 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive singing melody extraction based on active adaptation
Paper and Code
Feb 12, 2024


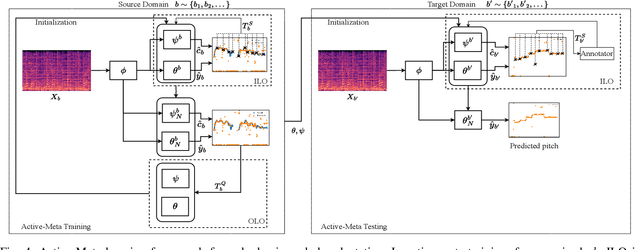
Extraction of predominant pitch from polyphonic audio is one of the fundamental tasks in the field of music information retrieval and computational musicology. To accomplish this task using machine learning, a large amount of labeled audio data is required to train the model. However, a classical model pre-trained on data from one domain (source), e.g., songs of a particular singer or genre, may not perform comparatively well in extracting melody from other domains (target). The performance of such models can be boosted by adapting the model using very little annotated data from the target domain. In this work, we propose an efficient interactive melody adaptation method. Our method selects the regions in the target audio that require human annotation using a confidence criterion based on normalized true class probability. The annotations are used by the model to adapt itself to the target domain using meta-learning. Our method also provides a novel meta-learning approach that handles class imbalance, i.e., a few representative samples from a few classes are available for adaptation in the target domain. Experimental results show that the proposed method outperforms other adaptive melody extraction baselines. The proposed method is model-agnostic and hence can be applied to other non-adaptive melody extraction models to boost their performance. Also, we released a Hindustani Alankaar and Raga (HAR) dataset containing 523 audio files of about 6.86 hours of duration intended for singing melody extraction tasks.