 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Pruned Key-Value Attention: Learning When to Write by Predicting Future Utility
May 13, 2026Under modern test-time compute and agentic paradigms, language models process ever-longer sequences. Efficient text generation with transformer architectures is increasingly constrained by the Key-Value cache memory footprint and bandwidth. To address this limitation, we introduce Self-Pruned Key-Value Attention (SP-KV), a mechanism designed to predict future KV utility in order to reduce the size of the long-term KV cache. This strategy operates at a fine granularity: a lightweight utility predictor scores each key-value pair, and while recent KVs are always available via a local window, older pairs are written in the cache and used in global attention only if their predicted utility surpasses a given threshold. The LLM and the utility predictor are trained jointly end-to-end exclusively through next-token prediction loss, and are adapted from pretrained LLM checkpoints. Rather than enforcing a fixed compression ratio, SP-KV performs dynamic sparsification: the mechanism adapts to the input and typically reduces the KV cache size by a factor of $3$ to $10\times$, longer sequences often being more compressible. This leads to vast improvements in memory usage and decoding speed, with little to no degradation of validation loss nor performance on a broad set of downstream tasks. Beyond serving as an effective KV-cache reduction mechanism, our method reveals structured layer- and head-specific sparsity patterns that we can use to guide the design of hybrid local-global attention architectures.
ViDoRe V3: A Comprehensive Evaluation of Retrieval Augmented Generation in Complex Real-World Scenarios
Jan 13, 2026Retrieval-Augmented Generation (RAG) pipelines must address challenges beyond simple single-document retrieval, such as interpreting visual elements (tables, charts, images), synthesizing information across documents, and providing accurate source grounding. Existing benchmarks fail to capture this complexity, often focusing on textual data, single-document comprehension, or evaluating retrieval and generation in isolation. We introduce ViDoRe v3, a comprehensive multimodal RAG benchmark featuring multi-type queries over visually rich document corpora. It covers 10 datasets across diverse professional domains, comprising ~26,000 document pages paired with 3,099 human-verified queries, each available in 6 languages. Through 12,000 hours of human annotation effort, we provide high-quality annotations for retrieval relevance, bounding box localization, and verified reference answers. Our evaluation of state-of-the-art RAG pipelines reveals that visual retrievers outperform textual ones, late-interaction models and textual reranking substantially improve performance, and hybrid or purely visual contexts enhance answer generation quality. However, current models still struggle with non-textual elements, open-ended queries, and fine-grained visual grounding. To encourage progress in addressing these challenges, the benchmark is released under a commercially permissive license at https://hf.co/vidore.
Should We Still Pretrain Encoders with Masked Language Modeling?
Jul 01, 2025Learning high-quality text representations is fundamental to a wide range of NLP tasks. While encoder pretraining has traditionally relied on Masked Language Modeling (MLM), recent evidence suggests that decoder models pretrained with Causal Language Modeling (CLM) can be effectively repurposed as encoders, often surpassing traditional encoders on text representation benchmarks. However, it remains unclear whether these gains reflect an inherent advantage of the CLM objective or arise from confounding factors such as model and data scale. In this paper, we address this question through a series of large-scale, carefully controlled pretraining ablations, training a total of 30 models ranging from 210 million to 1 billion parameters, and conducting over 15,000 fine-tuning and evaluation runs. We find that while training with MLM generally yields better performance across text representation tasks, CLM-trained models are more data-efficient and demonstrate improved fine-tuning stability. Building on these findings, we experimentally show that a biphasic training strategy that sequentially applies CLM and then MLM, achieves optimal performance under a fixed computational training budget. Moreover, we demonstrate that this strategy becomes more appealing when initializing from readily available pretrained CLM models (from the existing LLM ecosystem), reducing the computational burden needed to train best-in-class encoder models. We release all project artifacts at https://hf.co/MLMvsCLM to foster further research.
EuroLLM-9B: Technical Report
Jun 04, 2025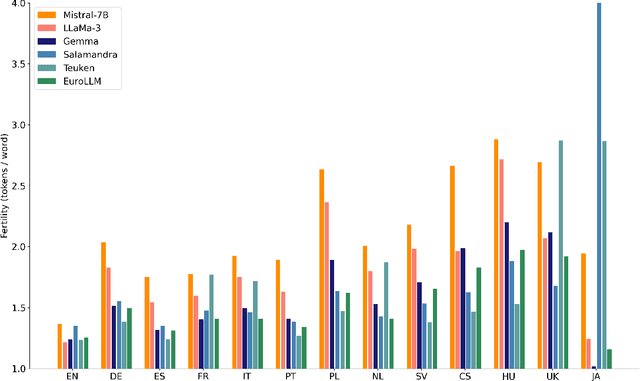
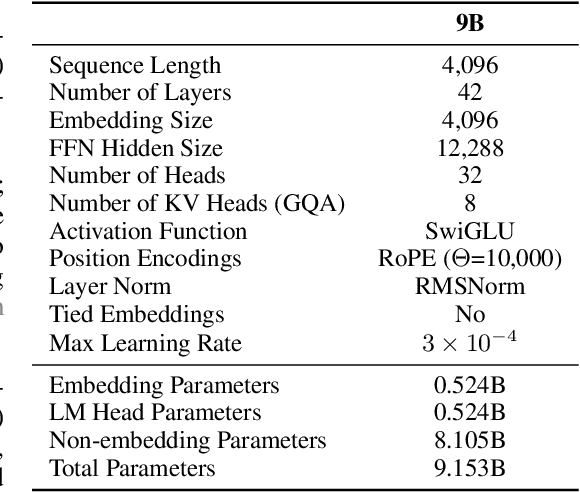
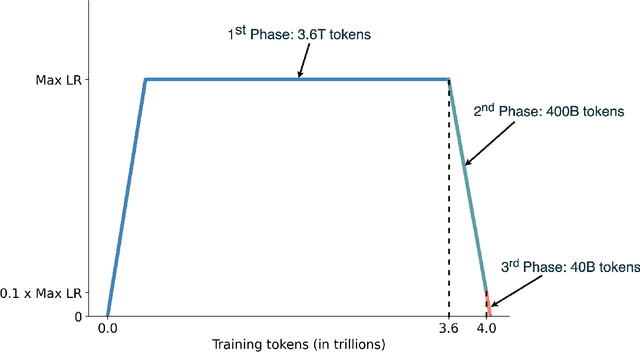
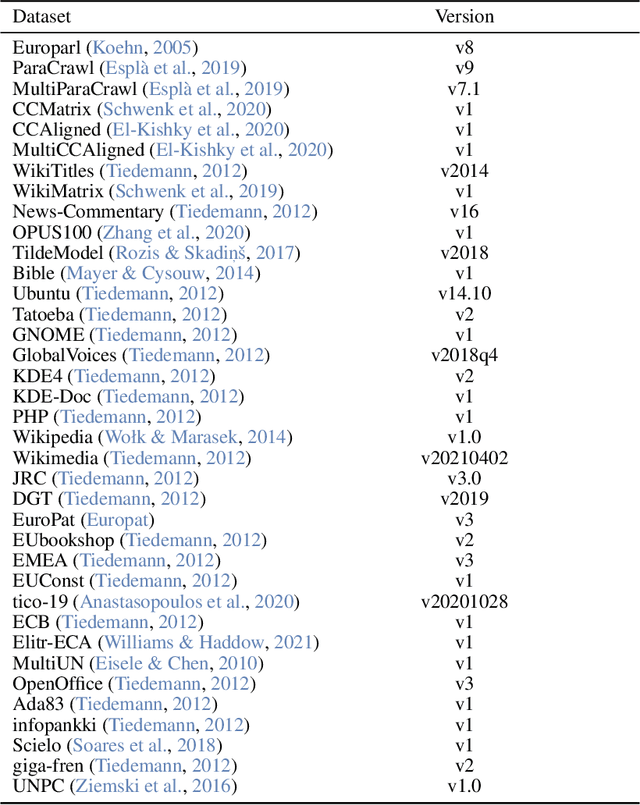
This report presents EuroLLM-9B, a large language model trained from scratch to support the needs of European citizens by covering all 24 official European Union languages and 11 additional languages. EuroLLM addresses the issue of European languages being underrepresented and underserved in existing open large language models. We provide a comprehensive overview of EuroLLM-9B's development, including tokenizer design, architectural specifications, data filtering, and training procedures. We describe the pre-training data collection and filtering pipeline, including the creation of EuroFilter, an AI-based multilingual filter, as well as the design of EuroBlocks-Synthetic, a novel synthetic dataset for post-training that enhances language coverage for European languages. Evaluation results demonstrate EuroLLM-9B's competitive performance on multilingual benchmarks and machine translation tasks, establishing it as the leading open European-made LLM of its size. To support open research and adoption, we release all major components of this work, including the base and instruction-tuned models, the EuroFilter classifier, and the synthetic post-training dataset.
Context is Gold to find the Gold Passage: Evaluating and Training Contextual Document Embeddings
May 30, 2025A limitation of modern document retrieval embedding methods is that they typically encode passages (chunks) from the same documents independently, often overlooking crucial contextual information from the rest of the document that could greatly improve individual chunk representations. In this work, we introduce ConTEB (Context-aware Text Embedding Benchmark), a benchmark designed to evaluate retrieval models on their ability to leverage document-wide context. Our results show that state-of-the-art embedding models struggle in retrieval scenarios where context is required. To address this limitation, we propose InSeNT (In-sequence Negative Training), a novel contrastive post-training approach which combined with late chunking pooling enhances contextual representation learning while preserving computational efficiency. Our method significantly improves retrieval quality on ConTEB without sacrificing base model performance. We further find chunks embedded with our method are more robust to suboptimal chunking strategies and larger retrieval corpus sizes. We open-source all artifacts at https://github.com/illuin-tech/contextual-embeddings.
ViDoRe Benchmark V2: Raising the Bar for Visual Retrieval
May 22, 2025The ViDoRe Benchmark V1 was approaching saturation with top models exceeding 90% nDCG@5, limiting its ability to discern improvements. ViDoRe Benchmark V2 introduces realistic, challenging retrieval scenarios via blind contextual querying, long and cross-document queries, and a hybrid synthetic and human-in-the-loop query generation process. It comprises four diverse, multilingual datasets and provides clear evaluation instructions. Initial results demonstrate substantial room for advancement and highlight insights on model generalization and multilingual capability. This benchmark is designed as a living resource, inviting community contributions to maintain relevance through future evaluations.
EuroBERT: Scaling Multilingual Encoders for European Languages
Mar 07, 2025General-purpose multilingual vector representations, used in retrieval, regression and classification, are traditionally obtained from bidirectional encoder models. Despite their wide applicability, encoders have been recently overshadowed by advances in generative decoder-only models. However, many innovations driving this progress are not inherently tied to decoders. In this paper, we revisit the development of multilingual encoders through the lens of these advances, and introduce EuroBERT, a family of multilingual encoders covering European and widely spoken global languages. Our models outperform existing alternatives across a diverse range of tasks, spanning multilingual capabilities, mathematics, and coding, and natively supporting sequences of up to 8,192 tokens. We also examine the design decisions behind EuroBERT, offering insights into our dataset composition and training pipeline. We publicly release the EuroBERT models, including intermediate training checkpoints, together with our training framework.
MMTEB: Massive Multilingual Text Embedding Benchmark
Feb 19, 2025Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.
EuroLLM: Multilingual Language Models for Europe
Sep 24, 2024The quality of open-weight LLMs has seen significant improvement, yet they remain predominantly focused on English. In this paper, we introduce the EuroLLM project, aimed at developing a suite of open-weight multilingual LLMs capable of understanding and generating text in all official European Union languages, as well as several additional relevant languages. We outline the progress made to date, detailing our data collection and filtering process, the development of scaling laws, the creation of our multilingual tokenizer, and the data mix and modeling configurations. Additionally, we release our initial models: EuroLLM-1.7B and EuroLLM-1.7B-Instruct and report their performance on multilingual general benchmarks and machine translation.
ColPali: Efficient Document Retrieval with Vision Language Models
Jul 02, 2024Documents are visually rich structures that convey information through text, as well as tables, figures, page layouts, or fonts. While modern document retrieval systems exhibit strong performance on query-to-text matching, they struggle to exploit visual cues efficiently, hindering their performance on practical document retrieval applications such as Retrieval Augmented Generation. To benchmark current systems on visually rich document retrieval, we introduce the Visual Document Retrieval Benchmark ViDoRe, composed of various page-level retrieving tasks spanning multiple domains, languages, and settings. The inherent shortcomings of modern systems motivate the introduction of a new retrieval model architecture, ColPali, which leverages the document understanding capabilities of recent Vision Language Models to produce high-quality contextualized embeddings solely from images of document pages. Combined with a late interaction matching mechanism, ColPali largely outperforms modern document retrieval pipelines while being drastically faster and end-to-end trainable.