 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Move Objects with Fluid Streams in a Differentiable Simulation
Apr 28, 2024We introduce a method for manipulating objects in three-dimensional space using controlled fluid streams. To achieve this, we train a neural network controller in a differentiable simulation and evaluate it in a simulated environment consisting of an 8x8 grid of vertical emitters. By carrying out various horizontal displacement tasks such as moving objects to specific positions while reacting to external perturbations, we demonstrate that a controller, trained with a limited number of iterations, can generalise to longer episodes and learn the complex dynamics of fluid-solid interactions. Importantly, our approach requires only the observation of the manipulated object's state, paving the way for the development of physical systems that enable contactless manipulation of objects using air streams.
Discrete Denoising Diffusion Approach to Integer Factorization
Sep 11, 2023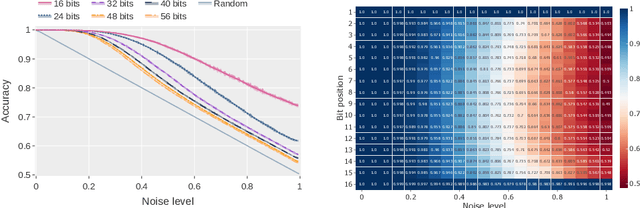
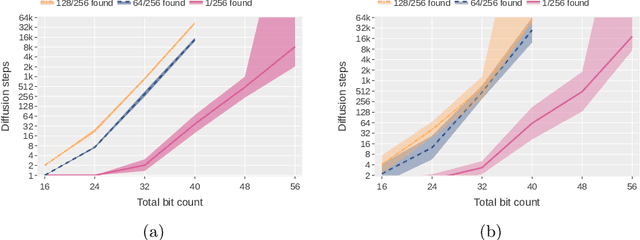
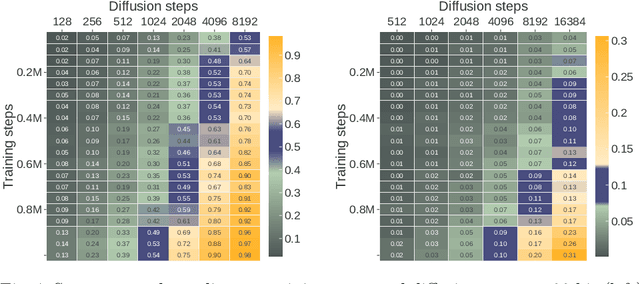
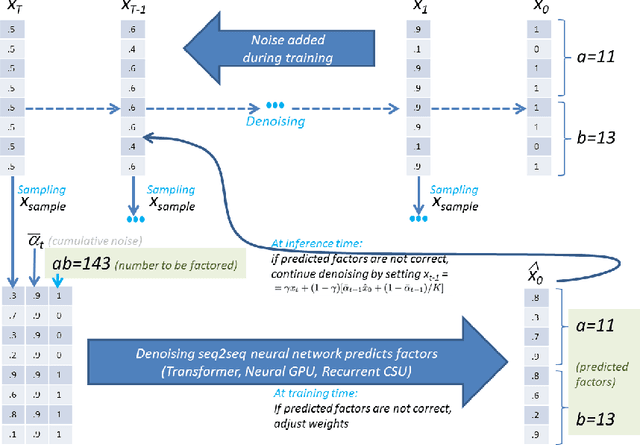
Integer factorization is a famous computational problem unknown whether being solvable in the polynomial time. With the rise of deep neural networks, it is interesting whether they can facilitate faster factorization. We present an approach to factorization utilizing deep neural networks and discrete denoising diffusion that works by iteratively correcting errors in a partially-correct solution. To this end, we develop a new seq2seq neural network architecture, employ relaxed categorical distribution and adapt the reverse diffusion process to cope better with inaccuracies in the denoising step. The approach is able to find factors for integers of up to 56 bits long. Our analysis indicates that investment in training leads to an exponential decrease of sampling steps required at inference to achieve a given success rate, thus counteracting an exponential run-time increase depending on the bit-length.
Denoising Diffusion for Sampling SAT Solutions
Nov 30, 2022
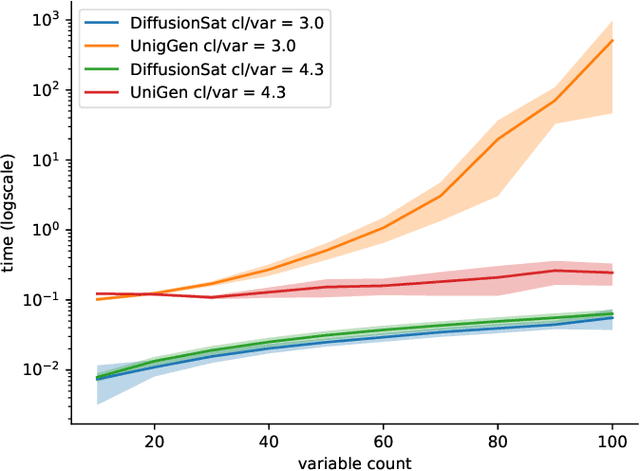
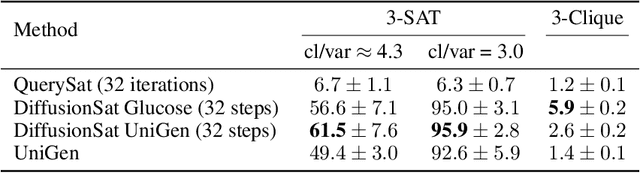

Generating diverse solutions to the Boolean Satisfiability Problem (SAT) is a hard computational problem with practical applications for testing and functional verification of software and hardware designs. We explore the way to generate such solutions using Denoising Diffusion coupled with a Graph Neural Network to implement the denoising function. We find that the obtained accuracy is similar to the currently best purely neural method and the produced SAT solutions are highly diverse, even if the system is trained with non-random solutions from a standard solver.
Gates are not what you need in RNNs
Aug 01, 2021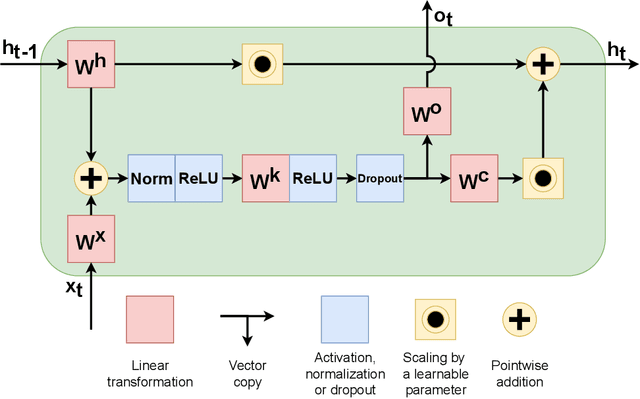
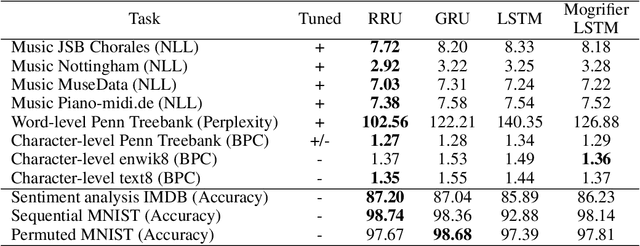
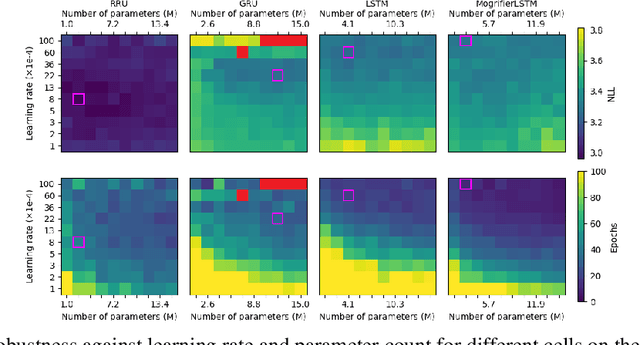
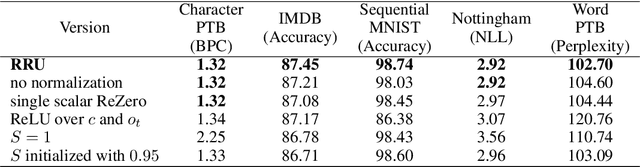
Recurrent neural networks have flourished in many areas. Consequently, we can see new RNN cells being developed continuously, usually by creating or using gates in a new, original way. But what if we told you that gates in RNNs are redundant? In this paper, we propose a new recurrent cell called Residual Recurrent Unit (RRU) which beats traditional cells and does not employ a single gate. It is based on the residual shortcut connection together with linear transformations, ReLU, and normalization. To evaluate our cell's effectiveness, we compare its performance against the widely-used GRU and LSTM cells and the recently proposed Mogrifier LSTM on several tasks including, polyphonic music modeling, language modeling, and sentiment analysis. Our experiments show that RRU outperforms the traditional gated units on most of these tasks. Also, it has better robustness to parameter selection, allowing immediate application in new tasks without much tuning. We have implemented the RRU in TensorFlow, and the code is made available at https://github.com/LUMII-Syslab/RRU .
Goal-Aware Neural SAT Solver
Jun 14, 2021Modern neural networks obtain information about the problem and calculate the output solely from the input values. We argue that it is not always optimal, and the network's performance can be significantly improved by augmenting it with a query mechanism that allows the network to make several solution trials at run time and get feedback on the loss value on each trial. To demonstrate the capabilities of the query mechanism, we formulate an unsupervised (not dependant on labels) loss function for Boolean Satisfiability Problem (SAT) and theoretically show that it allows the network to extract rich information about the problem. We then propose a neural SAT solver with a query mechanism called QuerySAT and show that it outperforms the neural baseline on a wide range of SAT tasks and the classical baselines on SHA-1 preimage attack and 3-SAT task.
Residual Shuffle-Exchange Networks for Fast Processing of Long Sequences
Apr 06, 2020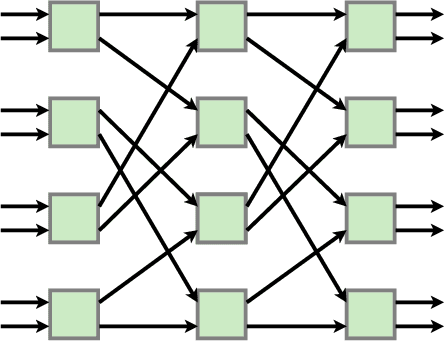

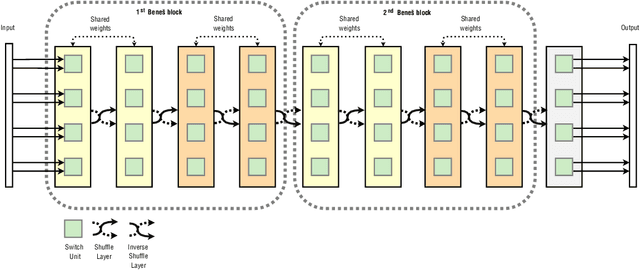

Attention is a commonly used mechanism in sequence processing, but it is of O(n^2) complexity which prevents its application to long sequences. The recently introduced Neural Shuffle-Exchange network offers a computation-efficient alternative, enabling the modelling of long-range dependencies in O(n log n) time. The model, however, is quite complex, involving a sophisticated gating mechanism derived from Gated Recurrent Unit. In this paper, we present a simple and lightweight variant of the Shuffle-Exchange network, which is based on a residual network employing GELU and Layer Normalization. The proposed architecture not only scales to longer sequences but also converges faster and provides better accuracy. It surpasses Shuffle-Exchange network on the LAMBADA language modelling task and achieves state-of-the-art performance on the MusicNet dataset for music transcription while using significantly fewer parameters. We show how to combine Shuffle-Exchange network with convolutional layers establishing it as a useful building block in long sequence processing applications.
A Statistical Method for Object Counting
Jul 22, 2018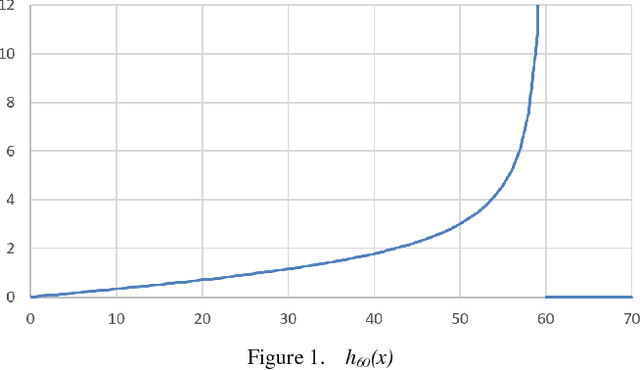
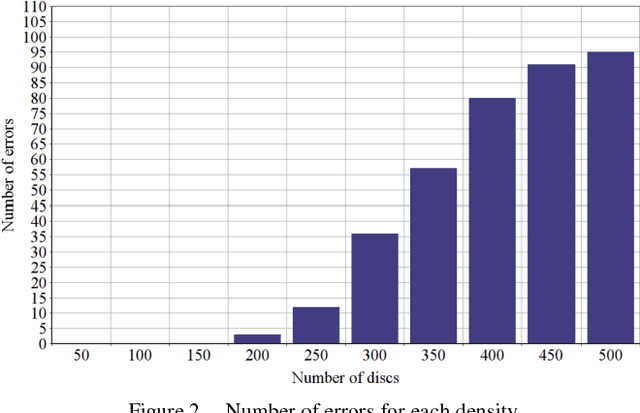
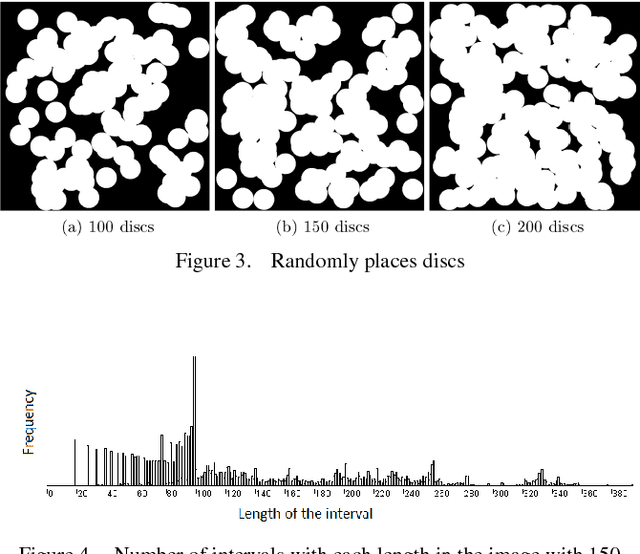
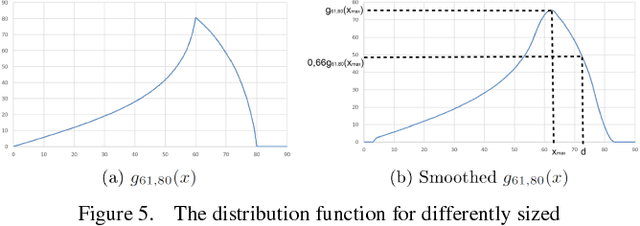
In this paper we present a new object counting method that is intended for counting similarly sized and mostly round objects. Unlike many other algorithms of the same purpose, the proposed method does not rely on identifying every object, it uses statistical data obtained from the image instead. The method is evaluated on images with human bone cells, oranges and pills achieving good accuracy. Its strengths are ability to deal with touching and partly overlapping objects, ability to work with different kinds of objects without prior configuration and good performance.
Improving the Neural GPU Architecture for Algorithm Learning
Jul 04, 2018



Algorithm learning is a core problem in artificial intelligence with significant implications on automation level that can be achieved by machines. Recently deep learning methods are emerging for synthesizing an algorithm from its input-output examples, the most successful being the Neural GPU, capable of learning multiplication. We present several improvements to the Neural GPU that substantially reduces training time and improves generalization. We introduce a new technique - hard nonlinearities with saturation costs- that has general applicability. We also introduce a technique of diagonal gates that can be applied to active-memory models. The proposed architecture is the first capable of learning decimal multiplication end-to-end.
* Minor edits