 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViDoRe V3: A Comprehensive Evaluation of Retrieval Augmented Generation in Complex Real-World Scenarios
Jan 13, 2026Retrieval-Augmented Generation (RAG) pipelines must address challenges beyond simple single-document retrieval, such as interpreting visual elements (tables, charts, images), synthesizing information across documents, and providing accurate source grounding. Existing benchmarks fail to capture this complexity, often focusing on textual data, single-document comprehension, or evaluating retrieval and generation in isolation. We introduce ViDoRe v3, a comprehensive multimodal RAG benchmark featuring multi-type queries over visually rich document corpora. It covers 10 datasets across diverse professional domains, comprising ~26,000 document pages paired with 3,099 human-verified queries, each available in 6 languages. Through 12,000 hours of human annotation effort, we provide high-quality annotations for retrieval relevance, bounding box localization, and verified reference answers. Our evaluation of state-of-the-art RAG pipelines reveals that visual retrievers outperform textual ones, late-interaction models and textual reranking substantially improve performance, and hybrid or purely visual contexts enhance answer generation quality. However, current models still struggle with non-textual elements, open-ended queries, and fine-grained visual grounding. To encourage progress in addressing these challenges, the benchmark is released under a commercially permissive license at https://hf.co/vidore.
ViDoRe Benchmark V2: Raising the Bar for Visual Retrieval
May 22, 2025The ViDoRe Benchmark V1 was approaching saturation with top models exceeding 90% nDCG@5, limiting its ability to discern improvements. ViDoRe Benchmark V2 introduces realistic, challenging retrieval scenarios via blind contextual querying, long and cross-document queries, and a hybrid synthetic and human-in-the-loop query generation process. It comprises four diverse, multilingual datasets and provides clear evaluation instructions. Initial results demonstrate substantial room for advancement and highlight insights on model generalization and multilingual capability. This benchmark is designed as a living resource, inviting community contributions to maintain relevance through future evaluations.
GroUSE: A Benchmark to Evaluate Evaluators in Grounded Question Answering
Sep 10, 2024



Retrieval-Augmented Generation (RAG) has emerged as a common paradigm to use Large Language Models (LLMs) alongside private and up-to-date knowledge bases. In this work, we address the challenges of using LLM-as-a-Judge when evaluating grounded answers generated by RAG systems. To assess the calibration and discrimination capabilities of judge models, we identify 7 generator failure modes and introduce GroUSE (Grounded QA Unitary Scoring of Evaluators), a meta-evaluation benchmark of 144 unit tests. This benchmark reveals that existing automated RAG evaluation frameworks often overlook important failure modes, even when using GPT-4 as a judge. To improve on the current design of automated RAG evaluation frameworks, we propose a novel pipeline and find that while closed models perform well on GroUSE, state-of-the-art open-source judges do not generalize to our proposed criteria, despite strong correlation with GPT-4's judgement. Our findings suggest that correlation with GPT-4 is an incomplete proxy for the practical performance of judge models and should be supplemented with evaluations on unit tests for precise failure mode detection. We further show that finetuning Llama-3 on GPT-4's reasoning traces significantly boosts its evaluation capabilities, improving upon both correlation with GPT-4's evaluations and calibration on reference situations.
CroissantLLM: A Truly Bilingual French-English Language Model
Feb 02, 2024



We introduce CroissantLLM, a 1.3B language model pretrained on a set of 3T English and French tokens, to bring to the research and industrial community a high-performance, fully open-sourced bilingual model that runs swiftly on consumer-grade local hardware. To that end, we pioneer the approach of training an intrinsically bilingual model with a 1:1 English-to-French pretraining data ratio, a custom tokenizer, and bilingual finetuning datasets. We release the training dataset, notably containing a French split with manually curated, high-quality, and varied data sources. To assess performance outside of English, we craft a novel benchmark, FrenchBench, consisting of an array of classification and generation tasks, covering various orthogonal aspects of model performance in the French Language. Additionally, rooted in transparency and to foster further Large Language Model research, we release codebases, and dozens of checkpoints across various model sizes, training data distributions, and training steps, as well as fine-tuned Chat models, and strong translation models. We evaluate our model through the FMTI framework, and validate 81 % of the transparency criteria, far beyond the scores of even most open initiatives. This work enriches the NLP landscape, breaking away from previous English-centric work in order to strengthen our understanding of multilinguality in language models.
Probabilistic Jacobian-based Saliency Maps Attacks
Jul 12, 2020

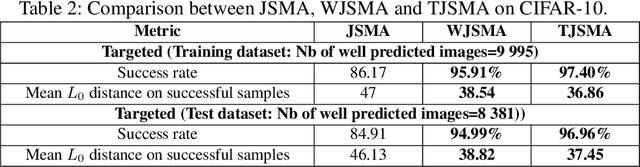
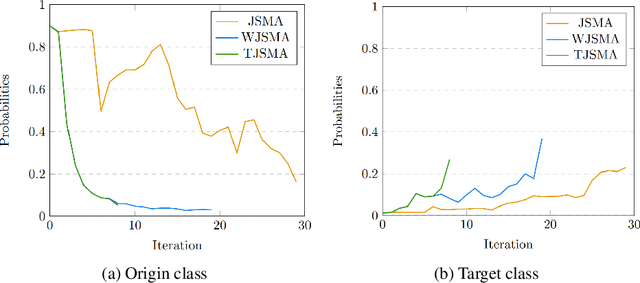
Machine learning models have achieved spectacular performances in various critical fields including intelligent monitoring, autonomous driving and malware detection. Therefore, robustness against adversarial attacks represents a key issue to trust these models. In particular, the Jacobian-based Saliency Map Attack (JSMA) is widely used to fool neural network classifiers. In this paper, we introduce Weighted JSMA (WJSMA) and Taylor JSMA (TJSMA), simple, faster and more efficient versions of JSMA. These attacks rely upon new saliency maps involving the neural network Jacobian, its output probabilities and the input features. We demonstrate the advantages of WJSMA and TJSMA through two computer vision applications on 1) LeNet-5, a well-known Neural Network classifier (NNC), on the MNIST database and on 2) a more challenging NNC on the CIFAR-10 dataset. We obtain that WJSMA and TJSMA significantly outperform JSMA in success rate, speed and average number of changed features. For instance, on LeNet-5 (with $100\%$ and $99.49\%$ accuracies on the training and test sets), WJSMA and TJSMA respectively exceed $97\%$ and $98.60\%$ in success rate for a maximum authorised distortion of $14.5\%$, outperforming JSMA with more than $9.5$ and $11$ percentage points. The new attacks are then used to defend and create more robust models than those trained against JSMA. Like JSMA, our attacks are not scalable on large datasets such as IMAGENET but despite this fact, they remain attractive for relatively small datasets like MNIST, CIFAR-10 and may be potential tools for future applications.