 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChunk-based Nearest Neighbor Machine Translation
Paper and Code
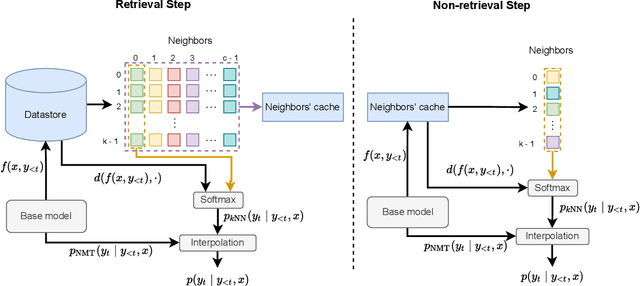
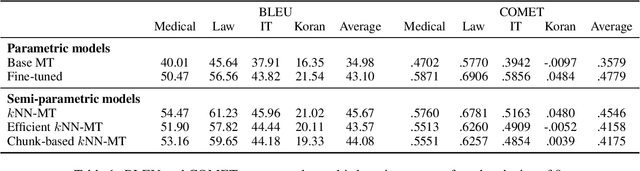
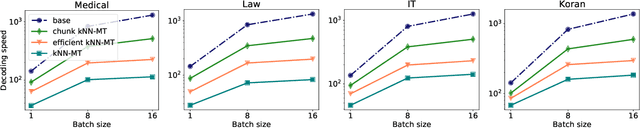
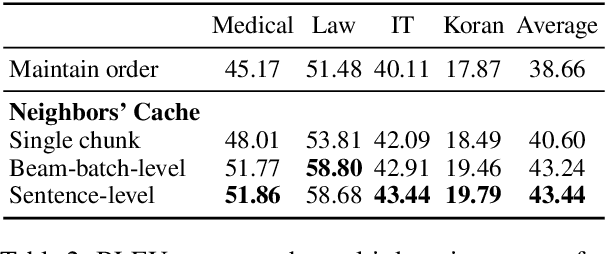
Semi-parametric models, which augment generation with retrieval, have led to impressive results in language modeling and machine translation, due to their ability to leverage information retrieved from a datastore of examples. One of the most prominent approaches, $k$NN-MT, has an outstanding performance on domain adaptation by retrieving tokens from a domain-specific datastore \citep{khandelwal2020nearest}. However, $k$NN-MT requires retrieval for every single generated token, leading to a very low decoding speed (around 8 times slower than a parametric model). In this paper, we introduce a \textit{chunk-based} $k$NN-MT model which retrieves chunks of tokens from the datastore, instead of a single token. We propose several strategies for incorporating the retrieved chunks into the generation process, and for selecting the steps at which the model needs to search for neighbors in the datastore. Experiments on machine translation in two settings, static domain adaptation and ``on-the-fly'' adaptation, show that the chunk-based $k$NN-MT model leads to a significant speed-up (up to 4 times) with only a small drop in translation quality.