 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Denoising Diffusion Approach to Integer Factorization
Sep 11, 2023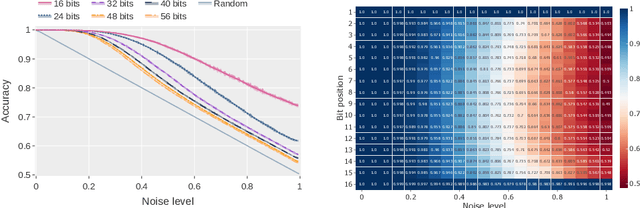
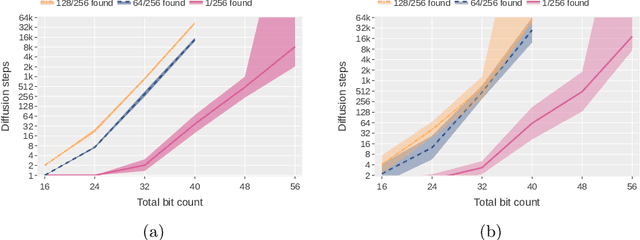
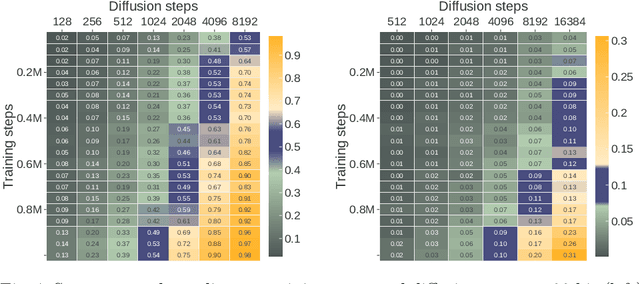
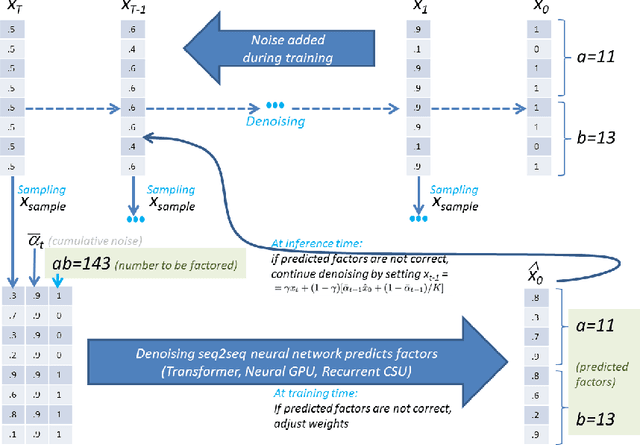
Integer factorization is a famous computational problem unknown whether being solvable in the polynomial time. With the rise of deep neural networks, it is interesting whether they can facilitate faster factorization. We present an approach to factorization utilizing deep neural networks and discrete denoising diffusion that works by iteratively correcting errors in a partially-correct solution. To this end, we develop a new seq2seq neural network architecture, employ relaxed categorical distribution and adapt the reverse diffusion process to cope better with inaccuracies in the denoising step. The approach is able to find factors for integers of up to 56 bits long. Our analysis indicates that investment in training leads to an exponential decrease of sampling steps required at inference to achieve a given success rate, thus counteracting an exponential run-time increase depending on the bit-length.
Differentiable Disentanglement Filter: an Application Agnostic Core Concept Discovery Probe
Jul 24, 2019
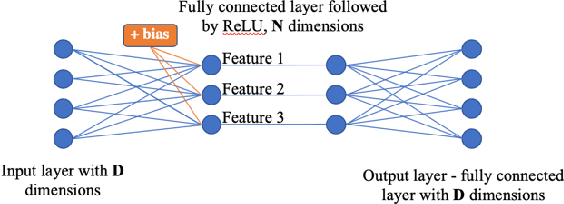
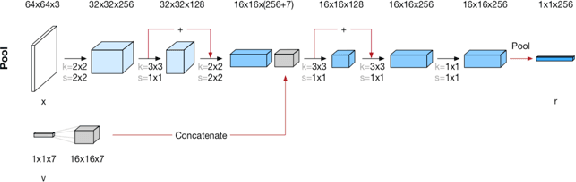
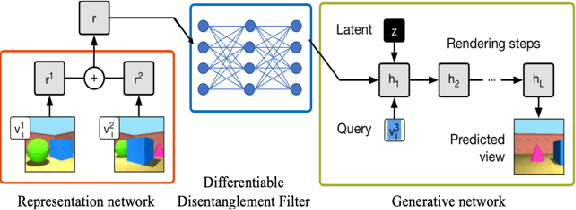
It has long been speculated that deep neural networks function by discovering a hierarchical set of domain-specific core concepts or patterns, which are further combined to recognize even more elaborate concepts for the classification or other machine learning tasks. Meanwhile disentangling the actual core concepts engrained in the word embeddings (like word2vec or BERT) or deep convolutional image recognition neural networks (like PG-GAN) is difficult and some success there has been achieved only recently. In this paper we propose a novel neural network nonlinearity named Differentiable Disentanglement Filter (DDF) which can be transparently inserted into any existing neural network layer to automatically disentangle the core concepts used by that layer. The DDF probe is inspired by the obscure properties of the hyper-dimensional computing theory. The DDF proof-of-concept implementation is shown to disentangle concepts within the neural 3D scene representation - a task vital for visual grounding of natural language narratives.
Multilingual Clustering of Streaming News
Sep 03, 2018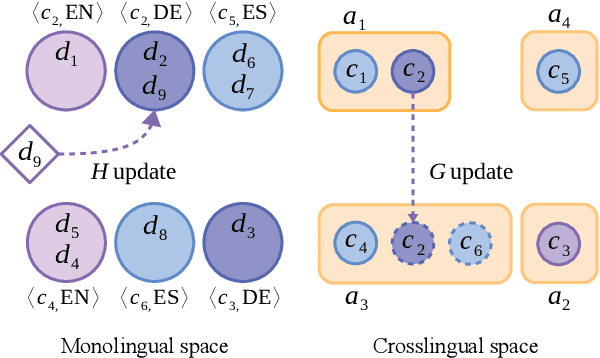



Clustering news across languages enables efficient media monitoring by aggregating articles from multilingual sources into coherent stories. Doing so in an online setting allows scalable processing of massive news streams. To this end, we describe a novel method for clustering an incoming stream of multilingual documents into monolingual and crosslingual story clusters. Unlike typical clustering approaches that consider a small and known number of labels, we tackle the problem of discovering an ever growing number of cluster labels in an online fashion, using real news datasets in multiple languages. Our method is simple to implement, computationally efficient and produces state-of-the-art results on datasets in German, English and Spanish.
The Role of CNL and AMR in Scalable Abstractive Summarization for Multilingual Media Monitoring
Jun 20, 2016

In the era of Big Data and Deep Learning, there is a common view that machine learning approaches are the only way to cope with the robust and scalable information extraction and summarization. It has been recently proposed that the CNL approach could be scaled up, building on the concept of embedded CNL and, thus, allowing for CNL-based information extraction from e.g. normative or medical texts that are rather controlled by nature but still infringe the boundaries of CNL. Although it is arguable if CNL can be exploited to approach the robust wide-coverage semantic parsing for use cases like media monitoring, its potential becomes much more obvious in the opposite direction: generation of story highlights from the summarized AMR graphs, which is in the focus of this position paper.
* Proceedings of the 5th Workshop on Controlled Natural Language, 2016 (to appear)
RIGA at SemEval-2016 Task 8: Impact of Smatch Extensions and Character-Level Neural Translation on AMR Parsing Accuracy
Apr 05, 2016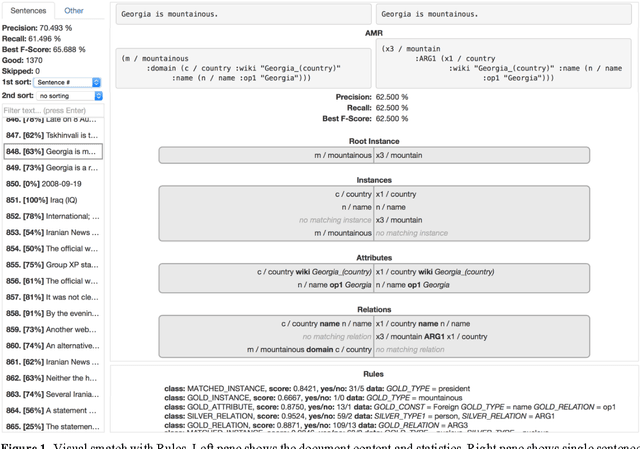
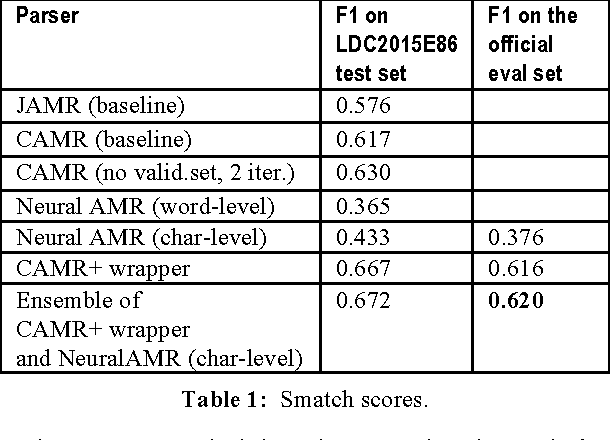
Two extensions to the AMR smatch scoring script are presented. The first extension com-bines the smatch scoring script with the C6.0 rule-based classifier to produce a human-readable report on the error patterns frequency observed in the scored AMR graphs. This first extension results in 4% gain over the state-of-art CAMR baseline parser by adding to it a manually crafted wrapper fixing the identified CAMR parser errors. The second extension combines a per-sentence smatch with an en-semble method for selecting the best AMR graph among the set of AMR graphs for the same sentence. This second modification au-tomatically yields further 0.4% gain when ap-plied to outputs of two nondeterministic AMR parsers: a CAMR+wrapper parser and a novel character-level neural translation AMR parser. For AMR parsing task the character-level neural translation attains surprising 7% gain over the carefully optimized word-level neural translation. Overall, we achieve smatch F1=62% on the SemEval-2016 official scor-ing set and F1=67% on the LDC2015E86 test set.
Character-Level Neural Translation for Multilingual Media Monitoring in the SUMMA Project
Apr 05, 2016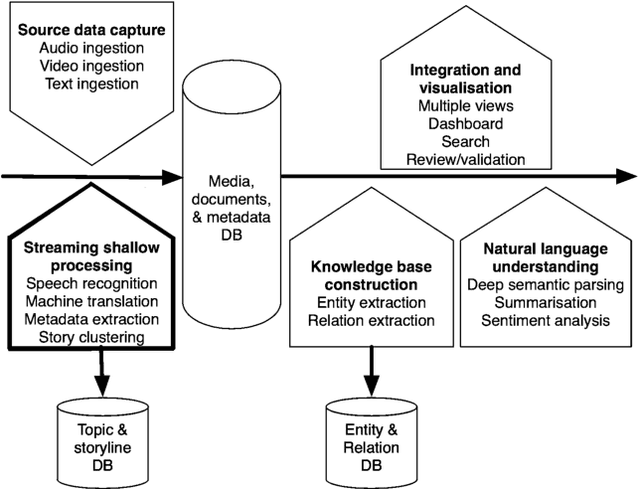


The paper steps outside the comfort-zone of the traditional NLP tasks like automatic speech recognition (ASR) and machine translation (MT) to addresses two novel problems arising in the automated multilingual news monitoring: segmentation of the TV and radio program ASR transcripts into individual stories, and clustering of the individual stories coming from various sources and languages into storylines. Storyline clustering of stories covering the same events is an essential task for inquisitorial media monitoring. We address these two problems jointly by engaging the low-dimensional semantic representation capabilities of the sequence to sequence neural translation models. To enable joint multi-task learning for multilingual neural translation of morphologically rich languages we replace the attention mechanism with the sliding-window mechanism and operate the sequence to sequence neural translation model on the character-level rather than on the word-level. The story segmentation and storyline clustering problem is tackled by examining the low-dimensional vectors produced as a side-product of the neural translation process. The results of this paper describe a novel approach to the automatic story segmentation and storyline clustering problem.
Polysemy in Controlled Natural Language Texts
Nov 20, 2015Computational semantics and logic-based controlled natural languages (CNL) do not address systematically the word sense disambiguation problem of content words, i.e., they tend to interpret only some functional words that are crucial for construction of discourse representation structures. We show that micro-ontologies and multi-word units allow integration of the rich and polysemous multi-domain background knowledge into CNL thus providing interpretation for the content words. The proposed approach is demonstrated by extending the Attempto Controlled English (ACE) with polysemous and procedural constructs resulting in a more natural CNL named PAO covering narrative multi-domain texts.
FrameNet Resource Grammar Library for GF
Jun 26, 2014
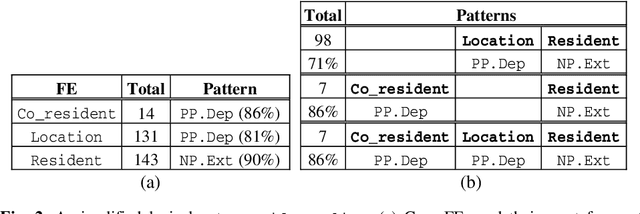
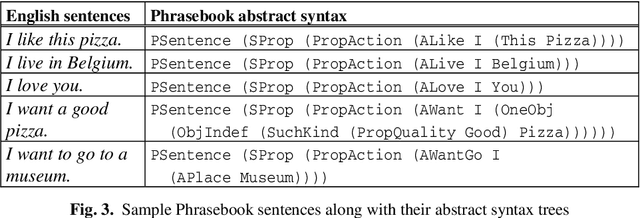

In this paper we present an ongoing research investigating the possibility and potential of integrating frame semantics, particularly FrameNet, in the Grammatical Framework (GF) application grammar development. An important component of GF is its Resource Grammar Library (RGL) that encapsulates the low-level linguistic knowledge about morphology and syntax of currently more than 20 languages facilitating rapid development of multilingual applications. In the ideal case, porting a GF application grammar to a new language would only require introducing the domain lexicon - translation equivalents that are interlinked via common abstract terms. While it is possible for a highly restricted CNL, developing and porting a less restricted CNL requires above average linguistic knowledge about the particular language, and above average GF experience. Specifying a lexicon is mostly straightforward in the case of nouns (incl. multi-word units), however, verbs are the most complex category (in terms of both inflectional paradigms and argument structure), and adding them to a GF application grammar is not a straightforward task. In this paper we are focusing on verbs, investigating the possibility of creating a multilingual FrameNet-based GF library. We propose an extension to the current RGL, allowing GF application developers to define clauses on the semantic level, thus leaving the language-specific syntactic mapping to this extension. We demonstrate our approach by reengineering the MOLTO Phrasebook application grammar.
FrameNet CNL: a Knowledge Representation and Information Extraction Language
Jun 10, 2014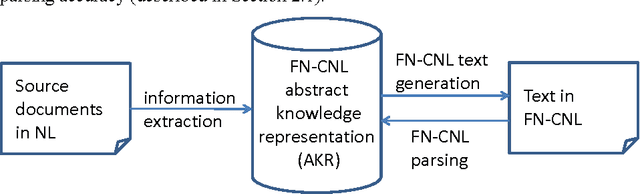
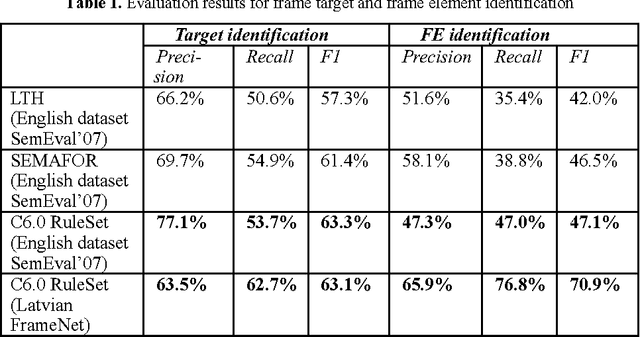
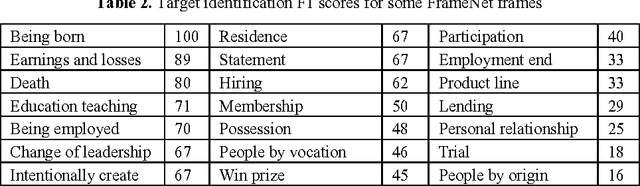

The paper presents a FrameNet-based information extraction and knowledge representation framework, called FrameNet-CNL. The framework is used on natural language documents and represents the extracted knowledge in a tailor-made Frame-ontology from which unambiguous FrameNet-CNL paraphrase text can be generated automatically in multiple languages. This approach brings together the fields of information extraction and CNL, because a source text can be considered belonging to FrameNet-CNL, if information extraction parser produces the correct knowledge representation as a result. We describe a state-of-the-art information extraction parser used by a national news agency and speculate that FrameNet-CNL eventually could shape the natural language subset used for writing the newswire articles.