 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Formal Models from Normative Texts
Jul 06, 2016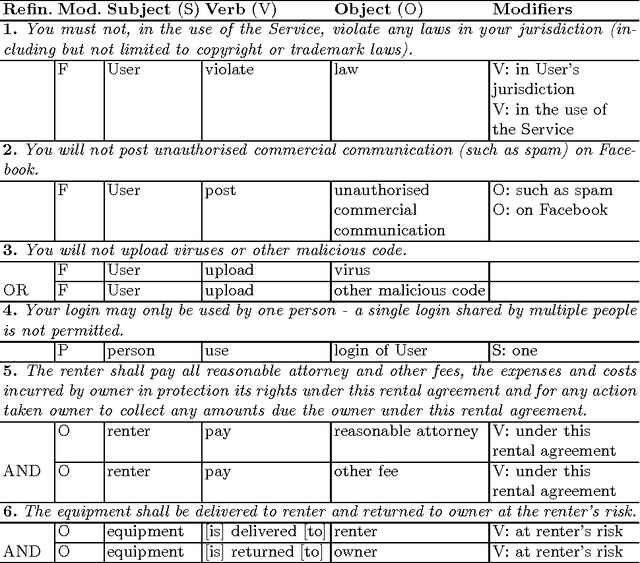
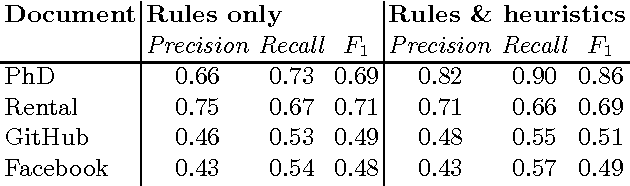
Normative texts are documents based on the deontic notions of obligation, permission, and prohibition. Our goal is to model such texts using the C-O Diagram formalism, making them amenable to formal analysis, in particular verifying that a text satisfies properties concerning causality of actions and timing constraints. We present an experimental, semi-automatic aid to bridge the gap between a normative text and its formal representation. Our approach uses dependency trees combined with our own rules and heuristics for extracting the relevant components. The resulting tabular data can then be converted into a C-O Diagram.
The Role of CNL and AMR in Scalable Abstractive Summarization for Multilingual Media Monitoring
Jun 20, 2016

In the era of Big Data and Deep Learning, there is a common view that machine learning approaches are the only way to cope with the robust and scalable information extraction and summarization. It has been recently proposed that the CNL approach could be scaled up, building on the concept of embedded CNL and, thus, allowing for CNL-based information extraction from e.g. normative or medical texts that are rather controlled by nature but still infringe the boundaries of CNL. Although it is arguable if CNL can be exploited to approach the robust wide-coverage semantic parsing for use cases like media monitoring, its potential becomes much more obvious in the opposite direction: generation of story highlights from the summarized AMR graphs, which is in the focus of this position paper.
* Proceedings of the 5th Workshop on Controlled Natural Language, 2016 (to appear)
Polysemy in Controlled Natural Language Texts
Nov 20, 2015Computational semantics and logic-based controlled natural languages (CNL) do not address systematically the word sense disambiguation problem of content words, i.e., they tend to interpret only some functional words that are crucial for construction of discourse representation structures. We show that micro-ontologies and multi-word units allow integration of the rich and polysemous multi-domain background knowledge into CNL thus providing interpretation for the content words. The proposed approach is demonstrated by extending the Attempto Controlled English (ACE) with polysemous and procedural constructs resulting in a more natural CNL named PAO covering narrative multi-domain texts.
A Multilingual FrameNet-based Grammar and Lexicon for Controlled Natural Language
Nov 12, 2015

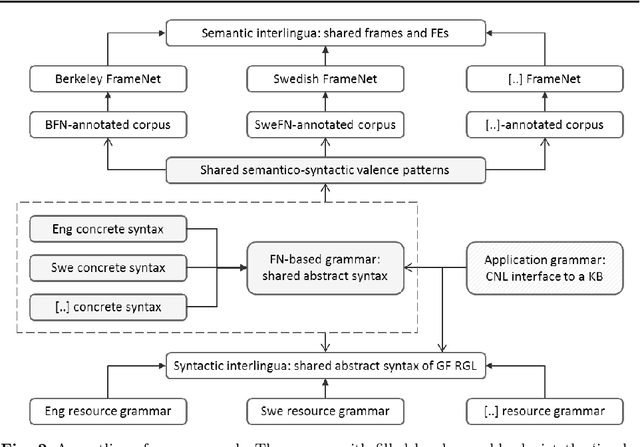
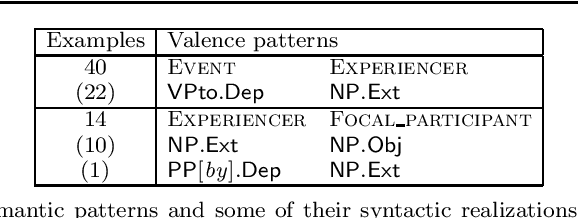
Berkeley FrameNet is a lexico-semantic resource for English based on the theory of frame semantics. It has been exploited in a range of natural language processing applications and has inspired the development of framenets for many languages. We present a methodological approach to the extraction and generation of a computational multilingual FrameNet-based grammar and lexicon. The approach leverages FrameNet-annotated corpora to automatically extract a set of cross-lingual semantico-syntactic valence patterns. Based on data from Berkeley FrameNet and Swedish FrameNet, the proposed approach has been implemented in Grammatical Framework (GF), a categorial grammar formalism specialized for multilingual grammars. The implementation of the grammar and lexicon is supported by the design of FrameNet, providing a frame semantic abstraction layer, an interlingual semantic API (application programming interface), over the interlingual syntactic API already provided by GF Resource Grammar Library. The evaluation of the acquired grammar and lexicon shows the feasibility of the approach. Additionally, we illustrate how the FrameNet-based grammar and lexicon are exploited in two distinct multilingual controlled natural language applications. The produced resources are available under an open source license.
FrameNet Resource Grammar Library for GF
Jun 26, 2014
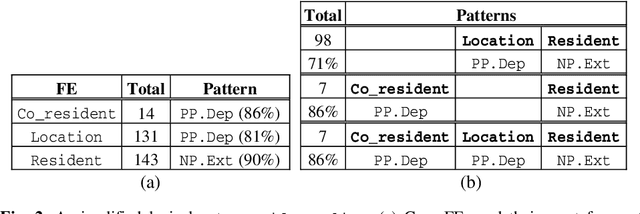
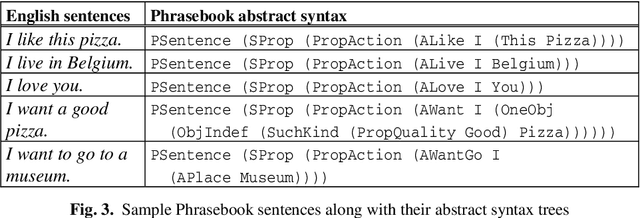

In this paper we present an ongoing research investigating the possibility and potential of integrating frame semantics, particularly FrameNet, in the Grammatical Framework (GF) application grammar development. An important component of GF is its Resource Grammar Library (RGL) that encapsulates the low-level linguistic knowledge about morphology and syntax of currently more than 20 languages facilitating rapid development of multilingual applications. In the ideal case, porting a GF application grammar to a new language would only require introducing the domain lexicon - translation equivalents that are interlinked via common abstract terms. While it is possible for a highly restricted CNL, developing and porting a less restricted CNL requires above average linguistic knowledge about the particular language, and above average GF experience. Specifying a lexicon is mostly straightforward in the case of nouns (incl. multi-word units), however, verbs are the most complex category (in terms of both inflectional paradigms and argument structure), and adding them to a GF application grammar is not a straightforward task. In this paper we are focusing on verbs, investigating the possibility of creating a multilingual FrameNet-based GF library. We propose an extension to the current RGL, allowing GF application developers to define clauses on the semantic level, thus leaving the language-specific syntactic mapping to this extension. We demonstrate our approach by reengineering the MOLTO Phrasebook application grammar.