 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAT-Bench: A Comprehensive Benchmark for Text Anonymization
Feb 13, 2026Data containing personal information is increasingly used to train, fine-tune, or query Large Language Models (LLMs). Text is typically scrubbed of identifying information prior to use, often with tools such as Microsoft's Presidio or Anthropic's PII purifier. These tools have traditionally been evaluated on their ability to remove specific identifiers (e.g., names), yet their effectiveness at preventing re-identification remains unclear. We introduce RAT-Bench, a comprehensive benchmark for text anonymization tools based on re-identification risk. Using U.S. demographic statistics, we generate synthetic text containing various direct and indirect identifiers across domains, languages, and difficulty levels. We evaluate a range of NER- and LLM-based text anonymization tools and, based on the attributes an LLM-based attacker is able to correctly infer from the anonymized text, we report the risk of re-identification in the U.S. population, while properly accounting for the disparate impact of identifiers. We find that, while capabilities vary widely, even the best tools are far from perfect in particular when direct identifiers are not written in standard ways and when indirect identifiers enable re-identification. Overall we find LLM-based anonymizers, including new iterative anonymizers, to provide a better privacy-utility trade-off albeit at a higher computational cost. Importantly, we also find them to work well across languages. We conclude with recommendations for future anonymization tools and will release the benchmark and encourage community efforts to expand it, in particular to other geographies.
Strong Membership Inference Attacks on Massive Datasets and (Moderately) Large Language Models
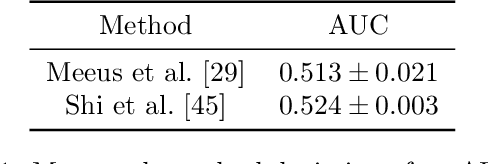
May 24, 2025State-of-the-art membership inference attacks (MIAs) typically require training many reference models, making it difficult to scale these attacks to large pre-trained language models (LLMs). As a result, prior research has either relied on weaker attacks that avoid training reference models (e.g., fine-tuning attacks), or on stronger attacks applied to small-scale models and datasets. However, weaker attacks have been shown to be brittle - achieving close-to-arbitrary success - and insights from strong attacks in simplified settings do not translate to today's LLMs. These challenges have prompted an important question: are the limitations observed in prior work due to attack design choices, or are MIAs fundamentally ineffective on LLMs? We address this question by scaling LiRA - one of the strongest MIAs - to GPT-2 architectures ranging from 10M to 1B parameters, training reference models on over 20B tokens from the C4 dataset. Our results advance the understanding of MIAs on LLMs in three key ways: (1) strong MIAs can succeed on pre-trained LLMs; (2) their effectiveness, however, remains limited (e.g., AUC<0.7) in practical settings; and, (3) the relationship between MIA success and related privacy metrics is not as straightforward as prior work has suggested.
Alignment Under Pressure: The Case for Informed Adversaries When Evaluating LLM Defenses
May 21, 2025
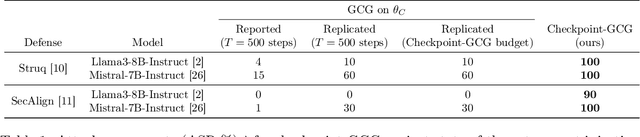
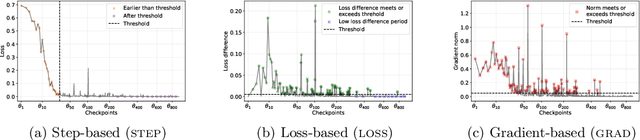

Large language models (LLMs) are rapidly deployed in real-world applications ranging from chatbots to agentic systems. Alignment is one of the main approaches used to defend against attacks such as prompt injection and jailbreaks. Recent defenses report near-zero Attack Success Rates (ASR) even against Greedy Coordinate Gradient (GCG), a white-box attack that generates adversarial suffixes to induce attacker-desired outputs. However, this search space over discrete tokens is extremely large, making the task of finding successful attacks difficult. GCG has, for instance, been shown to converge to local minima, making it sensitive to initialization choices. In this paper, we assess the future-proof robustness of these defenses using a more informed threat model: attackers who have access to some information about the alignment process. Specifically, we propose an informed white-box attack leveraging the intermediate model checkpoints to initialize GCG, with each checkpoint acting as a stepping stone for the next one. We show this approach to be highly effective across state-of-the-art (SOTA) defenses and models. We further show our informed initialization to outperform other initialization methods and show a gradient-informed checkpoint selection strategy to greatly improve attack performance and efficiency. Importantly, we also show our method to successfully find universal adversarial suffixes -- single suffixes effective across diverse inputs. Our results show that, contrary to previous beliefs, effective adversarial suffixes do exist against SOTA alignment-based defenses, that these can be found by existing attack methods when adversaries exploit alignment knowledge, and that even universal suffixes exist. Taken together, our results highlight the brittleness of current alignment-based methods and the need to consider stronger threat models when testing the safety of LLMs.
The Canary's Echo: Auditing Privacy Risks of LLM-Generated Synthetic Text
Feb 19, 2025



How much information about training samples can be gleaned from synthetic data generated by Large Language Models (LLMs)? Overlooking the subtleties of information flow in synthetic data generation pipelines can lead to a false sense of privacy. In this paper, we design membership inference attacks (MIAs) that target data used to fine-tune pre-trained LLMs that are then used to synthesize data, particularly when the adversary does not have access to the fine-tuned model but only to the synthetic data. We show that such data-based MIAs do significantly better than a random guess, meaning that synthetic data leaks information about the training data. Further, we find that canaries crafted to maximize vulnerability to model-based MIAs are sub-optimal for privacy auditing when only synthetic data is released. Such out-of-distribution canaries have limited influence on the model's output when prompted to generate useful, in-distribution synthetic data, which drastically reduces their vulnerability. To tackle this problem, we leverage the mechanics of auto-regressive models to design canaries with an in-distribution prefix and a high-perplexity suffix that leave detectable traces in synthetic data. This enhances the power of data-based MIAs and provides a better assessment of the privacy risks of releasing synthetic data generated by LLMs.
ChocoLlama: Lessons Learned From Teaching Llamas Dutch
Dec 10, 2024While Large Language Models (LLMs) have shown remarkable capabilities in natural language understanding and generation, their performance often lags in lower-resource, non-English languages due to biases in the training data. In this work, we explore strategies for adapting the primarily English LLMs (Llama-2 and Llama-3) to Dutch, a language spoken by 30 million people worldwide yet often underrepresented in LLM development. We collect 104GB of Dutch text ($32$B tokens) from various sources to first apply continued pretraining using low-rank adaptation (LoRA), complemented with Dutch posttraining strategies provided by prior work. For Llama-2, we consider using (i) the tokenizer of the original model, and (ii) training a new, Dutch-specific tokenizer combined with embedding reinitialization. We evaluate our adapted models, ChocoLlama-2, both on standard benchmarks and a novel Dutch benchmark, ChocoLlama-Bench. Our results demonstrate that LoRA can effectively scale for language adaptation, and that tokenizer modification with careful weight reinitialization can improve performance. Notably, Llama-3 was released during the course of this project and, upon evaluation, demonstrated superior Dutch capabilities compared to our Dutch-adapted versions of Llama-2. We hence apply the same adaptation technique to Llama-3, using its original tokenizer. While our adaptation methods enhanced Llama-2's Dutch capabilities, we found limited gains when applying the same techniques to Llama-3. This suggests that for ever improving, multilingual foundation models, language adaptation techniques may benefit more from focusing on language-specific posttraining rather than on continued pretraining. We hope this work contributes to the broader understanding of adapting LLMs to lower-resource languages, and to the development of Dutch LLMs in particular.
Inherent Challenges of Post-Hoc Membership Inference for Large Language Models
Jun 25, 2024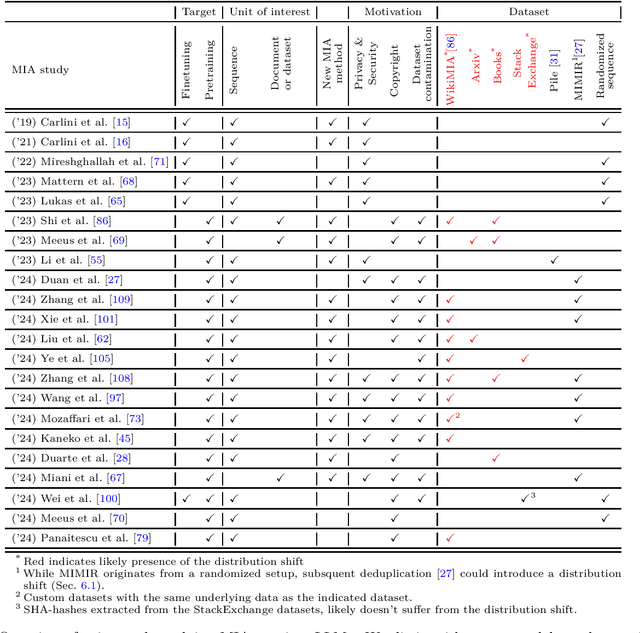
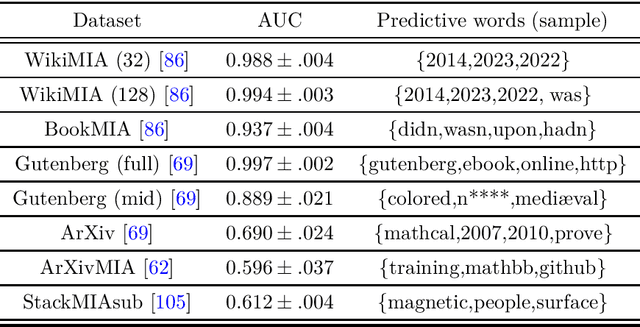
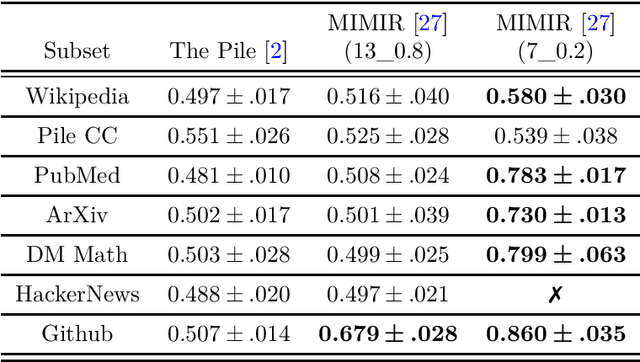
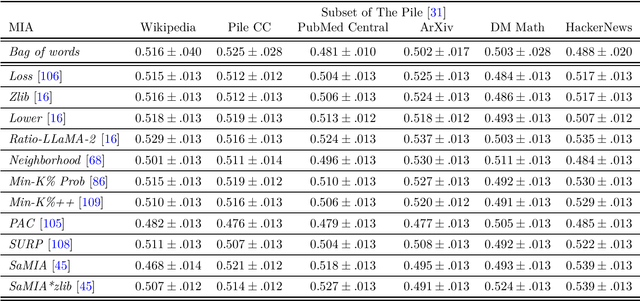
Large Language Models (LLMs) are often trained on vast amounts of undisclosed data, motivating the development of post-hoc Membership Inference Attacks (MIAs) to gain insight into their training data composition. However, in this paper, we identify inherent challenges in post-hoc MIA evaluation due to potential distribution shifts between collected member and non-member datasets. Using a simple bag-of-words classifier, we demonstrate that datasets used in recent post-hoc MIAs suffer from significant distribution shifts, in some cases achieving near-perfect distinction between members and non-members. This implies that previously reported high MIA performance may be largely attributable to these shifts rather than model memorization. We confirm that randomized, controlled setups eliminate such shifts and thus enable the development and fair evaluation of new MIAs. However, we note that such randomized setups are rarely available for the latest LLMs, making post-hoc data collection still required to infer membership for real-world LLMs. As a potential solution, we propose a Regression Discontinuity Design (RDD) approach for post-hoc data collection, which substantially mitigates distribution shifts. Evaluating various MIA methods on this RDD setup yields performance barely above random guessing, in stark contrast to previously reported results. Overall, our findings highlight the challenges in accurately measuring LLM memorization and the need for careful experimental design in (post-hoc) membership inference tasks.
Mosaic Memory: Fuzzy Duplication in Copyright Traps for Large Language Models
May 24, 2024
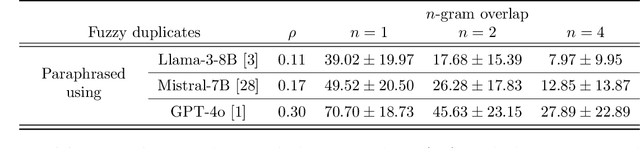
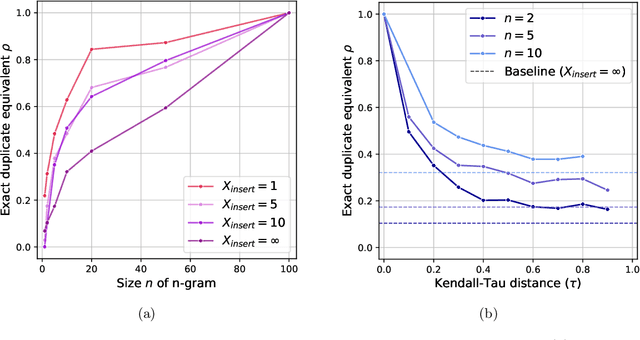
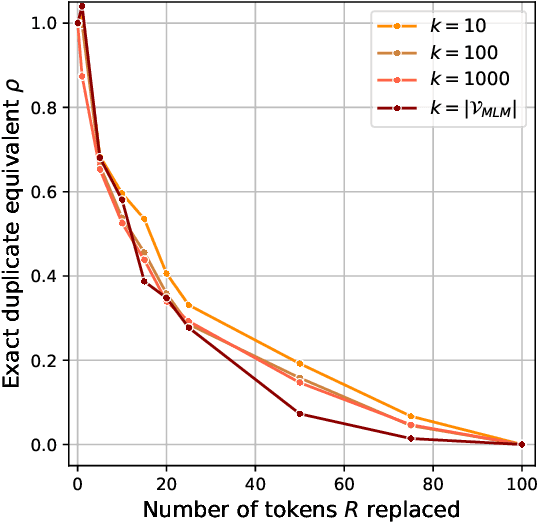
The immense datasets used to develop Large Language Models (LLMs) often include copyright-protected content, typically without the content creator's consent. Copyright traps have been proposed to be injected into the original content, improving content detectability in newly released LLMs. Traps, however, rely on the exact duplication of a unique text sequence, leaving them vulnerable to commonly deployed data deduplication techniques. We here propose the generation of fuzzy copyright traps, featuring slight modifications across duplication. When injected in the fine-tuning data of a 1.3B LLM, we show fuzzy trap sequences to be memorized nearly as well as exact duplicates. Specifically, the Membership Inference Attack (MIA) ROC AUC only drops from 0.90 to 0.87 when 4 tokens are replaced across the fuzzy duplicates. We also find that selecting replacement positions to minimize the exact overlap between fuzzy duplicates leads to similar memorization, while making fuzzy duplicates highly unlikely to be removed by any deduplication process. Lastly, we argue that the fact that LLMs memorize across fuzzy duplicates challenges the study of LLM memorization relying on naturally occurring duplicates. Indeed, we find that the commonly used training dataset, The Pile, contains significant amounts of fuzzy duplicates. This introduces a previously unexplored confounding factor in post-hoc studies of LLM memorization, and questions the effectiveness of (exact) data deduplication as a privacy protection technique.
Lost in the Averages: A New Specific Setup to Evaluate Membership Inference Attacks Against Machine Learning Models
May 24, 2024


Membership Inference Attacks (MIAs) are widely used to evaluate the propensity of a machine learning (ML) model to memorize an individual record and the privacy risk releasing the model poses. MIAs are commonly evaluated similarly to ML models: the MIA is performed on a test set of models trained on datasets unseen during training, which are sampled from a larger pool, $D_{eval}$. The MIA is evaluated across all datasets in this test set, and is thus evaluated across the distribution of samples from $D_{eval}$. While this was a natural extension of ML evaluation to MIAs, recent work has shown that a record's risk heavily depends on its specific dataset. For example, outliers are particularly vulnerable, yet an outlier in one dataset may not be one in another. The sources of randomness currently used to evaluate MIAs may thus lead to inaccurate individual privacy risk estimates. We propose a new, specific evaluation setup for MIAs against ML models, using weight initialization as the sole source of randomness. This allows us to accurately evaluate the risk associated with the release of a model trained on a specific dataset. Using SOTA MIAs, we empirically show that the risk estimates given by the current setup lead to many records being misclassified as low risk. We derive theoretical results which, combined with empirical evidence, suggest that the risk calculated in the current setup is an average of the risks specific to each sampled dataset, validating our use of weight initialization as the only source of randomness. Finally, we consider an MIA with a stronger adversary leveraging information about the target dataset to infer membership. Taken together, our results show that current MIA evaluation is averaging the risk across datasets leading to inaccurate risk estimates, and the risk posed by attacks leveraging information about the target dataset to be potentially underestimated.
Copyright Traps for Large Language Models
Feb 14, 2024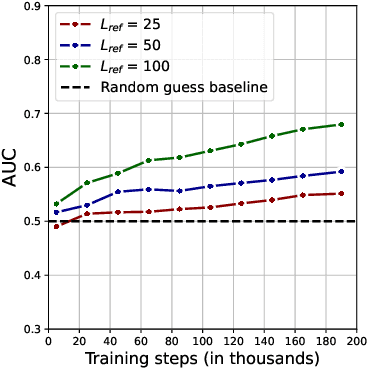
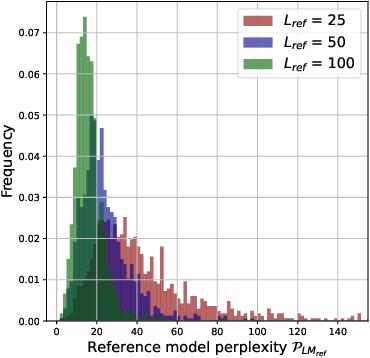
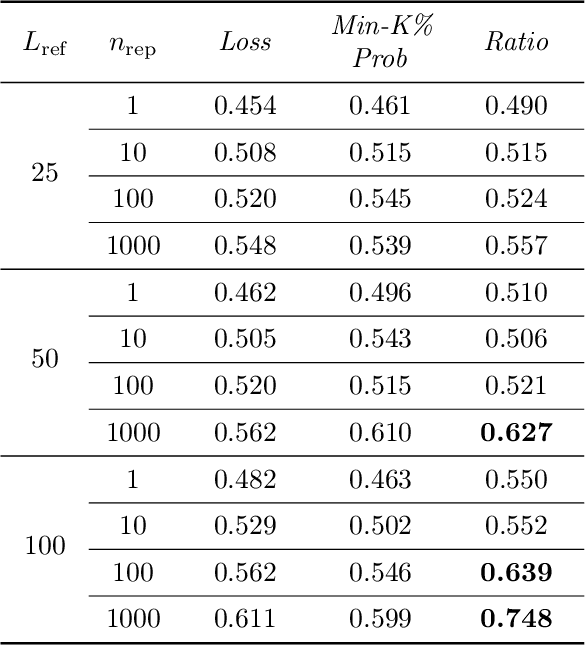
Questions of fair use of copyright-protected content to train Large Language Models (LLMs) are being very actively debated. Document-level inference has been proposed as a new task: inferring from black-box access to the trained model whether a piece of content has been seen during training. SOTA methods however rely on naturally occurring memorization of (part of) the content. While very effective against models that memorize a lot, we hypothesize--and later confirm--that they will not work against models that do not naturally memorize, e.g. medium-size 1B models. We here propose to use copyright traps, the inclusion of fictitious entries in original content, to detect the use of copyrighted materials in LLMs with a focus on models where memorization does not naturally occur. We carefully design an experimental setup, randomly inserting traps into original content (books) and train a 1.3B LLM. We first validate that the use of content in our target model would be undetectable using existing methods. We then show, contrary to intuition, that even medium-length trap sentences repeated a significant number of times (100) are not detectable using existing methods. However, we show that longer sequences repeated a large number of times can be reliably detected (AUC=0.75) and used as copyright traps. We further improve these results by studying how the number of times a sequence is seen improves detectability, how sequences with higher perplexity tend to be memorized more, and how taking context into account further improves detectability.
Did the Neurons Read your Book? Document-level Membership Inference for Large Language Models
Oct 23, 2023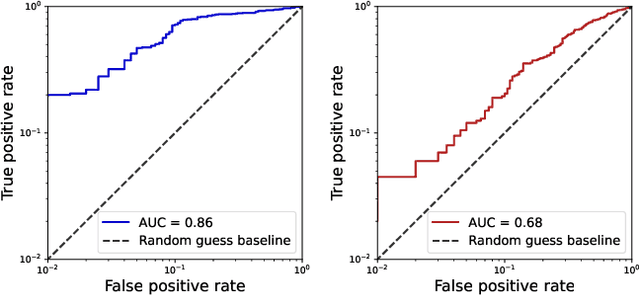
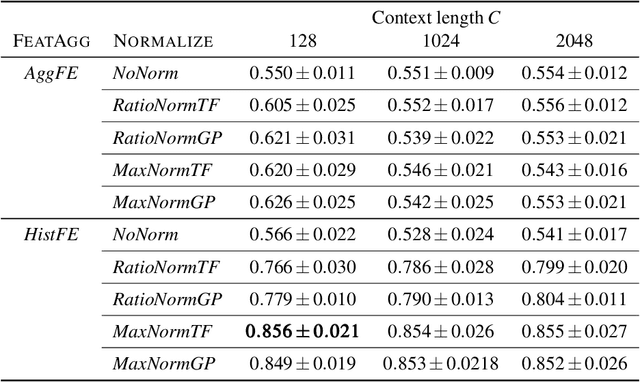


With large language models (LLMs) poised to become embedded in our daily lives, questions are starting to be raised about the dataset(s) they learned from. These questions range from potential bias or misinformation LLMs could retain from their training data to questions of copyright and fair use of human-generated text. However, while these questions emerge, developers of the recent state-of-the-art LLMs become increasingly reluctant to disclose details on their training corpus. We here introduce the task of document-level membership inference for real-world LLMs, i.e. inferring whether the LLM has seen a given document during training or not. First, we propose a procedure for the development and evaluation of document-level membership inference for LLMs by leveraging commonly used data sources for training and the model release date. We then propose a practical, black-box method to predict document-level membership and instantiate it on OpenLLaMA-7B with both books and academic papers. We show our methodology to perform very well, reaching an impressive AUC of 0.856 for books and 0.678 for papers. We then show our approach to outperform the sentence-level membership inference attacks used in the privacy literature for the document-level membership task. We finally evaluate whether smaller models might be less sensitive to document-level inference and show OpenLLaMA-3B to be approximately as sensitive as OpenLLaMA-7B to our approach. Taken together, our results show that accurate document-level membership can be inferred for LLMs, increasing the transparency of technology poised to change our lives.