 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePairAlign: A Framework for Sequence Tokenization via Self-Alignment with Applications to Audio Tokenization
May 07, 2026Many operations on sensory data -- comparison, memory, retrieval, and reasoning -- are naturally expressed over discrete symbolic structures. In language this interface is given by tokens; in audio, it must be learned. Existing audio tokenizers rely on quantization, clustering, or codec reconstruction, assigning tokens locally, so sequence consistency, compactness, length control, termination, and edit similarity are rarely optimized directly. We introduce PairAlign, a framework for compact audio tokenization through sequence-level self-alignment. PairAlign treats tokenization as conditional sequence generation: an encoder maps speech to a continuous condition, and an autoregressive decoder generates tokens from BOS, learning token identity, order, length, and EOS placement. Given two content-preserving views, each view's sequence is trained to be likely under the other's representation, while unrelated examples provide competing sequences. This gives a scalable surrogate for edit-distance preservation while discouraging many-to-one collapse. PairAlign starts from VQ-style tokenization and refines it with EMA-teacher targets, cross-paired teacher forcing, prefix corruption, likelihood contrast, and length control. On 3-second speech, PairAlign learns compact, non-degenerate sequences with broad vocabulary usage and strong cross-view consistency. On TIMIT retrieval, it preserves edit-distance search while reducing archive token count by 55%. A continuous-sweep probe shows lower local overlap than a dense geometric tokenizer, but stronger length control and bounded edit trajectories under 100 ms shifts. PairAlign is a sequence-symbolic predictive learner: like JEPA-style objectives, it predicts an abstract target from another view as a learned variable-length symbolic sequence, not a continuous latent.
Automatic Detection and Analysis of Singing Mistakes for Music Pedagogy
Feb 06, 2026The advancement of machine learning in audio analysis has opened new possibilities for technology-enhanced music education. This paper introduces a framework for automatic singing mistake detection in the context of music pedagogy, supported by a newly curated dataset. The dataset comprises synchronized teacher learner vocal recordings, with annotations marking different types of mistakes made by learners. Using this dataset, we develop different deep learning models for mistake detection and benchmark them. To compare the efficacy of mistake detection systems, a new evaluation methodology is proposed. Experiments indicate that the proposed learning-based methods are superior to rule-based methods. A systematic study of errors and a cross-teacher study reveal insights into music pedagogy that can be utilised for various music applications. This work sets out new directions of research in music pedagogy. The codes and dataset are publicly available.
Learning to Discover: A Generalized Framework for Raga Identification without Forgetting
Jan 26, 2026Raga identification in Indian Art Music (IAM) remains challenging due to the presence of numerous rarely performed Ragas that are not represented in available training datasets. Traditional classification models struggle in this setting, as they assume a closed set of known categories and therefore fail to recognise or meaningfully group previously unseen Ragas. Recent works have tried categorizing unseen Ragas, but they run into a problem of catastrophic forgetting, where the knowledge of previously seen Ragas is diminished. To address this problem, we adopt a unified learning framework that leverages both labeled and unlabeled audio, enabling the model to discover coherent categories corresponding to the unseen Ragas, while retaining the knowledge of previously known ones. We test our model on benchmark Raga Identification datasets and demonstrate its performance in categorizing previously seen, unseen, and all Raga classes. The proposed approach surpasses the previous NCD-based pipeline even in discovering the unseen Raga categories, offering new insights into representation learning for IAM tasks.
Weakly Supervised Tabla Stroke Transcription via TI-SDRM: A Rhythm-Aware Lattice Rescoring Framework
Jan 13, 2026Tabla Stroke Transcription (TST) is central to the analysis of rhythmic structure in Hindustani classical music, yet remains challenging due to complex rhythmic organization and the scarcity of strongly annotated data. Existing approaches largely rely on fully supervised learning with onset-level annotations, which are costly and impractical at scale. This work addresses TST in a weakly supervised setting, using only symbolic stroke sequences without temporal alignment. We propose a framework that combines a CTC-based acoustic model with sequence-level rhythmic rescoring. The acoustic model produces a decoding lattice, which is refined using a \textbf{$T\bar{a}la$}-Independent Static--Dynamic Rhythmic Model (TI-SDRM) that integrates long-term rhythmic structure with short-term adaptive dynamics through an adaptive interpolation mechanism. We curate a new real-world tabla solo dataset and a complementary synthetic dataset, establishing the first benchmark for weakly supervised TST in Hindustani classical music. Experiments demonstrate consistent and substantial reductions in stroke error rate over acoustic-only decoding, confirming the importance of explicit rhythmic structure for accurate transcription.
Learning from Limited Labels: Transductive Graph Label Propagation for Indian Music Analysis
Jan 07, 2026Supervised machine learning frameworks rely on extensive labeled datasets for robust performance on real-world tasks. However, there is a lack of large annotated datasets in audio and music domains, as annotating such recordings is resource-intensive, laborious, and often require expert domain knowledge. In this work, we explore the use of label propagation (LP), a graph-based semi-supervised learning technique, for automatically labeling the unlabeled set in an unsupervised manner. By constructing a similarity graph over audio embeddings, we propagate limited label information from a small annotated subset to a larger unlabeled corpus in a transductive, semi-supervised setting. We apply this method to two tasks in Indian Art Music (IAM): Raga identification and Instrument classification. For both these tasks, we integrate multiple public datasets along with additional recordings we acquire from Prasar Bharati Archives to perform LP. Our experiments demonstrate that LP significantly reduces labeling overhead and produces higher-quality annotations compared to conventional baseline methods, including those based on pretrained inductive models. These results highlight the potential of graph-based semi-supervised learning to democratize data annotation and accelerate progress in music information retrieval.
* Published at Journal of Acoustical Society of India, 2025
BEST-STD2.0: Balanced and Efficient Speech Tokenizer for Spoken Term Detection
Dec 18, 2025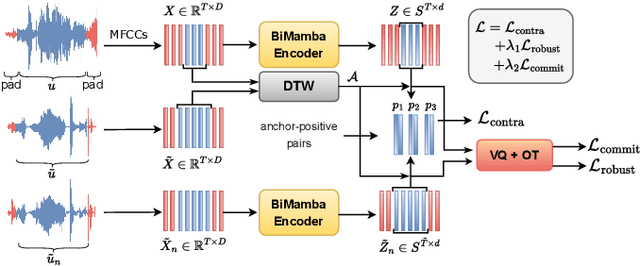
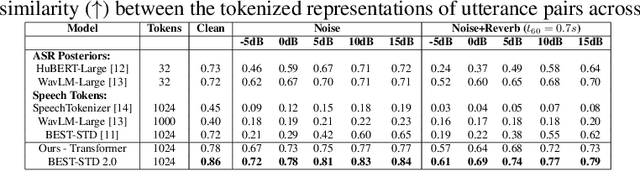
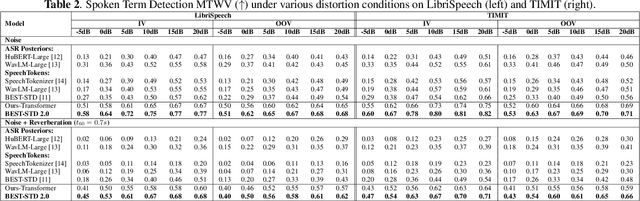
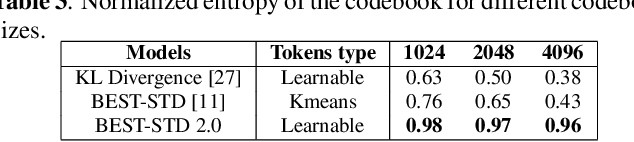
Fast and accurate spoken content retrieval is vital for applications such as voice search. Query-by-Example Spoken Term Detection (STD) involves retrieving matching segments from an audio database given a spoken query. Token-based STD systems, which use discrete speech representations, enable efficient search but struggle with robustness to noise and reverberation, and with inefficient token utilization. We address these challenges by proposing a noise and reverberation-augmented training strategy to improve tokenizer robustness. In addition, we introduce optimal transport-based regularization to ensure balanced token usage and enhance token efficiency. To further speed up retrieval, we adopt a TF-IDF-based search mechanism. Empirical evaluations demonstrate that the proposed method outperforms STD baselines across various distortion levels while maintaining high search efficiency.
Regression-based Melody Estimation with Uncertainty Quantification
May 08, 2025Existing machine learning models approach the task of melody estimation from polyphonic audio as a classification problem by discretizing the pitch values, which results in the loss of finer frequency variations present in the melody. To better capture these variations, we propose to approach this task as a regression problem. Apart from predicting only the pitch for a particular region in the audio, we also predict its uncertainty to enhance the trustworthiness of the model. To perform regression-based melody estimation, we propose three different methods that use histogram representation to model the pitch values. Such a representation requires the support range of the histogram to be continuous. The first two methods address the abrupt discontinuity between unvoiced and voiced frequency ranges by mapping them to a continuous range. The third method reformulates melody estimation as a fully Bayesian task, modeling voicing detection as a classification problem, and voiced pitch estimation as a regression problem. Additionally, we introduce a novel method to estimate the uncertainty from the histogram representation that correlates well with the deviation of the mean of the predicted distribution from the ground truth. Experimental results demonstrate that reformulating melody estimation as a regression problem significantly improves the performance over classification-based approaches. Comparing the proposed methods with a state-of-the-art regression model, it is observed that the Bayesian method performs the best at estimating both the melody and its associated uncertainty.
Recognizing Ornaments in Vocal Indian Art Music with Active Annotation
May 07, 2025Ornamentations, embellishments, or microtonal inflections are essential to melodic expression across many musical traditions, adding depth, nuance, and emotional impact to performances. Recognizing ornamentations in singing voices is key to MIR, with potential applications in music pedagogy, singer identification, genre classification, and controlled singing voice generation. However, the lack of annotated datasets and specialized modeling approaches remains a major obstacle for progress in this research area. In this work, we introduce R\=aga Ornamentation Detection (ROD), a novel dataset comprising Indian classical music recordings curated by expert musicians. The dataset is annotated using a custom Human-in-the-Loop tool for six vocal ornaments marked as event-based labels. Using this dataset, we develop an ornamentation detection model based on deep time-series analysis, preserving ornament boundaries during the chunking of long audio recordings. We conduct experiments using different train-test configurations within the ROD dataset and also evaluate our approach on a separate, manually annotated dataset of Indian classical concert recordings. Our experimental results support the superior performance of our proposed approach over the baseline CRNN.
Meta-learning-based percussion transcription and $t\bar{a}la$ identification from low-resource audio
Jan 08, 2025



This study introduces a meta-learning-based approach for low-resource Tabla Stroke Transcription (TST) and $t\bar{a}la$ identification in Hindustani classical music. Using Model-Agnostic Meta-Learning (MAML), we address the challenge of limited annotated datasets, enabling rapid adaptation to new tasks with minimal data. The method is validated across various datasets, including tabla solo and concert recordings, demonstrating robustness in polyphonic audio scenarios. We propose two novel $t\bar{a}la$ identification techniques based on stroke sequences and rhythmic patterns. Additionally, the approach proves effective for Automatic Drum Transcription (ADT), showcasing its flexibility for Indian and Western percussion music. Experimental results show that the proposed method outperforms existing techniques in low-resource settings, significantly contributing to music transcription and studying musical traditions through computational tools.
Dementia Detection using Multi-modal Methods on Audio Data
Dec 31, 2024


Dementia is a neurodegenerative disease that causes gradual cognitive impairment, which is very common in the world and undergoes a lot of research every year to prevent and cure it. It severely impacts the patient's ability to remember events and communicate clearly, where most variations of it have no known cure, but early detection can help alleviate symptoms before they become worse. One of the main symptoms of dementia is difficulty in expressing ideas through speech. This paper attempts to talk about a model developed to predict the onset of the disease using audio recordings from patients. An ASR-based model was developed that generates transcripts from the audio files using Whisper model and then applies RoBERTa regression model to generate an MMSE score for the patient. This score can be used to predict the extent to which the cognitive ability of a patient has been affected. We use the PROCESS_V1 dataset for this task, which is introduced through the PROCESS Grand Challenge 2025. The model achieved an RMSE score of 2.6911 which is around 10 percent lower than the described baseline.