 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRIGA at SemEval-2016 Task 8: Impact of Smatch Extensions and Character-Level Neural Translation on AMR Parsing Accuracy
Apr 05, 2016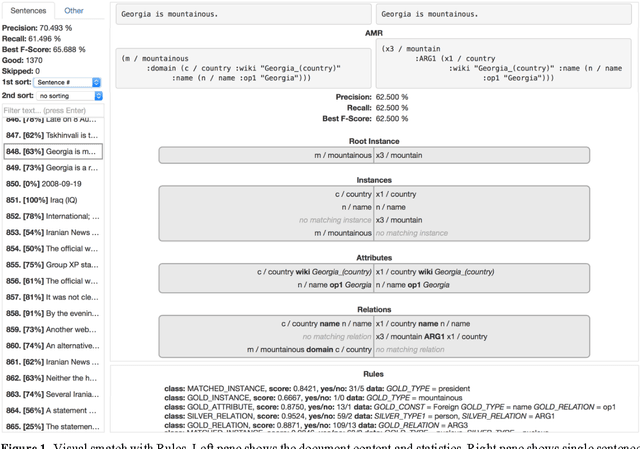
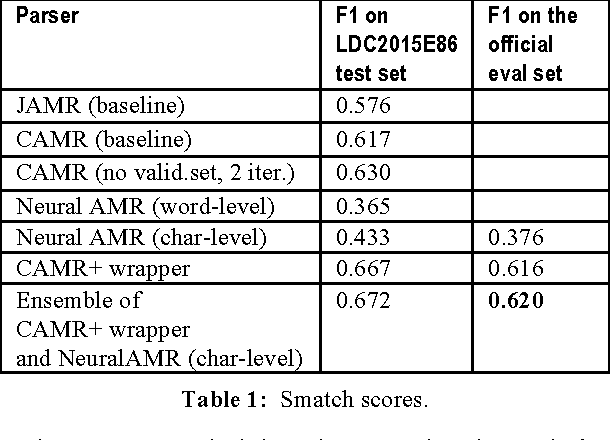
Two extensions to the AMR smatch scoring script are presented. The first extension com-bines the smatch scoring script with the C6.0 rule-based classifier to produce a human-readable report on the error patterns frequency observed in the scored AMR graphs. This first extension results in 4% gain over the state-of-art CAMR baseline parser by adding to it a manually crafted wrapper fixing the identified CAMR parser errors. The second extension combines a per-sentence smatch with an en-semble method for selecting the best AMR graph among the set of AMR graphs for the same sentence. This second modification au-tomatically yields further 0.4% gain when ap-plied to outputs of two nondeterministic AMR parsers: a CAMR+wrapper parser and a novel character-level neural translation AMR parser. For AMR parsing task the character-level neural translation attains surprising 7% gain over the carefully optimized word-level neural translation. Overall, we achieve smatch F1=62% on the SemEval-2016 official scor-ing set and F1=67% on the LDC2015E86 test set.
Character-Level Neural Translation for Multilingual Media Monitoring in the SUMMA Project
Apr 05, 2016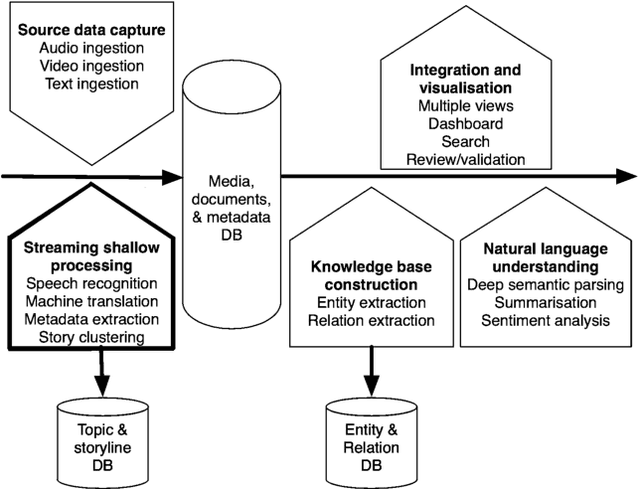


The paper steps outside the comfort-zone of the traditional NLP tasks like automatic speech recognition (ASR) and machine translation (MT) to addresses two novel problems arising in the automated multilingual news monitoring: segmentation of the TV and radio program ASR transcripts into individual stories, and clustering of the individual stories coming from various sources and languages into storylines. Storyline clustering of stories covering the same events is an essential task for inquisitorial media monitoring. We address these two problems jointly by engaging the low-dimensional semantic representation capabilities of the sequence to sequence neural translation models. To enable joint multi-task learning for multilingual neural translation of morphologically rich languages we replace the attention mechanism with the sliding-window mechanism and operate the sequence to sequence neural translation model on the character-level rather than on the word-level. The story segmentation and storyline clustering problem is tackled by examining the low-dimensional vectors produced as a side-product of the neural translation process. The results of this paper describe a novel approach to the automatic story segmentation and storyline clustering problem.