Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Independently-Obtainable Reward Functions
Paper and Code
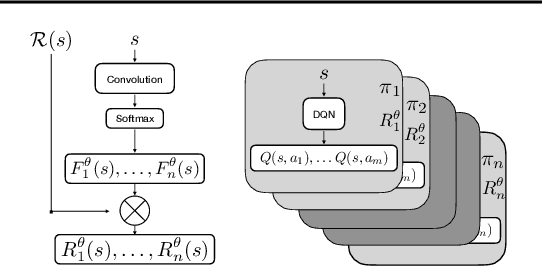
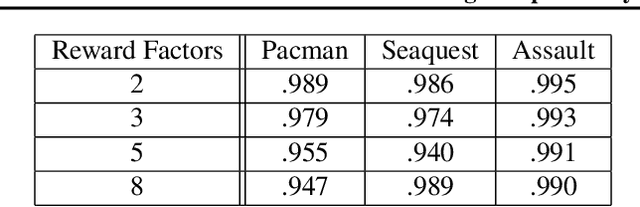
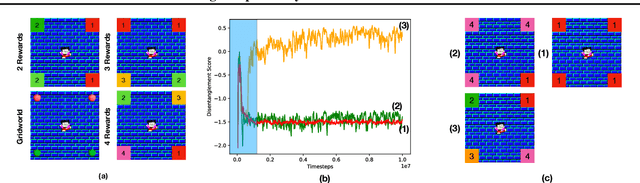
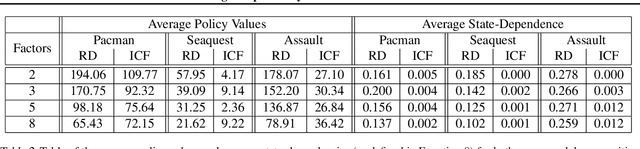
We present a novel method for learning a set of disentangled reward functions that sum to the original environment reward and are constrained to be independently obtainable. We define independent obtainability in terms of value functions with respect to obtaining one learned reward while pursuing another learned reward. Empirically, we illustrate that our method can learn meaningful reward decompositions in a variety of domains and that these decompositions exhibit some form of generalization performance when the environment's reward is modified. Theoretically, we derive results about the effect of maximizing our method's objective on the resulting reward functions and their corresponding optimal policies.
View paper on