 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse and Structured Visual Attention
Paper and Code
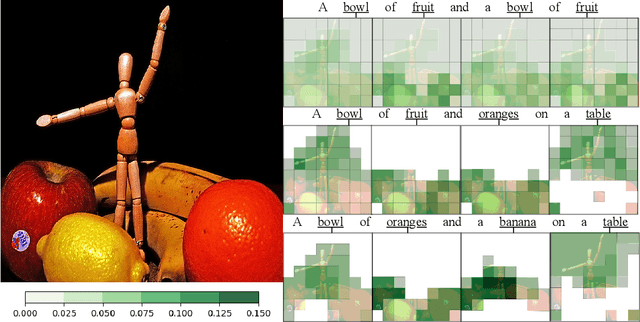

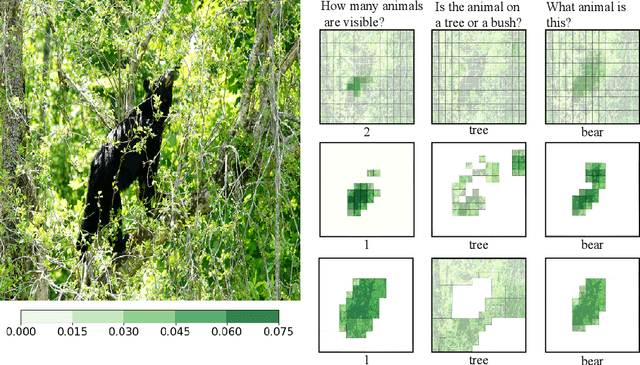

Visual attention mechanisms are widely used in multimodal tasks, such as image captioning and visual question answering (VQA). One drawback of softmax-based attention mechanisms is that they assign probability mass to all image regions, regardless of their adjacency structure and of their relevance to the text. In this paper, to better link the image structure with the text, we replace the traditional softmax attention mechanism with two alternative sparsity-promoting transformations: sparsemax, which is able to select the relevant regions only (assigning zero weight to the rest), and a newly proposed Total-Variation Sparse Attention (TVmax), which further encourages the joint selection of adjacent spatial locations. Experiments in image captioning and VQA, using both LSTM and Transformer architectures, show gains in terms of human-rated caption quality, attention relevance, and VQA accuracy, with improved interpretability.