hash codes, leading to their suboptimal performance. Therefore, we propose a self-supervised learning framework to compute fingerprints and balanced hash codes in an end-to-end manner to achieve both fast and accurate retrieval performance. We model hash codes as a balanced clustering process, which we regard as an instance of the optimal transport problem. Experimental results indicate that the proposed approach improves retrieval efficiency while preserving high accuracy, particularly at high distortion levels, compared to the competing methods. Moreover, our system is efficient and scalable in computational load and memory storage.
Attention-Based Audio Embeddings for Query-by-Example
Oct 16, 2022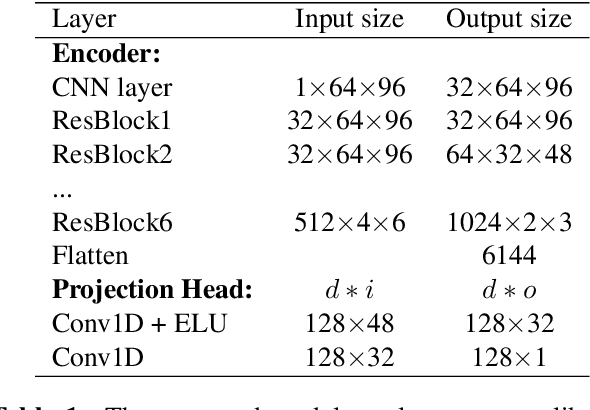


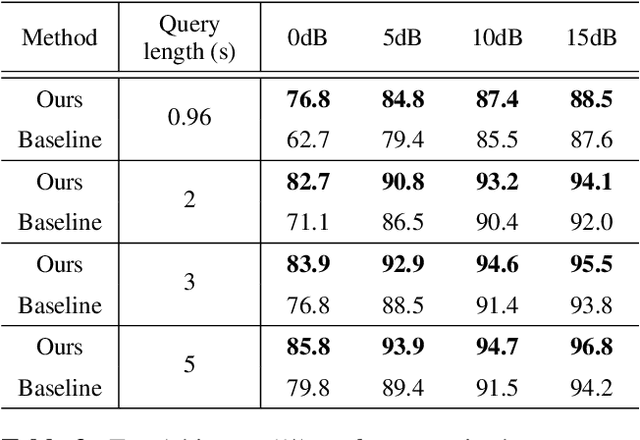
An ideal audio retrieval system efficiently and robustly recognizes a short query snippet from an extensive database. However, the performance of well-known audio fingerprinting systems falls short at high signal distortion levels. This paper presents an audio retrieval system that generates noise and reverberation robust audio fingerprints using the contrastive learning framework. Using these fingerprints, the method performs a comprehensive search to identify the query audio and precisely estimate its timestamp in the reference audio. Our framework involves training a CNN to maximize the similarity between pairs of embeddings extracted from clean audio and its corresponding distorted and time-shifted version. We employ a channel-wise spectral-temporal attention mechanism to better discriminate the audio by giving more weight to the salient spectral-temporal patches in the signal. Experimental results indicate that our system is efficient in computation and memory usage while being more accurate, particularly at higher distortion levels, than competing state-of-the-art systems and scalable to a larger database.