 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEST-STD: Bidirectional Mamba-Enhanced Speech Tokenization for Spoken Term Detection
Paper and Code
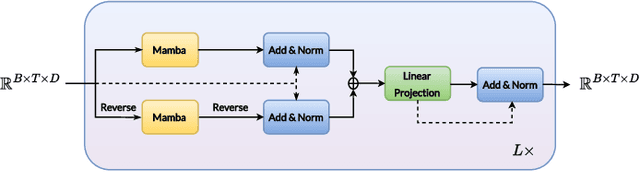
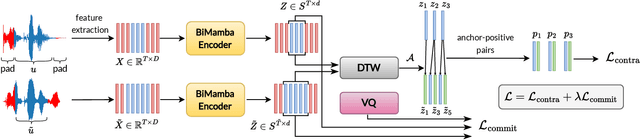
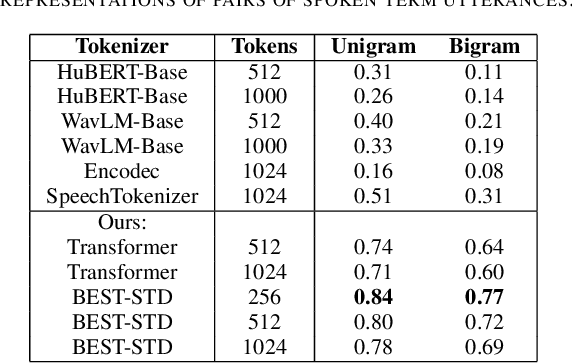
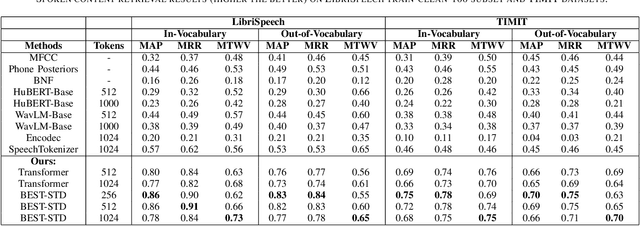
Spoken term detection (STD) is often hindered by reliance on frame-level features and the computationally intensive DTW-based template matching, limiting its practicality. To address these challenges, we propose a novel approach that encodes speech into discrete, speaker-agnostic semantic tokens. This facilitates fast retrieval using text-based search algorithms and effectively handles out-of-vocabulary terms. Our approach focuses on generating consistent token sequences across varying utterances of the same term. We also propose a bidirectional state space modeling within the Mamba encoder, trained in a self-supervised learning framework, to learn contextual frame-level features that are further encoded into discrete tokens. Our analysis shows that our speech tokens exhibit greater speaker invariance than those from existing tokenizers, making them more suitable for STD tasks. Empirical evaluation on LibriSpeech and TIMIT databases indicates that our method outperforms existing STD baselines while being more efficient.