 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Diagrammatic Queries in ViziQuer: Overview and Implementation
Apr 27, 2023



Knowledge graphs (KG) have become an important data organization paradigm. The available textual query languages for information retrieval from KGs, as SPARQL for RDF-structured data, do not provide means for involving non-technical experts in the data access process. Visual query formalisms, alongside form-based and natural language-based ones, offer means for easing user involvement in the data querying process. ViziQuer is a visual query notation and tool offering visual diagrammatic means for describing rich data queries, involving optional and negation constructs, as well as aggregation and subqueries. In this paper we review the visual ViziQuer notation from the end-user point of view and describe the conceptual and technical solutions (including abstract syntax model, followed by a generation model for textual queries) that allow mapping of the visual diagrammatic query notation into the textual SPARQL language, thus enabling the execution of rich visual queries over the actual knowledge graphs. The described solutions demonstrate the viability of the model-based approach in translating complex visual notation into a complex textual one; they serve as semantics by implementation description of the ViziQuer language and provide building blocks for further services in the ViziQuer tool context.
Switchblade -- a Neural Network for Hard 2D Tasks
Jun 29, 2020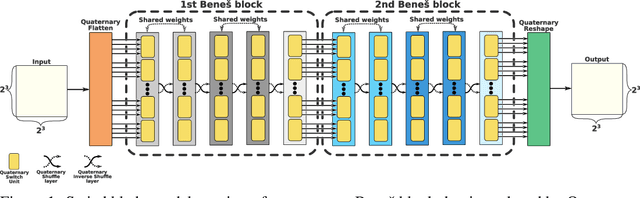

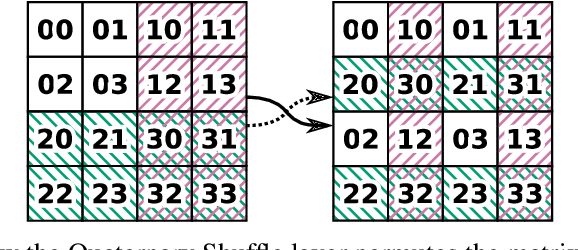
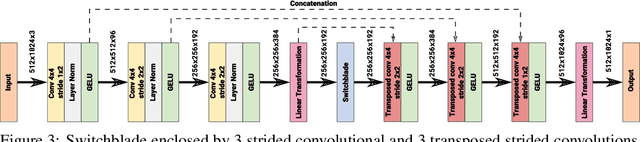
Convolutional neural networks have become the main tools for processing two-dimensional data. They work well for images, yet convolutions have a limited receptive field that prevents its applications to more complex 2D tasks. We propose a new neural network model, named Switchblade, that can efficiently exploit long-range dependencies in 2D data and solve much more challenging tasks. It has close-to-optimal $\mathcal{O}(n^2 \log{n})$ complexity for processing $n \times n$ data matrix. Besides the common image classification and segmentation, we consider a diverse set of algorithmic tasks on matrices and graphs. Switchblade can infer highly complex matrix squaring and graph triangle finding algorithms purely from input-output examples. We show that our model is likewise suitable for logical reasoning tasks -- it attains perfect accuracy on Sudoku puzzle solving. Additionally, we introduce a new dataset for predicting the checkmating move in chess on which our model achieves 72.5% accuracy.
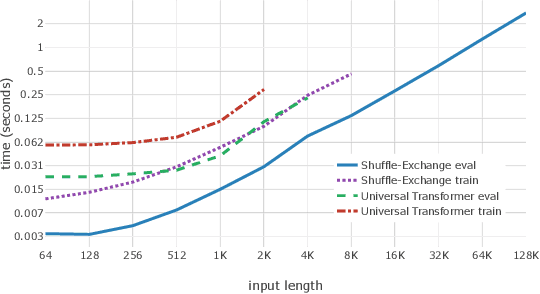
Residual Shuffle-Exchange Networks for Fast Processing of Long Sequences
Apr 06, 2020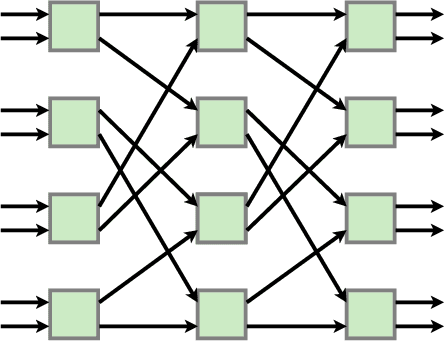

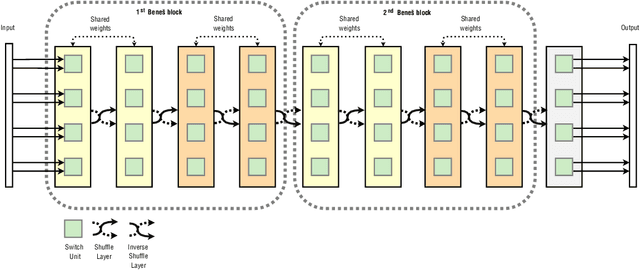

Attention is a commonly used mechanism in sequence processing, but it is of O(n^2) complexity which prevents its application to long sequences. The recently introduced Neural Shuffle-Exchange network offers a computation-efficient alternative, enabling the modelling of long-range dependencies in O(n log n) time. The model, however, is quite complex, involving a sophisticated gating mechanism derived from Gated Recurrent Unit. In this paper, we present a simple and lightweight variant of the Shuffle-Exchange network, which is based on a residual network employing GELU and Layer Normalization. The proposed architecture not only scales to longer sequences but also converges faster and provides better accuracy. It surpasses Shuffle-Exchange network on the LAMBADA language modelling task and achieves state-of-the-art performance on the MusicNet dataset for music transcription while using significantly fewer parameters. We show how to combine Shuffle-Exchange network with convolutional layers establishing it as a useful building block in long sequence processing applications.
Neural Shuffle-Exchange Networks -- Sequence Processing in O(n log n) Time
Jul 23, 2019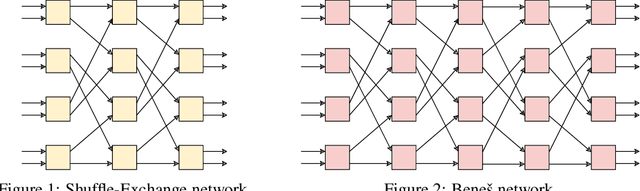

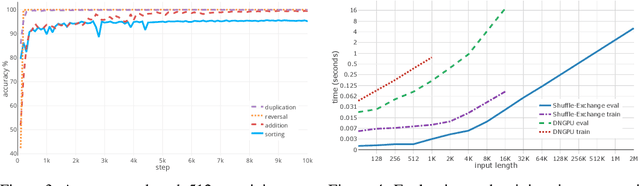
A key requirement in sequence to sequence processing is the modeling of long range dependencies. To this end, a vast majority of the state-of-the-art models use attention mechanism which is of O($n^2$) complexity that leads to slow execution for long sequences. We introduce a new Shuffle-Exchange neural network model for sequence to sequence tasks which have O(log n) depth and O(n log n) total complexity. We show that this model is powerful enough to infer efficient algorithms for common algorithmic benchmarks including sorting, addition and multiplication. We evaluate our architecture on the challenging LAMBADA question answering dataset and compare it with the state-of-the-art models which use attention. Our model achieves competitive accuracy and scales to sequences with more than a hundred thousand of elements. We are confident that the proposed model has the potential for building more efficient architectures for processing large interrelated data in language modeling, music generation and other application domains.