 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBioLORD-2023: Semantic Textual Representations Fusing LLM and Clinical Knowledge Graph Insights
Paper and Code
Nov 27, 2023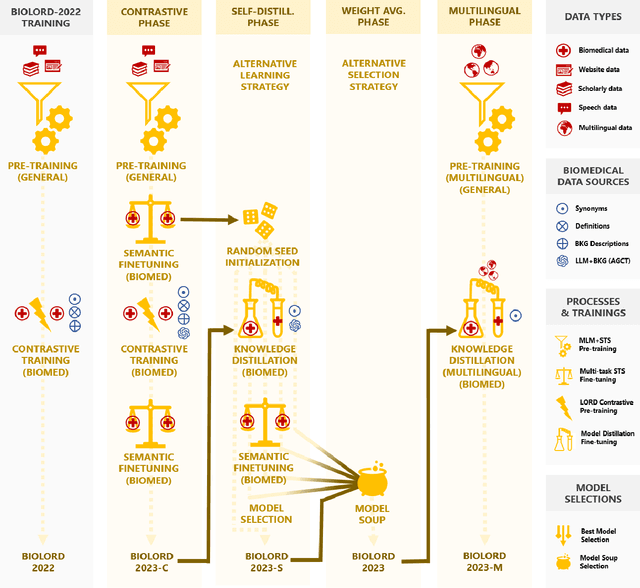
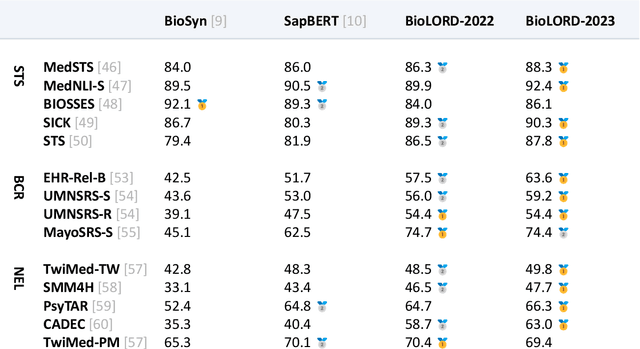

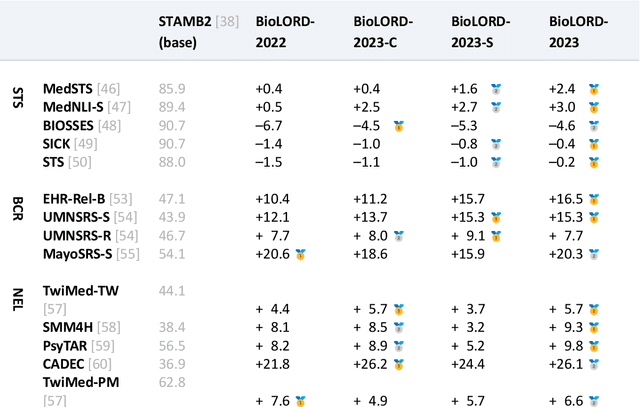
In this study, we investigate the potential of Large Language Models to complement biomedical knowledge graphs in the training of semantic models for the biomedical and clinical domains. Drawing on the wealth of the UMLS knowledge graph and harnessing cutting-edge Large Language Models, we propose a new state-of-the-art approach for obtaining high-fidelity representations of biomedical concepts and sentences, consisting of three steps: an improved contrastive learning phase, a novel self-distillation phase, and a weight averaging phase. Through rigorous evaluations via the extensive BioLORD testing suite and diverse downstream tasks, we demonstrate consistent and substantial performance improvements over the previous state of the art (e.g. +2pts on MedSTS, +2.5pts on MedNLI-S, +6.1pts on EHR-Rel-B). Besides our new state-of-the-art biomedical model for English, we also distill and release a multilingual model compatible with 50+ languages and finetuned on 7 European languages. Many clinical pipelines can benefit from our latest models. Our new multilingual model enables a range of languages to benefit from our advancements in biomedical semantic representation learning, opening a new avenue for bioinformatics researchers around the world. As a result, we hope to see BioLORD-2023 becoming a precious tool for future biomedical applications.