 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Shuffle-Exchange Networks for Fast Processing of Long Sequences
Apr 06, 2020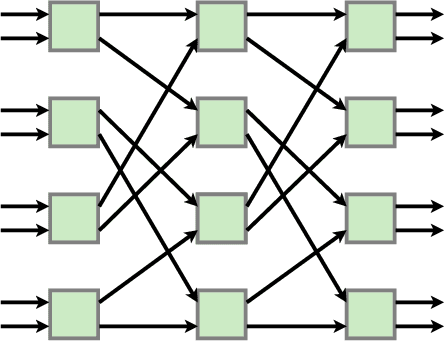

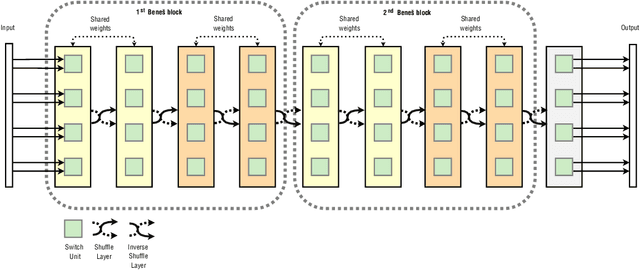

Attention is a commonly used mechanism in sequence processing, but it is of O(n^2) complexity which prevents its application to long sequences. The recently introduced Neural Shuffle-Exchange network offers a computation-efficient alternative, enabling the modelling of long-range dependencies in O(n log n) time. The model, however, is quite complex, involving a sophisticated gating mechanism derived from Gated Recurrent Unit. In this paper, we present a simple and lightweight variant of the Shuffle-Exchange network, which is based on a residual network employing GELU and Layer Normalization. The proposed architecture not only scales to longer sequences but also converges faster and provides better accuracy. It surpasses Shuffle-Exchange network on the LAMBADA language modelling task and achieves state-of-the-art performance on the MusicNet dataset for music transcription while using significantly fewer parameters. We show how to combine Shuffle-Exchange network with convolutional layers establishing it as a useful building block in long sequence processing applications.