 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChunk-based Nearest Neighbor Machine Translation
May 24, 2022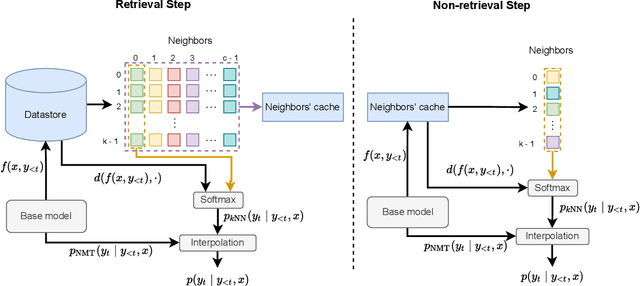
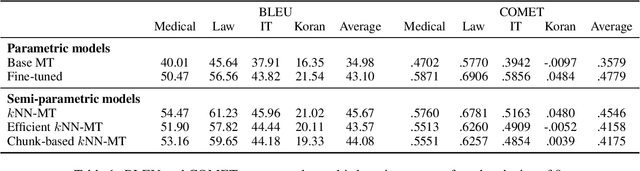
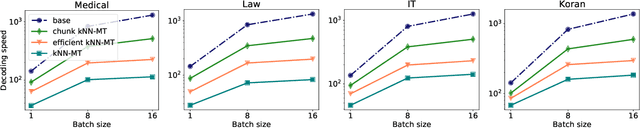
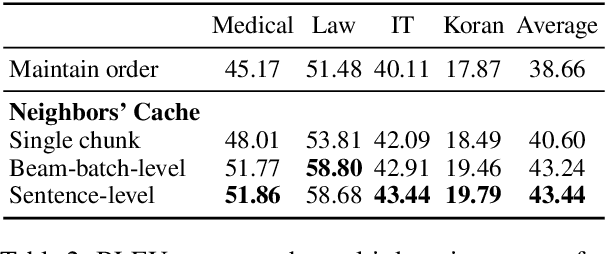
Semi-parametric models, which augment generation with retrieval, have led to impressive results in language modeling and machine translation, due to their ability to leverage information retrieved from a datastore of examples. One of the most prominent approaches, $k$NN-MT, has an outstanding performance on domain adaptation by retrieving tokens from a domain-specific datastore \citep{khandelwal2020nearest}. However, $k$NN-MT requires retrieval for every single generated token, leading to a very low decoding speed (around 8 times slower than a parametric model). In this paper, we introduce a \textit{chunk-based} $k$NN-MT model which retrieves chunks of tokens from the datastore, instead of a single token. We propose several strategies for incorporating the retrieved chunks into the generation process, and for selecting the steps at which the model needs to search for neighbors in the datastore. Experiments on machine translation in two settings, static domain adaptation and ``on-the-fly'' adaptation, show that the chunk-based $k$NN-MT model leads to a significant speed-up (up to 4 times) with only a small drop in translation quality.
Efficient Machine Translation Domain Adaptation
Apr 26, 2022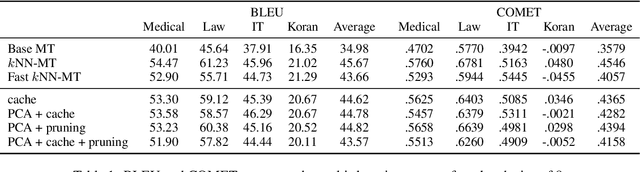
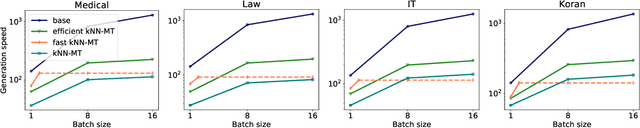
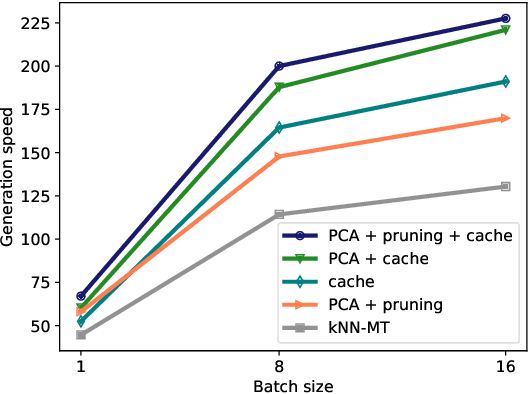
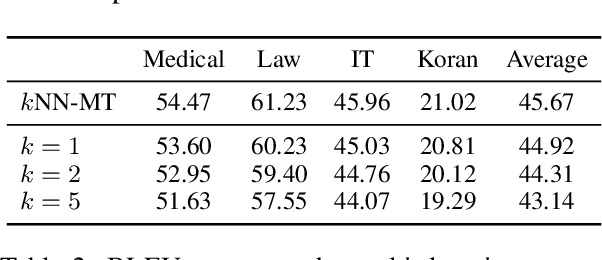
Machine translation models struggle when translating out-of-domain text, which makes domain adaptation a topic of critical importance. However, most domain adaptation methods focus on fine-tuning or training the entire or part of the model on every new domain, which can be costly. On the other hand, semi-parametric models have been shown to successfully perform domain adaptation by retrieving examples from an in-domain datastore (Khandelwal et al., 2021). A drawback of these retrieval-augmented models, however, is that they tend to be substantially slower. In this paper, we explore several approaches to speed up nearest neighbor machine translation. We adapt the methods recently proposed by He et al. (2021) for language modeling, and introduce a simple but effective caching strategy that avoids performing retrieval when similar contexts have been seen before. Translation quality and runtimes for several domains show the effectiveness of the proposed solutions.
Model-Value Inconsistency as a Signal for Epistemic Uncertainty
Dec 08, 2021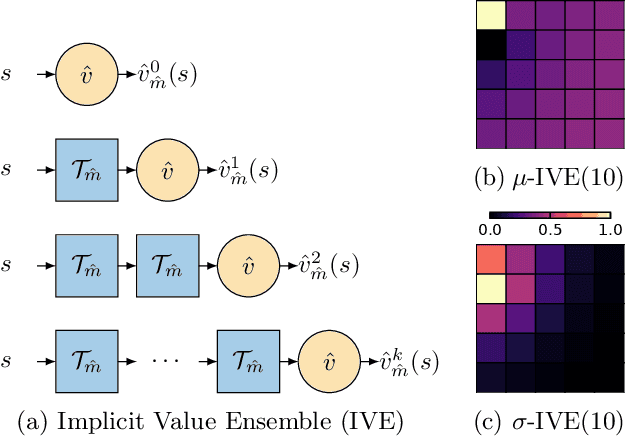

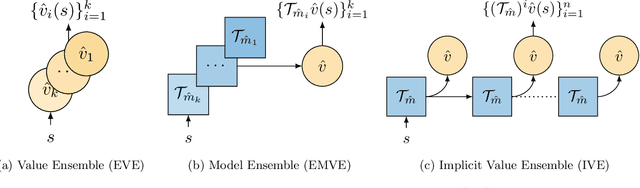
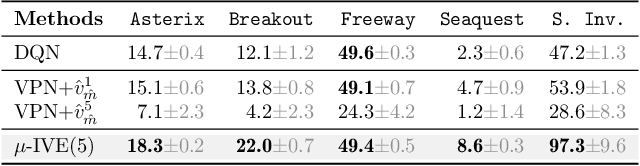
Using a model of the environment and a value function, an agent can construct many estimates of a state's value, by unrolling the model for different lengths and bootstrapping with its value function. Our key insight is that one can treat this set of value estimates as a type of ensemble, which we call an \emph{implicit value ensemble} (IVE). Consequently, the discrepancy between these estimates can be used as a proxy for the agent's epistemic uncertainty; we term this signal \emph{model-value inconsistency} or \emph{self-inconsistency} for short. Unlike prior work which estimates uncertainty by training an ensemble of many models and/or value functions, this approach requires only the single model and value function which are already being learned in most model-based reinforcement learning algorithms. We provide empirical evidence in both tabular and function approximation settings from pixels that self-inconsistency is useful (i) as a signal for exploration, (ii) for acting safely under distribution shifts, and (iii) for robustifying value-based planning with a model.
Self-Consistent Models and Values
Oct 25, 2021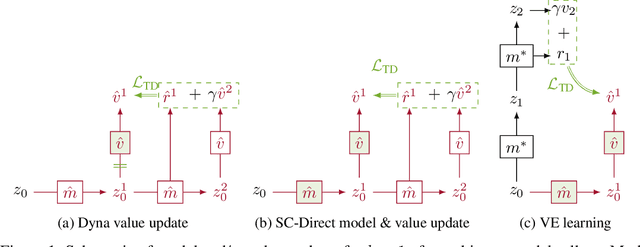

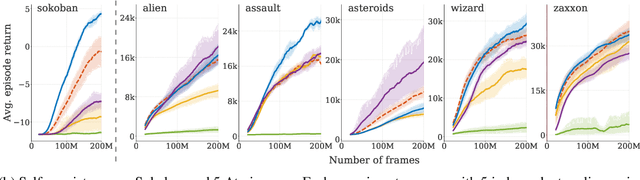
Learned models of the environment provide reinforcement learning (RL) agents with flexible ways of making predictions about the environment. In particular, models enable planning, i.e. using more computation to improve value functions or policies, without requiring additional environment interactions. In this work, we investigate a way of augmenting model-based RL, by additionally encouraging a learned model and value function to be jointly \emph{self-consistent}. Our approach differs from classic planning methods such as Dyna, which only update values to be consistent with the model. We propose multiple self-consistency updates, evaluate these in both tabular and function approximation settings, and find that, with appropriate choices, self-consistency helps both policy evaluation and control.
$\infty$-former: Infinite Memory Transformer
Sep 15, 2021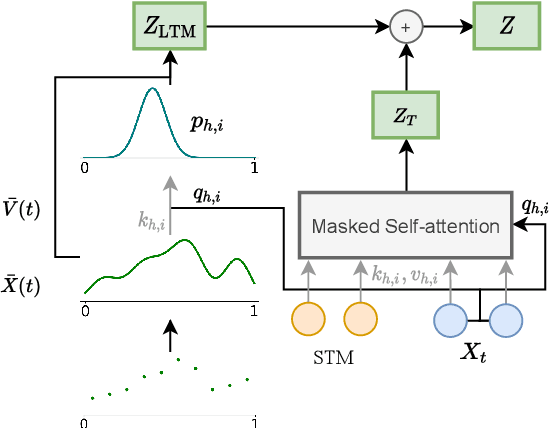

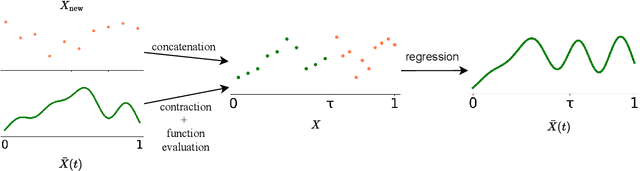

Transformers struggle when attending to long contexts, since the amount of computation grows with the context length, and therefore they cannot model long-term memories effectively. Several variations have been proposed to alleviate this problem, but they all have a finite memory capacity, being forced to drop old information. In this paper, we propose the $\infty$-former, which extends the vanilla transformer with an unbounded long-term memory. By making use of a continuous-space attention mechanism to attend over the long-term memory, the $\infty$-former's attention complexity becomes independent of the context length. Thus, it is able to model arbitrarily long contexts and maintain "sticky memories" while keeping a fixed computation budget. Experiments on a synthetic sorting task demonstrate the ability of the $\infty$-former to retain information from long sequences. We also perform experiments on language modeling, by training a model from scratch and by fine-tuning a pre-trained language model, which show benefits of unbounded long-term memories.
Priberam at MESINESP Multi-label Classification of Medical Texts Task
May 12, 2021

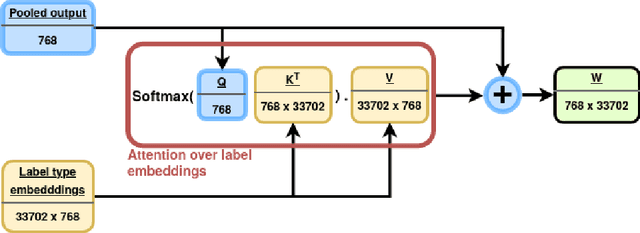
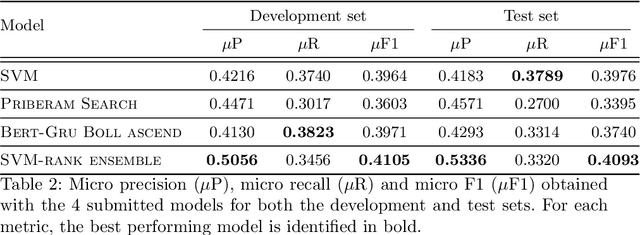
Medical articles provide current state of the art treatments and diagnostics to many medical practitioners and professionals. Existing public databases such as MEDLINE contain over 27 million articles, making it difficult to extract relevant content without the use of efficient search engines. Information retrieval tools are crucial in order to navigate and provide meaningful recommendations for articles and treatments. Classifying these articles into broader medical topics can improve the retrieval of related articles. The set of medical labels considered for the MESINESP task is on the order of several thousands of labels (DeCS codes), which falls under the extreme multi-label classification problem. The heterogeneous and highly hierarchical structure of medical topics makes the task of manually classifying articles extremely laborious and costly. It is, therefore, crucial to automate the process of classification. Typical machine learning algorithms become computationally demanding with such a large number of labels and achieving better recall on such datasets becomes an unsolved problem. This work presents Priberam's participation at the BioASQ task Mesinesp. We address the large multi-label classification problem through the use of four different models: a Support Vector Machine (SVM), a customised search engine (Priberam Search), a BERT based classifier, and a SVM-rank ensemble of all the previous models. Results demonstrate that all three individual models perform well and the best performance is achieved by their ensemble, granting Priberam the 6th place in the present challenge and making it the 2nd best team.
Sparse Text Generation
Apr 06, 2020
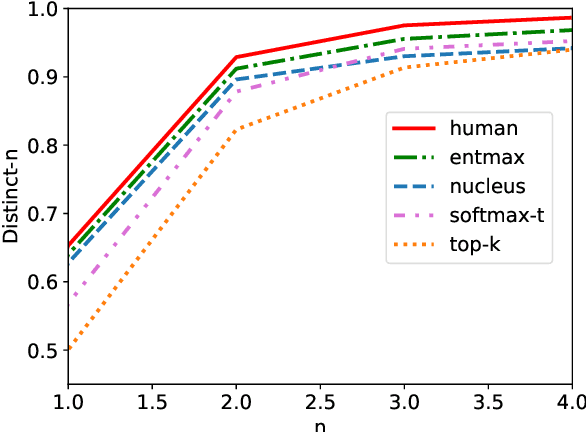
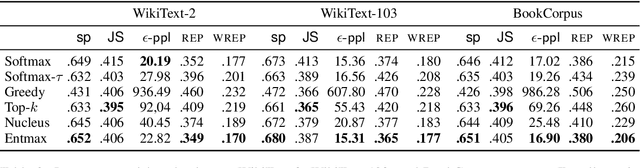
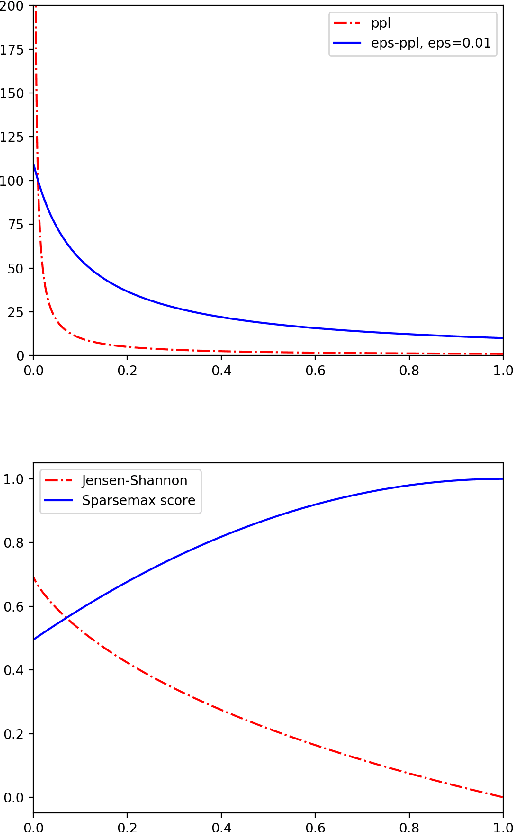
Current state-of-the-art text generators build on powerful language models such as GPT-2, which have impressive performance. However, to avoid degenerate text, they require sampling from a modified softmax, via temperature parameters or ad-hoc truncation techniques, as in top-$k$ or nucleus sampling. This creates a mismatch between training and testing conditions. In this paper, we use the recently introduced entmax transformation to train and sample from a natively sparse language model, avoiding this mismatch. The result is a text generator with favorable performance in terms of fluency and consistency, fewer repetitions, and n-gram diversity closer to human text. In order to evaluate our model, we propose three new metrics that are tailored for comparing sparse or truncated distributions: $\epsilon$-perplexity, sparsemax score, and Jensen-Shannon divergence. Human-evaluated experiments in story completion and dialogue generation show that entmax sampling leads to more engaging and coherent stories and conversations.
Sparse and Structured Visual Attention
Feb 13, 2020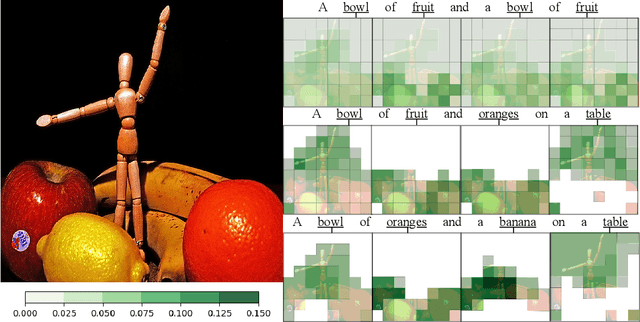

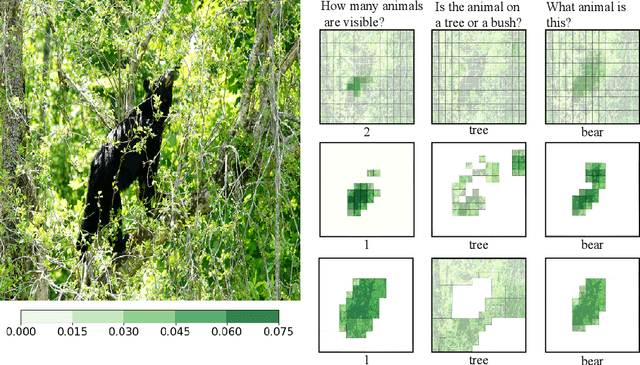

Visual attention mechanisms are widely used in multimodal tasks, such as image captioning and visual question answering (VQA). One drawback of softmax-based attention mechanisms is that they assign probability mass to all image regions, regardless of their adjacency structure and of their relevance to the text. In this paper, to better link the image structure with the text, we replace the traditional softmax attention mechanism with two alternative sparsity-promoting transformations: sparsemax, which is able to select the relevant regions only (assigning zero weight to the rest), and a newly proposed Total-Variation Sparse Attention (TVmax), which further encourages the joint selection of adjacent spatial locations. Experiments in image captioning and VQA, using both LSTM and Transformer architectures, show gains in terms of human-rated caption quality, attention relevance, and VQA accuracy, with improved interpretability.
Joint Learning of Named Entity Recognition and Entity Linking
Jul 18, 2019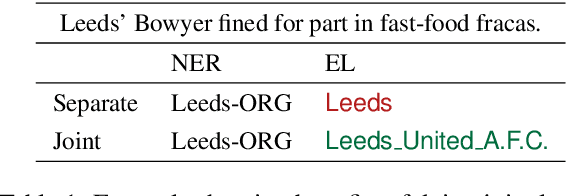
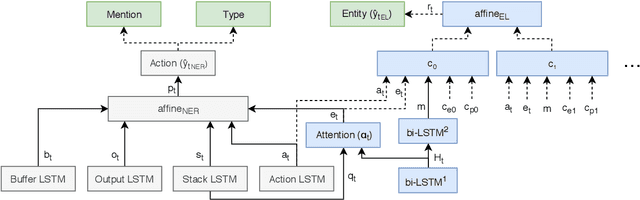
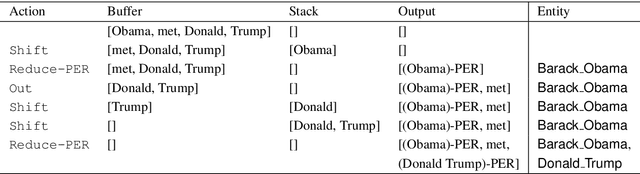
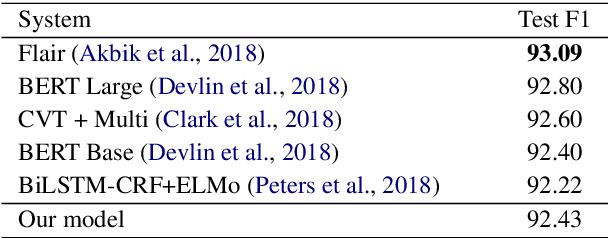
Named entity recognition (NER) and entity linking (EL) are two fundamentally related tasks, since in order to perform EL, first the mentions to entities have to be detected. However, most entity linking approaches disregard the mention detection part, assuming that the correct mentions have been previously detected. In this paper, we perform joint learning of NER and EL to leverage their relatedness and obtain a more robust and generalisable system. For that, we introduce a model inspired by the Stack-LSTM approach (Dyer et al., 2015). We observe that, in fact, doing multi-task learning of NER and EL improves the performance in both tasks when comparing with models trained with individual objectives. Furthermore, we achieve results competitive with the state-of-the-art in both NER and EL.
Jointly Extracting and Compressing Documents with Summary State Representations
Apr 05, 2019
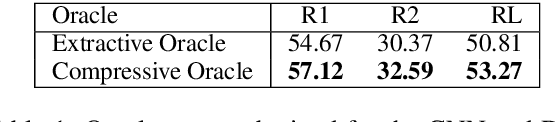
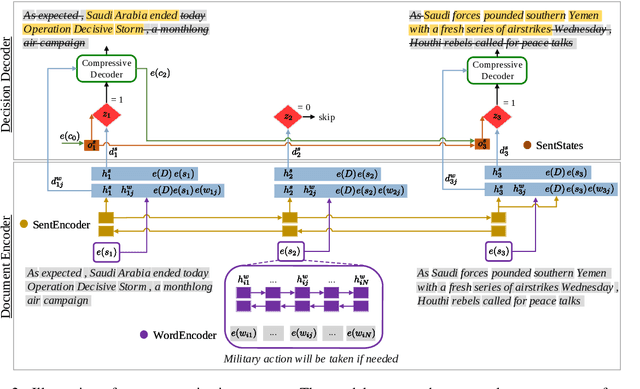

We present a new neural model for text summarization that first extracts sentences from a document and then compresses them. The proposed model offers a balance that sidesteps the difficulties in abstractive methods while generating more concise summaries than extractive methods. In addition, our model dynamically determines the length of the output summary based on the gold summaries it observes during training and does not require length constraints typical to extractive summarization. The model achieves state-of-the-art results on the CNN/DailyMail and Newsroom datasets, improving over current extractive and abstractive methods. Human evaluations demonstrate that our model generates concise and informative summaries. We also make available a new dataset of oracle compressive summaries derived automatically from the CNN/DailyMail reference summaries.