 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimplifying Multilingual News Clustering Through Projection From a Shared Space
Apr 28, 2022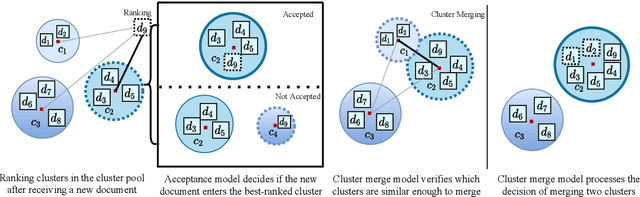
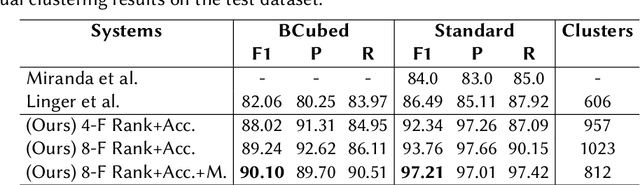
The task of organizing and clustering multilingual news articles for media monitoring is essential to follow news stories in real time. Most approaches to this task focus on high-resource languages (mostly English), with low-resource languages being disregarded. With that in mind, we present a much simpler online system that is able to cluster an incoming stream of documents without depending on language-specific features. We empirically demonstrate that the use of multilingual contextual embeddings as the document representation significantly improves clustering quality. We challenge previous crosslingual approaches by removing the precondition of building monolingual clusters. We model the clustering process as a set of linear classifiers to aggregate similar documents, and correct closely-related multilingual clusters through merging in an online fashion. Our system achieves state-of-the-art results on a multilingual news stream clustering dataset, and we introduce a new evaluation for zero-shot news clustering in multiple languages. We make our code available as open-source.
* 10 pages, 1 figure
Priberam at MESINESP Multi-label Classification of Medical Texts Task
May 12, 2021

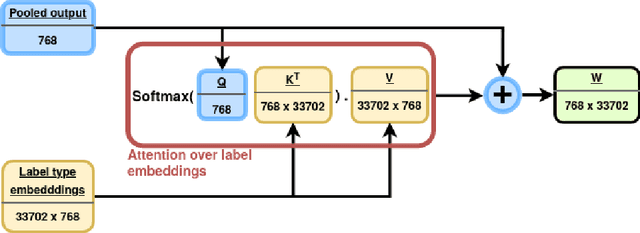
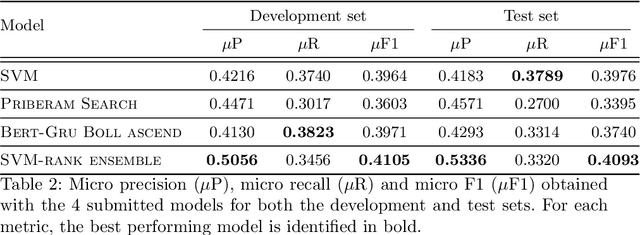
Medical articles provide current state of the art treatments and diagnostics to many medical practitioners and professionals. Existing public databases such as MEDLINE contain over 27 million articles, making it difficult to extract relevant content without the use of efficient search engines. Information retrieval tools are crucial in order to navigate and provide meaningful recommendations for articles and treatments. Classifying these articles into broader medical topics can improve the retrieval of related articles. The set of medical labels considered for the MESINESP task is on the order of several thousands of labels (DeCS codes), which falls under the extreme multi-label classification problem. The heterogeneous and highly hierarchical structure of medical topics makes the task of manually classifying articles extremely laborious and costly. It is, therefore, crucial to automate the process of classification. Typical machine learning algorithms become computationally demanding with such a large number of labels and achieving better recall on such datasets becomes an unsolved problem. This work presents Priberam's participation at the BioASQ task Mesinesp. We address the large multi-label classification problem through the use of four different models: a Support Vector Machine (SVM), a customised search engine (Priberam Search), a BERT based classifier, and a SVM-rank ensemble of all the previous models. Results demonstrate that all three individual models perform well and the best performance is achieved by their ensemble, granting Priberam the 6th place in the present challenge and making it the 2nd best team.
Jointly Extracting and Compressing Documents with Summary State Representations
Apr 05, 2019
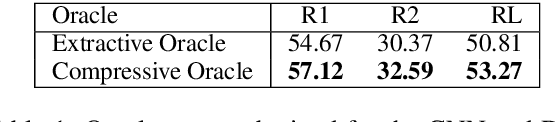
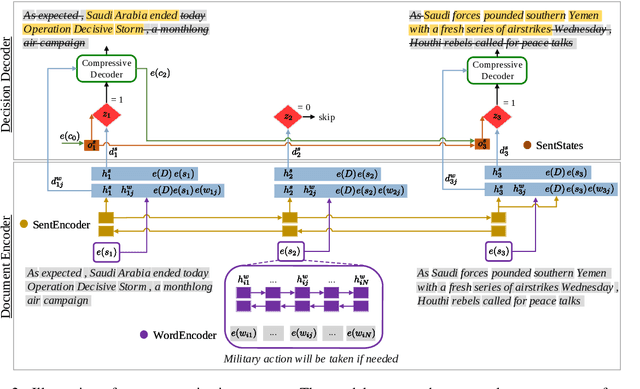

We present a new neural model for text summarization that first extracts sentences from a document and then compresses them. The proposed model offers a balance that sidesteps the difficulties in abstractive methods while generating more concise summaries than extractive methods. In addition, our model dynamically determines the length of the output summary based on the gold summaries it observes during training and does not require length constraints typical to extractive summarization. The model achieves state-of-the-art results on the CNN/DailyMail and Newsroom datasets, improving over current extractive and abstractive methods. Human evaluations demonstrate that our model generates concise and informative summaries. We also make available a new dataset of oracle compressive summaries derived automatically from the CNN/DailyMail reference summaries.
Automated Fact Checking in the News Room
Apr 03, 2019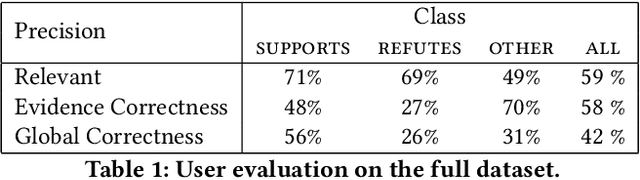
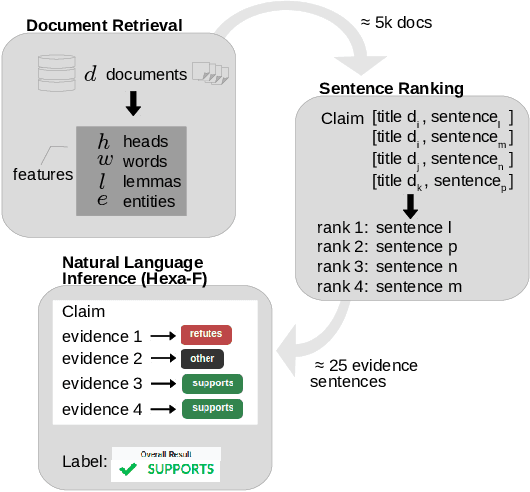
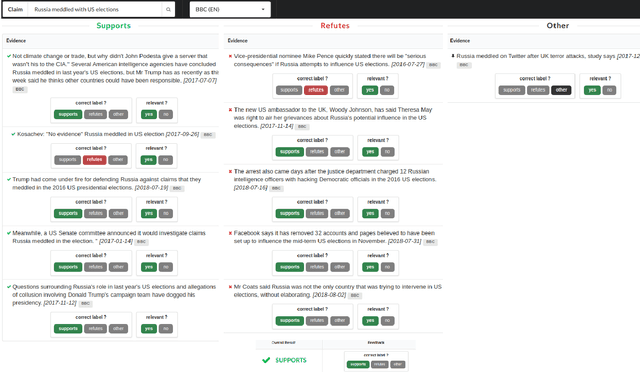
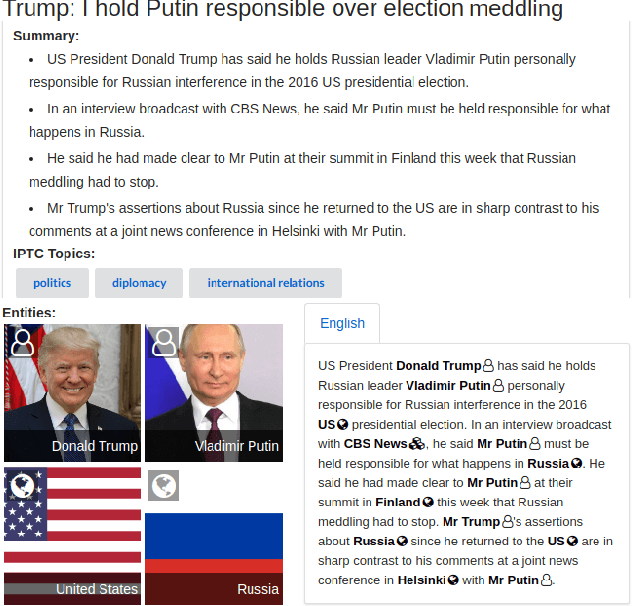
Fact checking is an essential task in journalism; its importance has been highlighted due to recently increased concerns and efforts in combating misinformation. In this paper, we present an automated fact-checking platform which given a claim, it retrieves relevant textual evidence from a document collection, predicts whether each piece of evidence supports or refutes the claim, and returns a final verdict. We describe the architecture of the system and the user interface, focusing on the choices made to improve its user-friendliness and transparency. We conduct a user study of the fact-checking platform in a journalistic setting: we integrated it with a collection of news articles and provide an evaluation of the platform using feedback from journalists in their workflow. We found that the predictions of our platform were correct 58\% of the time, and 59\% of the returned evidence was relevant.
Multilingual Clustering of Streaming News
Sep 03, 2018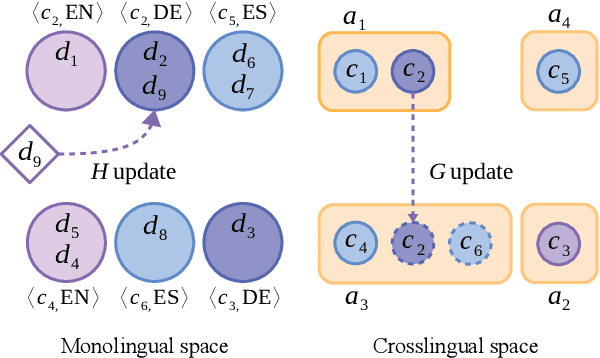



Clustering news across languages enables efficient media monitoring by aggregating articles from multilingual sources into coherent stories. Doing so in an online setting allows scalable processing of massive news streams. To this end, we describe a novel method for clustering an incoming stream of multilingual documents into monolingual and crosslingual story clusters. Unlike typical clustering approaches that consider a small and known number of labels, we tackle the problem of discovering an ever growing number of cluster labels in an online fashion, using real news datasets in multiple languages. Our method is simple to implement, computationally efficient and produces state-of-the-art results on datasets in German, English and Spanish.