 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Transformer Decoder for Automotive Radar Object Detection
Jan 19, 2026In this paper, we present a Transformer-based architecture for 3D radar object detection that uses a novel Transformer Decoder as the prediction head to directly regress 3D bounding boxes and class scores from radar feature representations. To bridge multi-scale radar features and the decoder, we propose Pyramid Token Fusion (PTF), a lightweight module that converts a feature pyramid into a unified, scale-aware token sequence. By formulating detection as a set prediction problem with learnable object queries and positional encodings, our design models long-range spatial-temporal correlations and cross-feature interactions. This approach eliminates dense proposal generation and heuristic post-processing such as extensive non-maximum suppression (NMS) tuning. We evaluate the proposed framework on the RADDet, where it achieves significant improvements over state-of-the-art radar-only baselines.
Synthetic FMCW Radar Range Azimuth Maps Augmentation with Generative Diffusion Model
Jan 09, 2026The scarcity and low diversity of well-annotated automotive radar datasets often limit the performance of deep-learning-based environmental perception. To overcome these challenges, we propose a conditional generative framework for synthesizing realistic Frequency-Modulated Continuous-Wave radar Range-Azimuth Maps. Our approach leverages a generative diffusion model to generate radar data for multiple object categories, including pedestrians, cars, and cyclists. Specifically, conditioning is achieved via Confidence Maps, where each channel represents a semantic class and encodes Gaussian-distributed annotations at target locations. To address radar-specific characteristics, we incorporate Geometry Aware Conditioning and Temporal Consistency Regularization into the generative process. Experiments on the ROD2021 dataset demonstrate that signal reconstruction quality improves by \SI{3.6}{dB} in Peak Signal-to-Noise Ratio over baseline methods, while training with a combination of real and synthetic datasets improves overall mean Average Precision by 4.15% compared with conventional image-processing-based augmentation. These results indicate that our generative framework not only produces physically plausible and diverse radar spectrum but also substantially improves model generalization in downstream tasks.
Proper Value Equivalence
Jun 18, 2021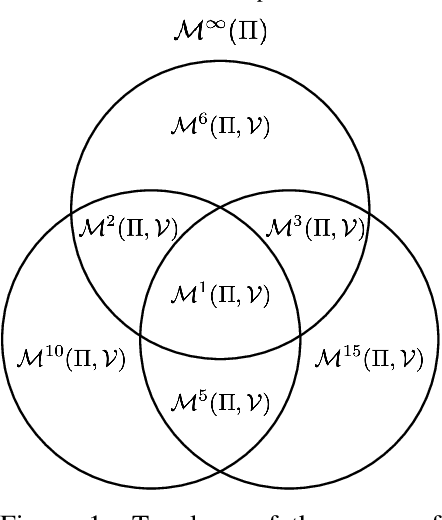

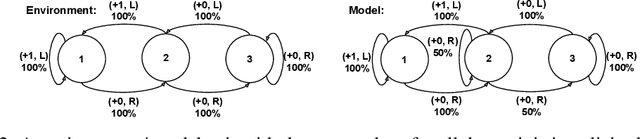
One of the main challenges in model-based reinforcement learning (RL) is to decide which aspects of the environment should be modeled. The value-equivalence (VE) principle proposes a simple answer to this question: a model should capture the aspects of the environment that are relevant for value-based planning. Technically, VE distinguishes models based on a set of policies and a set of functions: a model is said to be VE to the environment if the Bellman operators it induces for the policies yield the correct result when applied to the functions. As the number of policies and functions increase, the set of VE models shrinks, eventually collapsing to a single point corresponding to a perfect model. A fundamental question underlying the VE principle is thus how to select the smallest sets of policies and functions that are sufficient for planning. In this paper we take an important step towards answering this question. We start by generalizing the concept of VE to order-$k$ counterparts defined with respect to $k$ applications of the Bellman operator. This leads to a family of VE classes that increase in size as $k \rightarrow \infty$. In the limit, all functions become value functions, and we have a special instantiation of VE which we call proper VE or simply PVE. Unlike VE, the PVE class may contain multiple models even in the limit when all value functions are used. Crucially, all these models are sufficient for planning, meaning that they will yield an optimal policy despite the fact that they may ignore many aspects of the environment. We construct a loss function for learning PVE models and argue that popular algorithms such as MuZero and Muesli can be understood as minimizing an upper bound for this loss. We leverage this connection to propose a modification to MuZero and show that it can lead to improved performance in practice.
Warping of Radar Data into Camera Image for Cross-Modal Supervision in Automotive Applications
Dec 23, 2020



In this paper, we present a novel framework to project automotive radar range-Doppler (RD) spectrum into camera image. The utilized warping operation is designed to be fully differentiable, which allows error backpropagation through the operation. This enables the training of neural networks (NN) operating exclusively on RD spectrum by utilizing labels provided from camera vision models. As the warping operation relies on accurate scene flow, additionally, we present a novel scene flow estimation algorithm fed from camera, lidar and radar, enabling us to improve the accuracy of the warping operation. We demonstrate the framework in multiple applications like direction-of-arrival (DoA) estimation, target detection, semantic segmentation and estimation of radar power from camera data. Extensive evaluations have been carried out for the DoA application and suggest superior quality for NN based estimators compared to classical estimators. The novel scene flow estimation approach is benchmarked against state-of-the-art scene flow algorithms and outperforms them by roughly a third.
The Value Equivalence Principle for Model-Based Reinforcement Learning
Nov 06, 2020
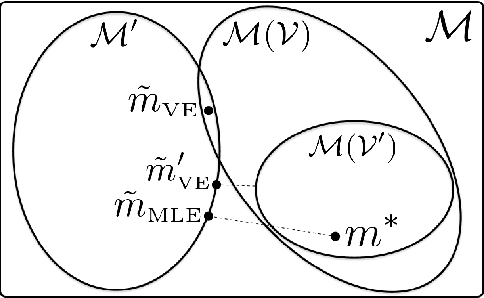
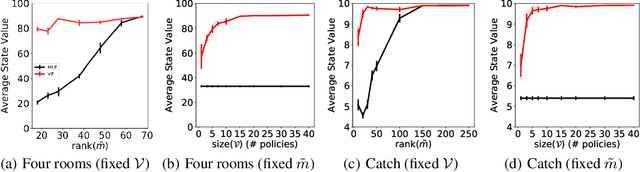
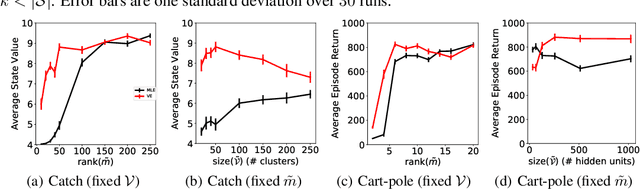
Learning models of the environment from data is often viewed as an essential component to building intelligent reinforcement learning (RL) agents. The common practice is to separate the learning of the model from its use, by constructing a model of the environment's dynamics that correctly predicts the observed state transitions. In this paper we argue that the limited representational resources of model-based RL agents are better used to build models that are directly useful for value-based planning. As our main contribution, we introduce the principle of value equivalence: two models are value equivalent with respect to a set of functions and policies if they yield the same Bellman updates. We propose a formulation of the model learning problem based on the value equivalence principle and analyze how the set of feasible solutions is impacted by the choice of policies and functions. Specifically, we show that, as we augment the set of policies and functions considered, the class of value equivalent models shrinks, until eventually collapsing to a single point corresponding to a model that perfectly describes the environment. In many problems, directly modelling state-to-state transitions may be both difficult and unnecessary. By leveraging the value-equivalence principle one may find simpler models without compromising performance, saving computation and memory. We illustrate the benefits of value-equivalent model learning with experiments comparing it against more traditional counterparts like maximum likelihood estimation. More generally, we argue that the principle of value equivalence underlies a number of recent empirical successes in RL, such as Value Iteration Networks, the Predictron, Value Prediction Networks, TreeQN, and MuZero, and provides a first theoretical underpinning of those results.
Disentangled Cumulants Help Successor Representations Transfer to New Tasks
Nov 25, 2019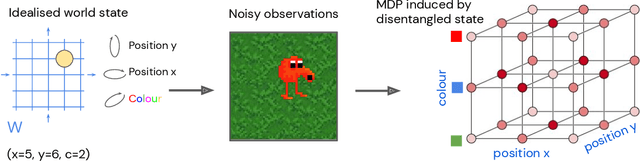
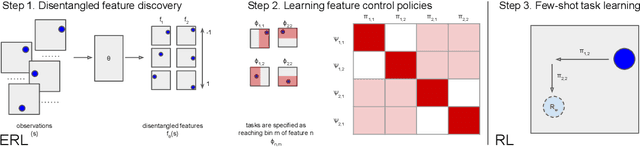
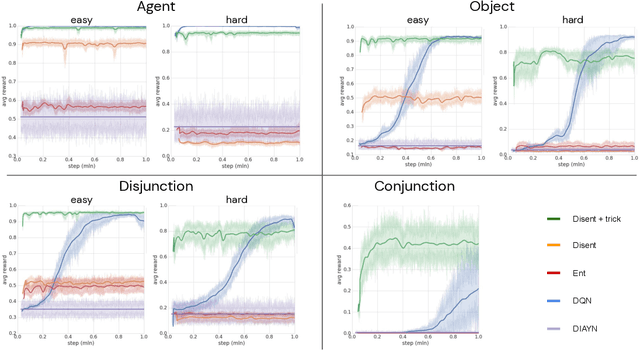
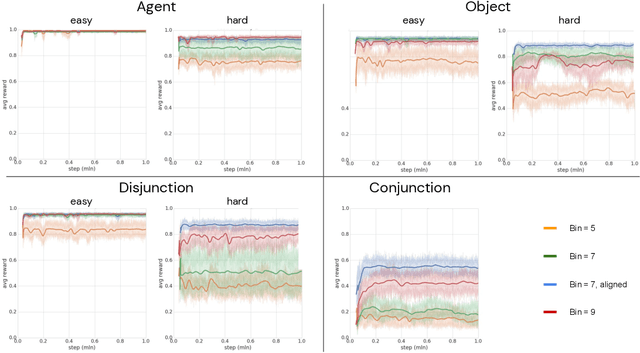
Biological intelligence can learn to solve many diverse tasks in a data efficient manner by re-using basic knowledge and skills from one task to another. Furthermore, many of such skills are acquired without explicit supervision in an intrinsically driven fashion. This is in contrast to the state-of-the-art reinforcement learning agents, which typically start learning each new task from scratch and struggle with knowledge transfer. In this paper we propose a principled way to learn a basis set of policies, which, when recombined through generalised policy improvement, come with guarantees on the coverage of the final task space. In particular, we concentrate on solving goal-based downstream tasks where the execution order of actions is not important. We demonstrate both theoretically and empirically that learning a small number of policies that reach intrinsically specified goal regions in a disentangled latent space can be re-used to quickly achieve a high level of performance on an exponentially larger number of externally specified, often significantly more complex downstream tasks. Our learning pipeline consists of two stages. First, the agent learns to perform intrinsically generated, goal-based tasks in the total absence of environmental rewards. Second, the agent leverages this experience to quickly achieve a high level of performance on numerous diverse externally specified tasks.
Learning Independently-Obtainable Reward Functions
Jan 31, 2019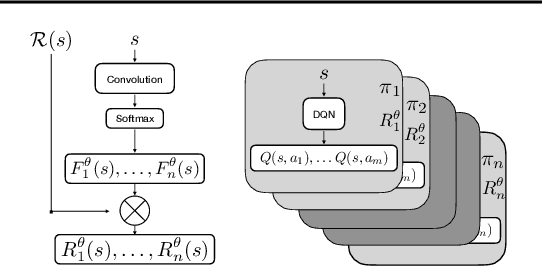
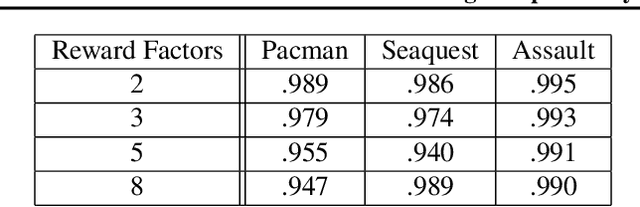
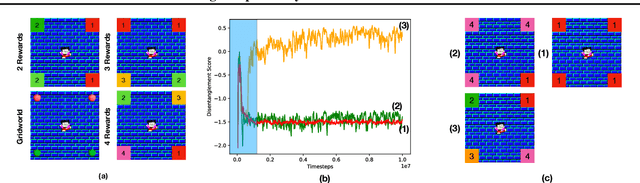
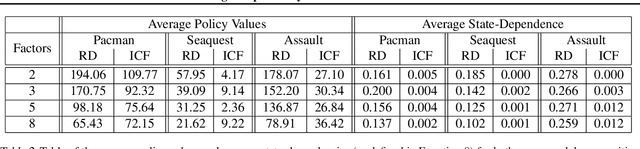
We present a novel method for learning a set of disentangled reward functions that sum to the original environment reward and are constrained to be independently obtainable. We define independent obtainability in terms of value functions with respect to obtaining one learned reward while pursuing another learned reward. Empirically, we illustrate that our method can learn meaningful reward decompositions in a variety of domains and that these decompositions exhibit some form of generalization performance when the environment's reward is modified. Theoretically, we derive results about the effect of maximizing our method's objective on the resulting reward functions and their corresponding optimal policies.
Mitigating Planner Overfitting in Model-Based Reinforcement Learning
Dec 03, 2018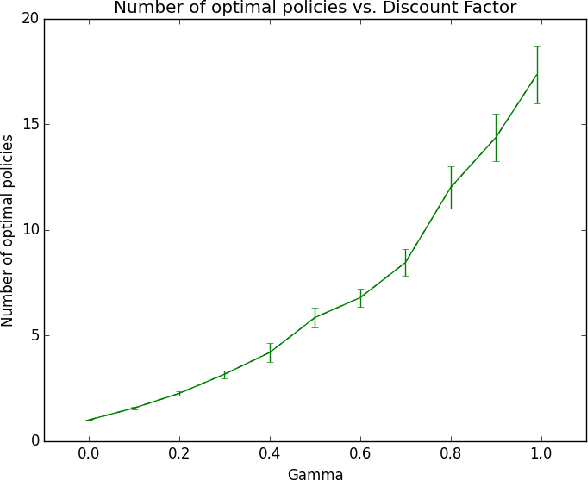
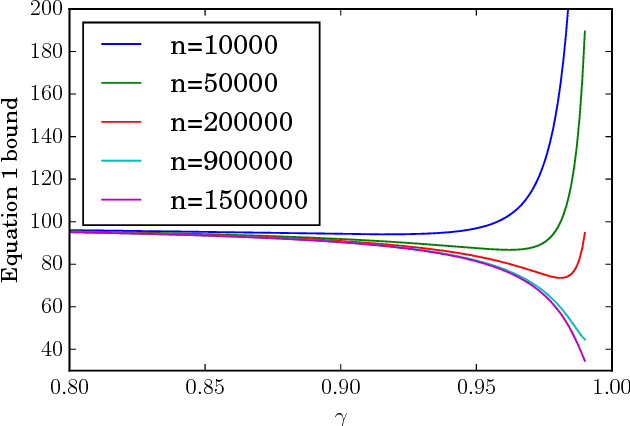
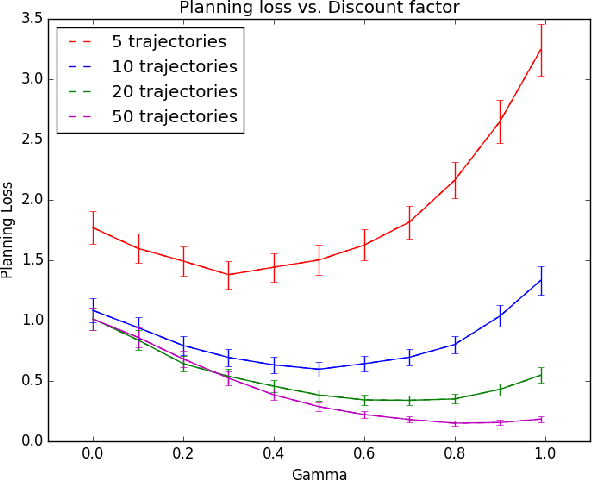
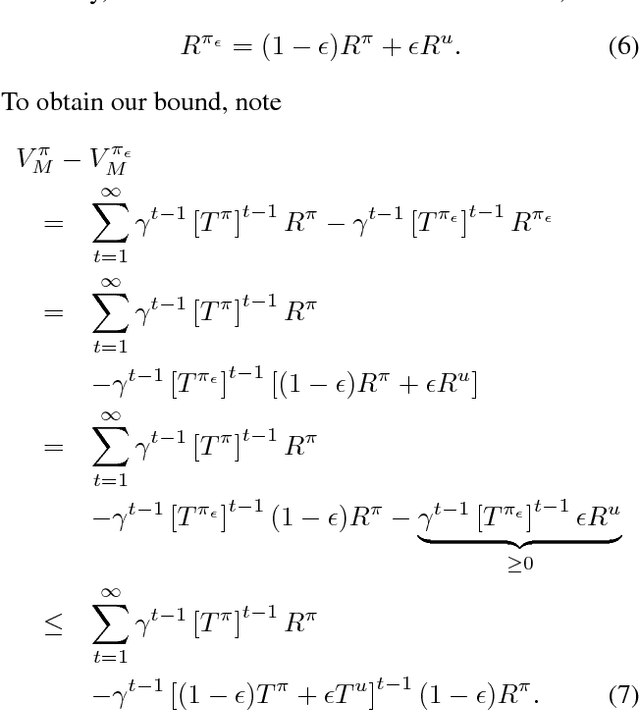
An agent with an inaccurate model of its environment faces a difficult choice: it can ignore the errors in its model and act in the real world in whatever way it determines is optimal with respect to its model. Alternatively, it can take a more conservative stance and eschew its model in favor of optimizing its behavior solely via real-world interaction. This latter approach can be exceedingly slow to learn from experience, while the former can lead to "planner overfitting" - aspects of the agent's behavior are optimized to exploit errors in its model. This paper explores an intermediate position in which the planner seeks to avoid overfitting through a kind of regularization of the plans it considers. We present three different approaches that demonstrably mitigate planner overfitting in reinforcement-learning environments.
Deep Abstract Q-Networks
Aug 25, 2018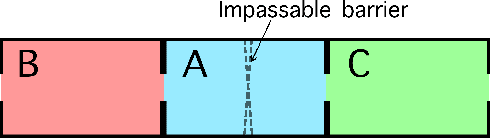
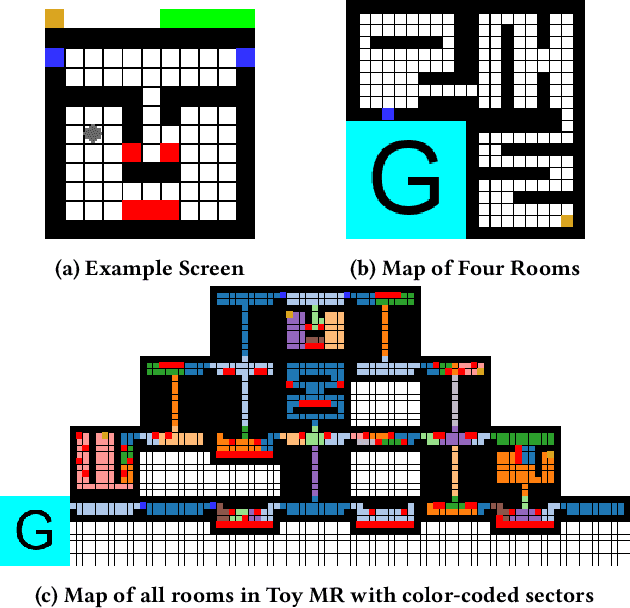
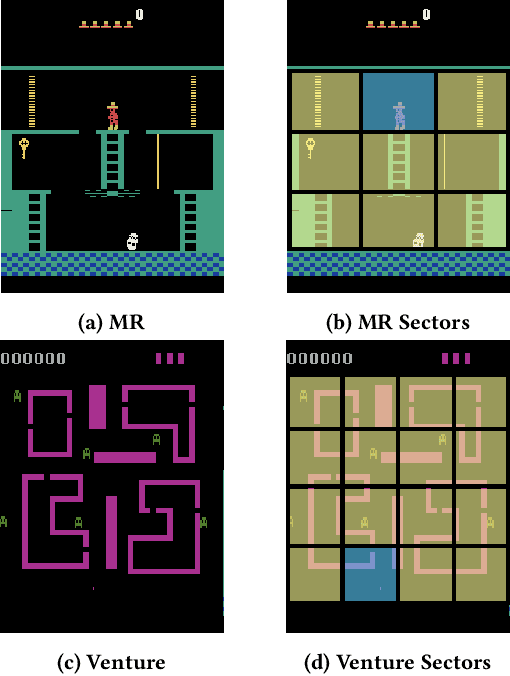
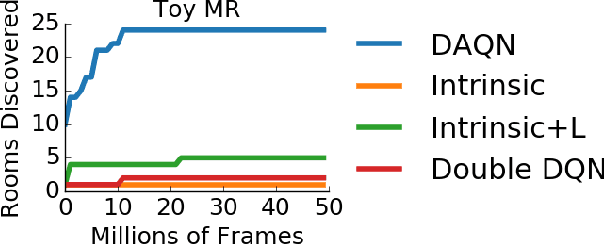
We examine the problem of learning and planning on high-dimensional domains with long horizons and sparse rewards. Recent approaches have shown great successes in many Atari 2600 domains. However, domains with long horizons and sparse rewards, such as Montezuma's Revenge and Venture, remain challenging for existing methods. Methods using abstraction (Dietterich 2000; Sutton, Precup, and Singh 1999) have shown to be useful in tackling long-horizon problems. We combine recent techniques of deep reinforcement learning with existing model-based approaches using an expert-provided state abstraction. We construct toy domains that elucidate the problem of long horizons, sparse rewards and high-dimensional inputs, and show that our algorithm significantly outperforms previous methods on these domains. Our abstraction-based approach outperforms Deep Q-Networks (Mnih et al. 2015) on Montezuma's Revenge and Venture, and exhibits backtracking behavior that is absent from previous methods.
Modeling Latent Attention Within Neural Networks
Dec 30, 2017

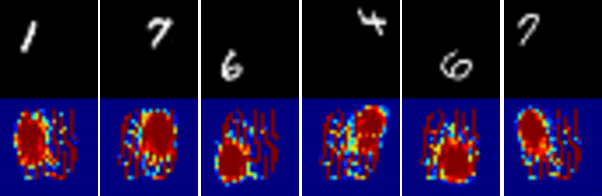

Deep neural networks are able to solve tasks across a variety of domains and modalities of data. Despite many empirical successes, we lack the ability to clearly understand and interpret the learned internal mechanisms that contribute to such effective behaviors or, more critically, failure modes. In this work, we present a general method for visualizing an arbitrary neural network's inner mechanisms and their power and limitations. Our dataset-centric method produces visualizations of how a trained network attends to components of its inputs. The computed "attention masks" support improved interpretability by highlighting which input attributes are critical in determining output. We demonstrate the effectiveness of our framework on a variety of deep neural network architectures in domains from computer vision, natural language processing, and reinforcement learning. The primary contribution of our approach is an interpretable visualization of attention that provides unique insights into the network's underlying decision-making process irrespective of the data modality.