 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePriberam at MESINESP Multi-label Classification of Medical Texts Task
May 12, 2021

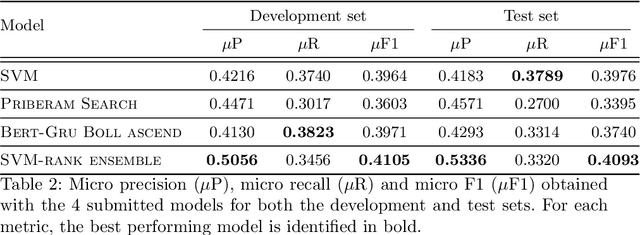
Medical articles provide current state of the art treatments and diagnostics to many medical practitioners and professionals. Existing public databases such as MEDLINE contain over 27 million articles, making it difficult to extract relevant content without the use of efficient search engines. Information retrieval tools are crucial in order to navigate and provide meaningful recommendations for articles and treatments. Classifying these articles into broader medical topics can improve the retrieval of related articles. The set of medical labels considered for the MESINESP task is on the order of several thousands of labels (DeCS codes), which falls under the extreme multi-label classification problem. The heterogeneous and highly hierarchical structure of medical topics makes the task of manually classifying articles extremely laborious and costly. It is, therefore, crucial to automate the process of classification. Typical machine learning algorithms become computationally demanding with such a large number of labels and achieving better recall on such datasets becomes an unsolved problem. This work presents Priberam's participation at the BioASQ task Mesinesp. We address the large multi-label classification problem through the use of four different models: a Support Vector Machine (SVM), a customised search engine (Priberam Search), a BERT based classifier, and a SVM-rank ensemble of all the previous models. Results demonstrate that all three individual models perform well and the best performance is achieved by their ensemble, granting Priberam the 6th place in the present challenge and making it the 2nd best team.
Priberam Labs at the NTCIR-15 SHINRA2020-ML: Classification Task
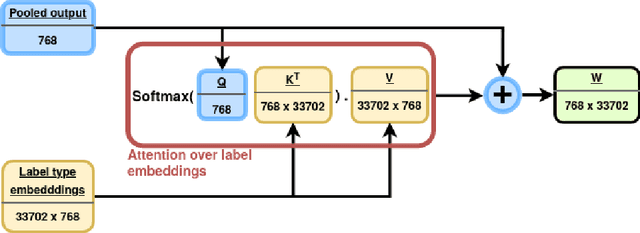
May 12, 2021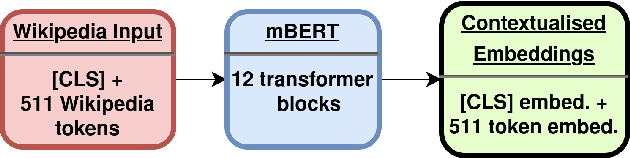
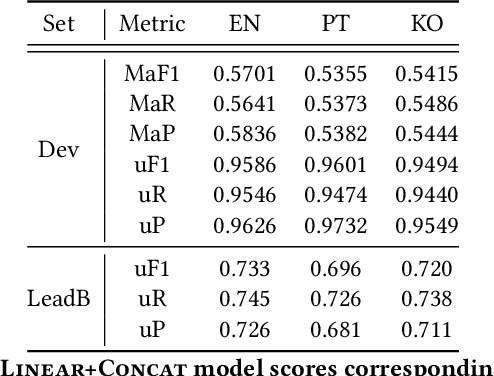
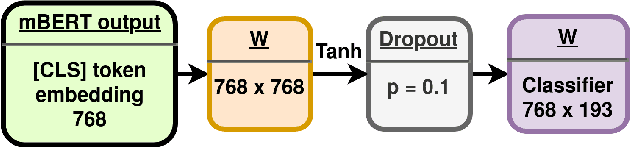
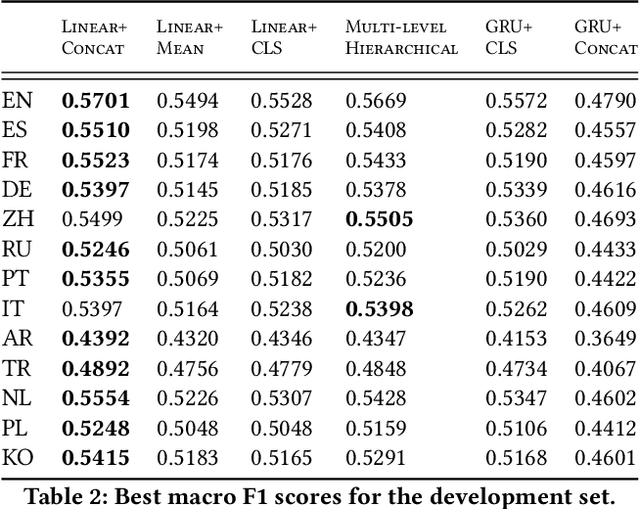
Wikipedia is an online encyclopedia available in 285 languages. It composes an extremely relevant Knowledge Base (KB), which could be leveraged by automatic systems for several purposes. However, the structure and organisation of such information are not prone to automatic parsing and understanding and it is, therefore, necessary to structure this knowledge. The goal of the current SHINRA2020-ML task is to leverage Wikipedia pages in order to categorise their corresponding entities across 268 hierarchical categories, belonging to the Extended Named Entity (ENE) ontology. In this work, we propose three distinct models based on the contextualised embeddings yielded by Multilingual BERT. We explore the performances of a linear layer with and without explicit usage of the ontology's hierarchy, and a Gated Recurrent Units (GRU) layer. We also test several pooling strategies to leverage BERT's embeddings and selection criteria based on the labels' scores. We were able to achieve good performance across a large variety of languages, including those not seen during the fine-tuning process (zero-shot languages).