 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMALIA Technical Report: A Fully Open Source Large Language Model for European Portuguese
Mar 27, 2026Despite rapid progress in open large language models (LLMs), European Portuguese (pt-PT) remains underrepresented in both training data and native evaluation, with machine-translated benchmarks likely missing the variant's linguistic and cultural nuances. We introduce AMALIA, a fully open LLM that prioritizes pt-PT by using more high-quality pt-PT data during both the mid- and post-training stages. To evaluate pt-PT more faithfully, we release a suite of pt-PT benchmarks that includes translated standard tasks and four new datasets targeting pt-PT generation, linguistic competence, and pt-PT/pt-BR bias. Experiments show that AMALIA matches strong baselines on translated benchmarks while substantially improving performance on pt-PT-specific evaluations, supporting the case for targeted training and native benchmarking for European Portuguese.
LanteRn: Latent Visual Structured Reasoning
Mar 26, 2026While language reasoning models excel in many tasks, visual reasoning remains challenging for current large multimodal models (LMMs). As a result, most LMMs default to verbalizing perceptual content into text, a strong limitation for tasks requiring fine-grained spatial and visual understanding. While recent approaches take steps toward thinking with images by invoking tools or generating intermediate images, they either rely on external modules, or incur unnecessary computation by reasoning directly in pixel space. In this paper, we introduce LanteRn, a framework that enables LMMs to interleave language with compact latent visual representations, allowing visual reasoning to occur directly in latent space. LanteRn augments a vision-language transformer with the ability to generate and attend to continuous visual thought embeddings during inference. We train the model in two stages: supervised fine-tuning to ground visual features in latent states, followed by reinforcement learning to align latent reasoning with task-level utility. We evaluate LanteRn on three perception-centric benchmarks (VisCoT, V*, and Blink), observing consistent improvements in visual grounding and fine-grained reasoning. These results suggest that internal latent representations provide a promising direction for more efficient multimodal reasoning.
EuroBERT: Scaling Multilingual Encoders for European Languages
Mar 07, 2025General-purpose multilingual vector representations, used in retrieval, regression and classification, are traditionally obtained from bidirectional encoder models. Despite their wide applicability, encoders have been recently overshadowed by advances in generative decoder-only models. However, many innovations driving this progress are not inherently tied to decoders. In this paper, we revisit the development of multilingual encoders through the lens of these advances, and introduce EuroBERT, a family of multilingual encoders covering European and widely spoken global languages. Our models outperform existing alternatives across a diverse range of tasks, spanning multilingual capabilities, mathematics, and coding, and natively supporting sequences of up to 8,192 tokens. We also examine the design decisions behind EuroBERT, offering insights into our dataset composition and training pipeline. We publicly release the EuroBERT models, including intermediate training checkpoints, together with our training framework.
Learning Non-Monotonic Automatic Post-Editing of Translations from Human Orderings
Apr 29, 2020
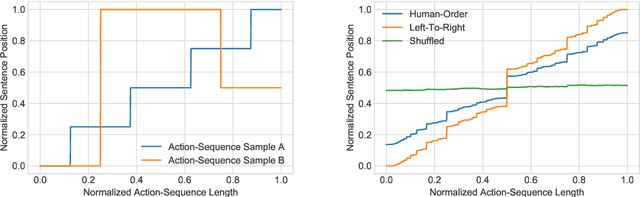
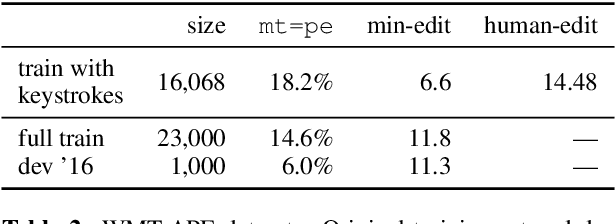
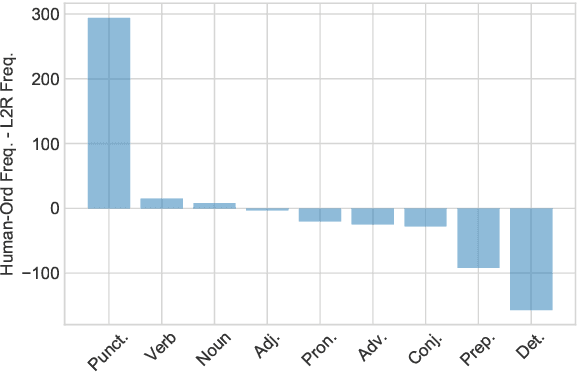
Recent research in neural machine translation has explored flexible generation orders, as an alternative to left-to-right generation. However, training non-monotonic models brings a new complication: how to search for a good ordering when there is a combinatorial explosion of orderings arriving at the same final result? Also, how do these automatic orderings compare with the actual behaviour of human translators? Current models rely on manually built biases or are left to explore all possibilities on their own. In this paper, we analyze the orderings produced by human post-editors and use them to train an automatic post-editing system. We compare the resulting system with those trained with left-to-right and random post-editing orderings. We observe that humans tend to follow a nearly left-to-right order, but with interesting deviations, such as preferring to start by correcting punctuation or verbs.
Sparse and Structured Visual Attention
Feb 13, 2020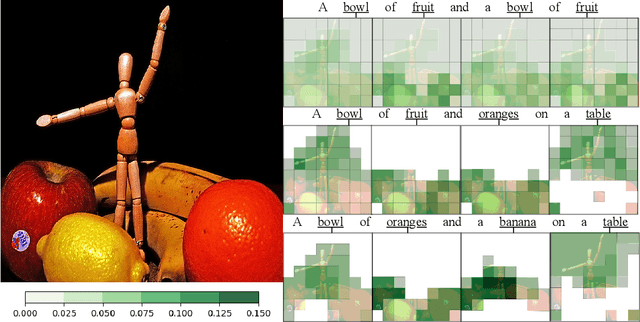

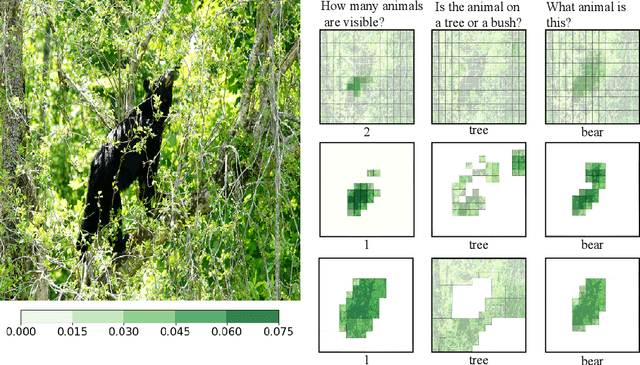

Visual attention mechanisms are widely used in multimodal tasks, such as image captioning and visual question answering (VQA). One drawback of softmax-based attention mechanisms is that they assign probability mass to all image regions, regardless of their adjacency structure and of their relevance to the text. In this paper, to better link the image structure with the text, we replace the traditional softmax attention mechanism with two alternative sparsity-promoting transformations: sparsemax, which is able to select the relevant regions only (assigning zero weight to the rest), and a newly proposed Total-Variation Sparse Attention (TVmax), which further encourages the joint selection of adjacent spatial locations. Experiments in image captioning and VQA, using both LSTM and Transformer architectures, show gains in terms of human-rated caption quality, attention relevance, and VQA accuracy, with improved interpretability.