 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataRater: Meta-Learned Dataset Curation
May 23, 2025The quality of foundation models depends heavily on their training data. Consequently, great efforts have been put into dataset curation. Yet most approaches rely on manual tuning of coarse-grained mixtures of large buckets of data, or filtering by hand-crafted heuristics. An approach that is ultimately more scalable (let alone more satisfying) is to \emph{learn} which data is actually valuable for training. This type of meta-learning could allow more sophisticated, fine-grained, and effective curation. Our proposed \emph{DataRater} is an instance of this idea. It estimates the value of training on any particular data point. This is done by meta-learning using `meta-gradients', with the objective of improving training efficiency on held out data. In extensive experiments across a range of model scales and datasets, we find that using our DataRater to filter data is highly effective, resulting in significantly improved compute efficiency.
Scalable Meta-Learning via Mixed-Mode Differentiation
May 01, 2025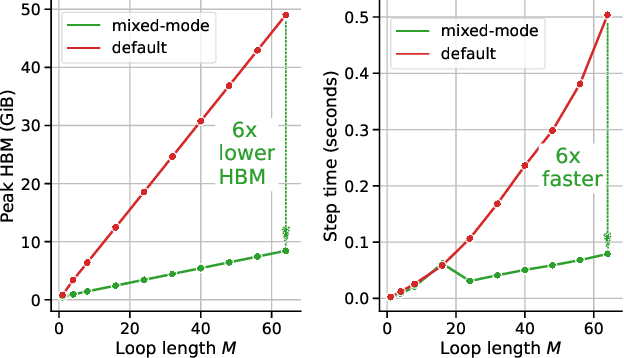
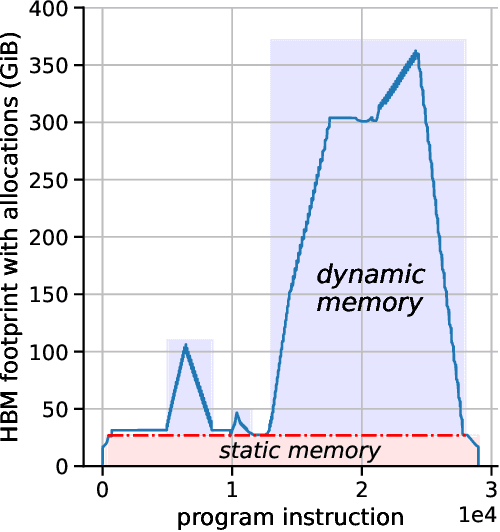
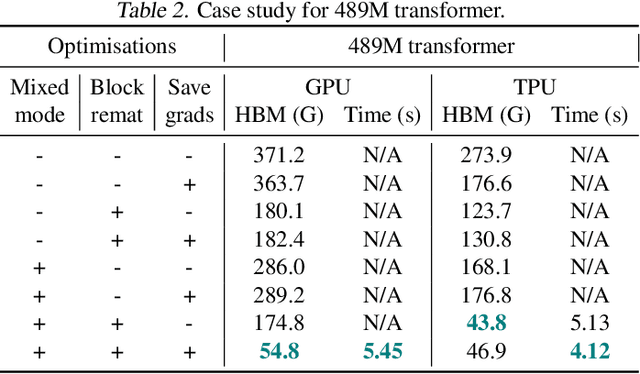
Gradient-based bilevel optimisation is a powerful technique with applications in hyperparameter optimisation, task adaptation, algorithm discovery, meta-learning more broadly, and beyond. It often requires differentiating through the gradient-based optimisation process itself, leading to "gradient-of-a-gradient" calculations with computationally expensive second-order and mixed derivatives. While modern automatic differentiation libraries provide a convenient way to write programs for calculating these derivatives, they oftentimes cannot fully exploit the specific structure of these problems out-of-the-box, leading to suboptimal performance. In this paper, we analyse such cases and propose Mixed-Flow Meta-Gradients, or MixFlow-MG -- a practical algorithm that uses mixed-mode differentiation to construct more efficient and scalable computational graphs yielding over 10x memory and up to 25% wall-clock time improvements over standard implementations in modern meta-learning setups.
Discovering General Reinforcement Learning Algorithms with Adversarial Environment Design
Oct 04, 2023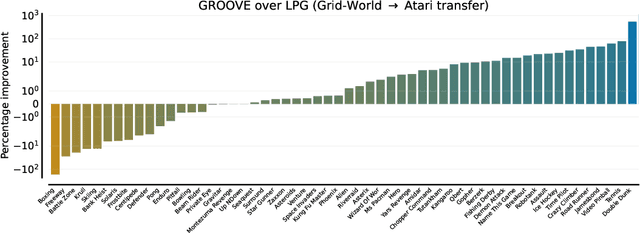
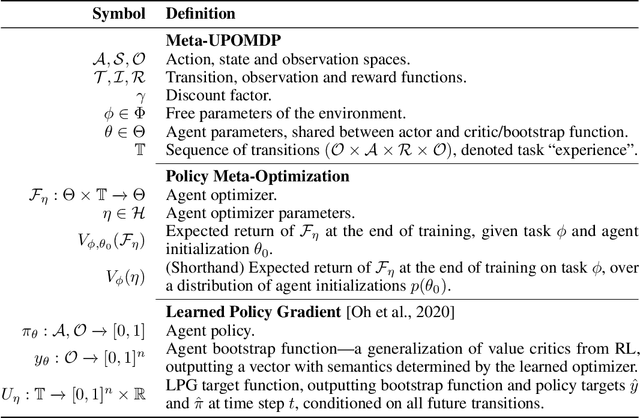
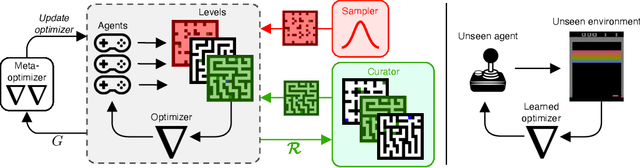

The past decade has seen vast progress in deep reinforcement learning (RL) on the back of algorithms manually designed by human researchers. Recently, it has been shown that it is possible to meta-learn update rules, with the hope of discovering algorithms that can perform well on a wide range of RL tasks. Despite impressive initial results from algorithms such as Learned Policy Gradient (LPG), there remains a generalization gap when these algorithms are applied to unseen environments. In this work, we examine how characteristics of the meta-training distribution impact the generalization performance of these algorithms. Motivated by this analysis and building on ideas from Unsupervised Environment Design (UED), we propose a novel approach for automatically generating curricula to maximize the regret of a meta-learned optimizer, in addition to a novel approximation of regret, which we name algorithmic regret (AR). The result is our method, General RL Optimizers Obtained Via Environment Design (GROOVE). In a series of experiments, we show that GROOVE achieves superior generalization to LPG, and evaluate AR against baseline metrics from UED, identifying it as a critical component of environment design in this setting. We believe this approach is a step towards the discovery of truly general RL algorithms, capable of solving a wide range of real-world environments.
An Investigation of the Bias-Variance Tradeoff in Meta-Gradients
Sep 22, 2022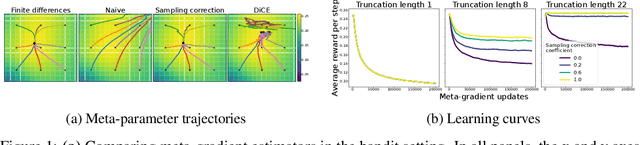



Meta-gradients provide a general approach for optimizing the meta-parameters of reinforcement learning (RL) algorithms. Estimation of meta-gradients is central to the performance of these meta-algorithms, and has been studied in the setting of MAML-style short-horizon meta-RL problems. In this context, prior work has investigated the estimation of the Hessian of the RL objective, as well as tackling the problem of credit assignment to pre-adaptation behavior by making a sampling correction. However, we show that Hessian estimation, implemented for example by DiCE and its variants, always adds bias and can also add variance to meta-gradient estimation. Meanwhile, meta-gradient estimation has been studied less in the important long-horizon setting, where backpropagation through the full inner optimization trajectories is not feasible. We study the bias and variance tradeoff arising from truncated backpropagation and sampling correction, and additionally compare to evolution strategies, which is a recently popular alternative strategy to long-horizon meta-learning. While prior work implicitly chooses points in this bias-variance space, we disentangle the sources of bias and variance and present an empirical study that relates existing estimators to each other.
Model-Value Inconsistency as a Signal for Epistemic Uncertainty
Dec 08, 2021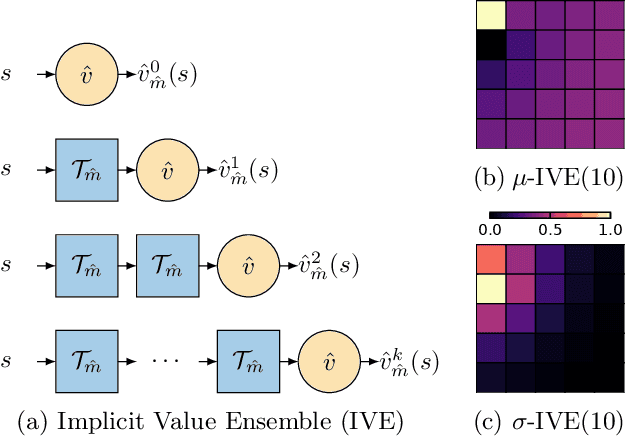

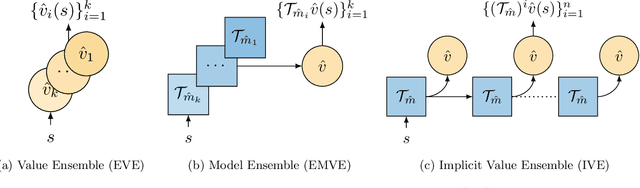
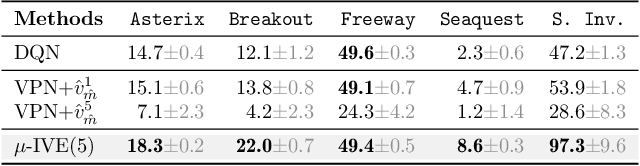
Using a model of the environment and a value function, an agent can construct many estimates of a state's value, by unrolling the model for different lengths and bootstrapping with its value function. Our key insight is that one can treat this set of value estimates as a type of ensemble, which we call an \emph{implicit value ensemble} (IVE). Consequently, the discrepancy between these estimates can be used as a proxy for the agent's epistemic uncertainty; we term this signal \emph{model-value inconsistency} or \emph{self-inconsistency} for short. Unlike prior work which estimates uncertainty by training an ensemble of many models and/or value functions, this approach requires only the single model and value function which are already being learned in most model-based reinforcement learning algorithms. We provide empirical evidence in both tabular and function approximation settings from pixels that self-inconsistency is useful (i) as a signal for exploration, (ii) for acting safely under distribution shifts, and (iii) for robustifying value-based planning with a model.
Self-Consistent Models and Values
Oct 25, 2021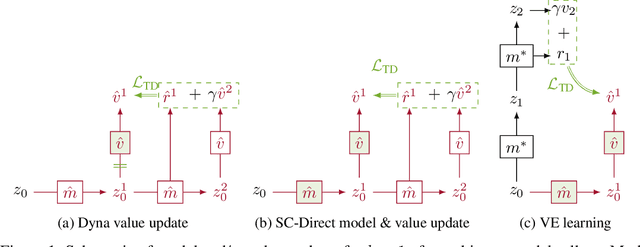

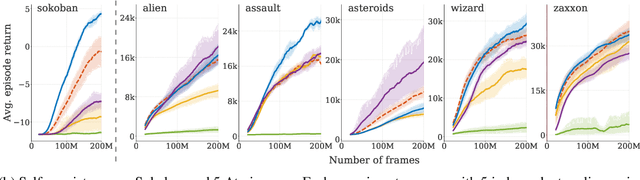
Learned models of the environment provide reinforcement learning (RL) agents with flexible ways of making predictions about the environment. In particular, models enable planning, i.e. using more computation to improve value functions or policies, without requiring additional environment interactions. In this work, we investigate a way of augmenting model-based RL, by additionally encouraging a learned model and value function to be jointly \emph{self-consistent}. Our approach differs from classic planning methods such as Dyna, which only update values to be consistent with the model. We propose multiple self-consistency updates, evaluate these in both tabular and function approximation settings, and find that, with appropriate choices, self-consistency helps both policy evaluation and control.
Proper Value Equivalence
Jun 18, 2021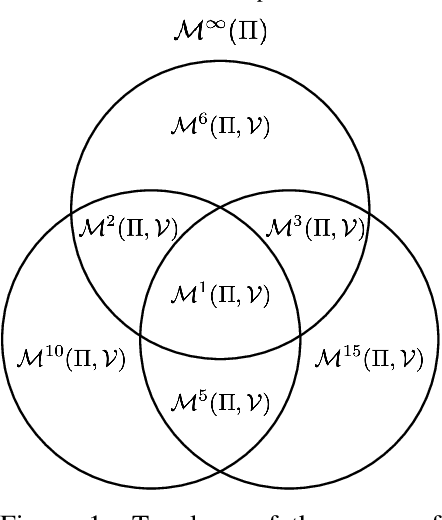

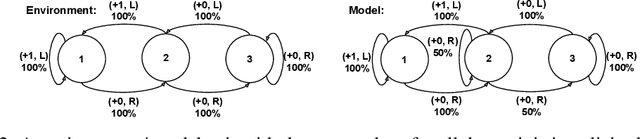
One of the main challenges in model-based reinforcement learning (RL) is to decide which aspects of the environment should be modeled. The value-equivalence (VE) principle proposes a simple answer to this question: a model should capture the aspects of the environment that are relevant for value-based planning. Technically, VE distinguishes models based on a set of policies and a set of functions: a model is said to be VE to the environment if the Bellman operators it induces for the policies yield the correct result when applied to the functions. As the number of policies and functions increase, the set of VE models shrinks, eventually collapsing to a single point corresponding to a perfect model. A fundamental question underlying the VE principle is thus how to select the smallest sets of policies and functions that are sufficient for planning. In this paper we take an important step towards answering this question. We start by generalizing the concept of VE to order-$k$ counterparts defined with respect to $k$ applications of the Bellman operator. This leads to a family of VE classes that increase in size as $k \rightarrow \infty$. In the limit, all functions become value functions, and we have a special instantiation of VE which we call proper VE or simply PVE. Unlike VE, the PVE class may contain multiple models even in the limit when all value functions are used. Crucially, all these models are sufficient for planning, meaning that they will yield an optimal policy despite the fact that they may ignore many aspects of the environment. We construct a loss function for learning PVE models and argue that popular algorithms such as MuZero and Muesli can be understood as minimizing an upper bound for this loss. We leverage this connection to propose a modification to MuZero and show that it can lead to improved performance in practice.
PsiPhi-Learning: Reinforcement Learning with Demonstrations using Successor Features and Inverse Temporal Difference Learning
Feb 24, 2021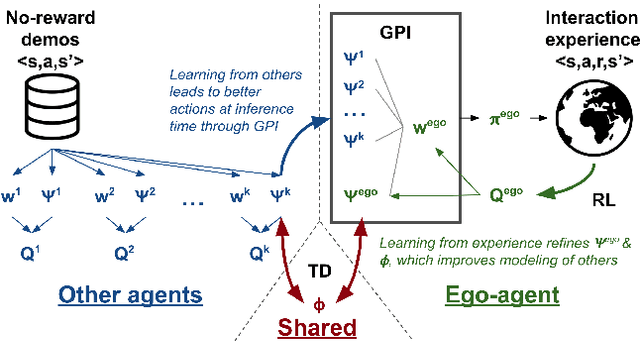



We study reinforcement learning (RL) with no-reward demonstrations, a setting in which an RL agent has access to additional data from the interaction of other agents with the same environment. However, it has no access to the rewards or goals of these agents, and their objectives and levels of expertise may vary widely. These assumptions are common in multi-agent settings, such as autonomous driving. To effectively use this data, we turn to the framework of successor features. This allows us to disentangle shared features and dynamics of the environment from agent-specific rewards and policies. We propose a multi-task inverse reinforcement learning (IRL) algorithm, called \emph{inverse temporal difference learning} (ITD), that learns shared state features, alongside per-agent successor features and preference vectors, purely from demonstrations without reward labels. We further show how to seamlessly integrate ITD with learning from online environment interactions, arriving at a novel algorithm for reinforcement learning with demonstrations, called $\Psi \Phi$-learning (pronounced `Sci-Fi'). We provide empirical evidence for the effectiveness of $\Psi \Phi$-learning as a method for improving RL, IRL, imitation, and few-shot transfer, and derive worst-case bounds for its performance in zero-shot transfer to new tasks.
Weighted QMIX: Expanding Monotonic Value Function Factorisation
Jun 18, 2020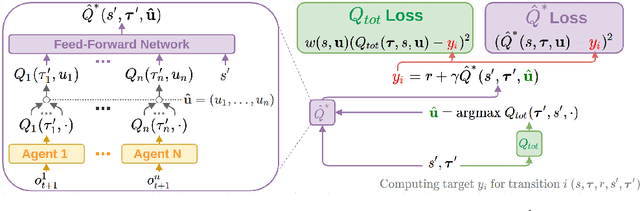
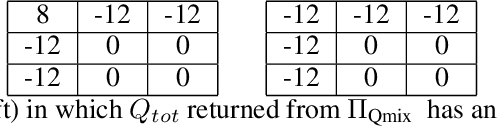
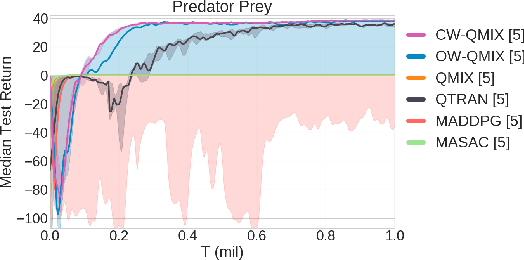

QMIX is a popular $Q$-learning algorithm for cooperative MARL in the centralised training and decentralised execution paradigm. In order to enable easy decentralisation, QMIX restricts the joint action $Q$-values it can represent to be a monotonic mixing of each agent's utilities. However, this restriction prevents it from representing value functions in which an agent's ordering over its actions can depend on other agents' actions. To analyse this representational limitation, we first formalise the objective QMIX optimises, which allows us to view QMIX as an operator that first computes the $Q$-learning targets and then projects them into the space representable by QMIX. This projection returns a representable $Q$-value that minimises the unweighted squared error across all joint actions. We show in particular that this projection can fail to recover the optimal policy even with access to $Q^*$, which primarily stems from the equal weighting placed on each joint action. We rectify this by introducing a weighting into the projection, in order to place more importance on the better joint actions. We propose two weighting schemes and prove that they recover the correct maximal action for any joint action $Q$-values, and therefore for $Q^*$ as well. Based on our analysis and results in the tabular setting we introduce two scalable versions of our algorithm, Centrally-Weighted (CW) QMIX and Optimistically-Weighted (OW) QMIX and demonstrate improved performance on both predator-prey and challenging multi-agent StarCraft benchmark tasks.
The Impact of Non-stationarity on Generalisation in Deep Reinforcement Learning
Jun 16, 2020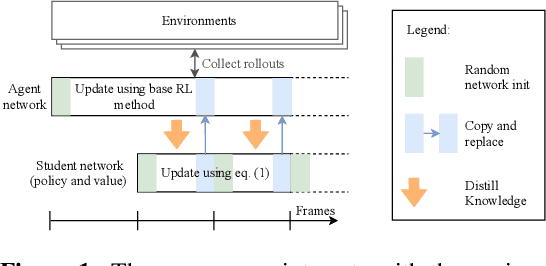
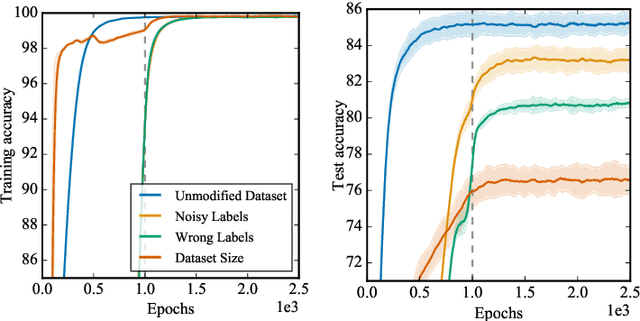
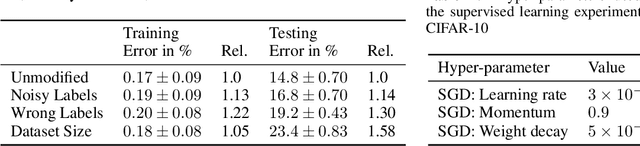
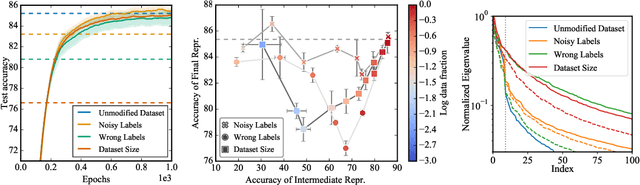
Non-stationarity arises in Reinforcement Learning (RL) even in stationary environments. Most RL algorithms collect new data throughout training, using a non-stationary behaviour policy. Furthermore, training targets in RL can change even with a fixed state distribution when the policy, critic, or bootstrap values are updated. We study these types of non-stationarity in supervised learning settings as well as in RL, finding that they can lead to worse generalisation performance when using deep neural network function approximators. Consequently, to improve generalisation of deep RL agents, we propose Iterated Relearning (ITER). ITER augments standard RL training by repeated knowledge transfer of the current policy into a freshly initialised network, which thereby experiences less non-stationarity during training. Experimentally, we show that ITER improves performance on the challenging generalisation benchmarks ProcGen and Multiroom.