 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePokeNet: Learning Kinematic Models of Articulated Objects from Human Observations
Feb 02, 2026Articulation modeling enables robots to learn joint parameters of articulated objects for effective manipulation which can then be used downstream for skill learning or planning. Existing approaches often rely on prior knowledge about the objects, such as the number or type of joints. Some of these approaches also fail to recover occluded joints that are only revealed during interaction. Others require large numbers of multi-view images for every object, which is impractical in real-world settings. Furthermore, prior works neglect the order of manipulations, which is essential for many multi-DoF objects where one joint must be operated before another, such as a dishwasher. We introduce PokeNet, an end-to-end framework that estimates articulation models from a single human demonstration without prior object knowledge. Given a sequence of point cloud observations of a human manipulating an unknown object, PokeNet predicts joint parameters, infers manipulation order, and tracks joint states over time. PokeNet outperforms existing state-of-the-art methods, improving joint axis and state estimation accuracy by an average of over 27% across diverse objects, including novel and unseen categories. We demonstrate these gains in both simulation and real-world environments.
ESPADA: Execution Speedup via Semantics Aware Demonstration Data Downsampling for Imitation Learning
Dec 15, 2025Behavior-cloning based visuomotor policies enable precise manipulation but often inherit the slow, cautious tempo of human demonstrations, limiting practical deployment. However, prior studies on acceleration methods mainly rely on statistical or heuristic cues that ignore task semantics and can fail across diverse manipulation settings. We present ESPADA, a semantic and spatially aware framework that segments demonstrations using a VLM-LLM pipeline with 3D gripper-object relations, enabling aggressive downsampling only in non-critical segments while preserving precision-critical phases, without requiring extra data or architectural modifications, or any form of retraining. To scale from a single annotated episode to the full dataset, ESPADA propagates segment labels via Dynamic Time Warping (DTW) on dynamics-only features. Across both simulation and real-world experiments with ACT and DP baselines, ESPADA achieves approximately a 2x speed-up while maintaining success rates, narrowing the gap between human demonstrations and efficient robot control.
Learning Sequential Kinematic Models from Demonstrations for Multi-Jointed Articulated Objects
May 09, 2025As robots become more generalized and deployed in diverse environments, they must interact with complex objects, many with multiple independent joints or degrees of freedom (DoF) requiring precise control. A common strategy is object modeling, where compact state-space models are learned from real-world observations and paired with classical planning. However, existing methods often rely on prior knowledge or focus on single-DoF objects, limiting their applicability. They also fail to handle occluded joints and ignore the manipulation sequences needed to access them. We address this by learning object models from human demonstrations. We introduce Object Kinematic Sequence Machines (OKSMs), a novel representation capturing both kinematic constraints and manipulation order for multi-DoF objects. To estimate these models from point cloud data, we present Pokenet, a deep neural network trained on human demonstrations. We validate our approach on 8,000 simulated and 1,600 real-world annotated samples. Pokenet improves joint axis and state estimation by over 20 percent on real-world data compared to prior methods. Finally, we demonstrate OKSMs on a Sawyer robot using inverse kinematics-based planning to manipulate multi-DoF objects.
CLIP-RT: Learning Language-Conditioned Robotic Policies from Natural Language Supervision
Nov 01, 2024

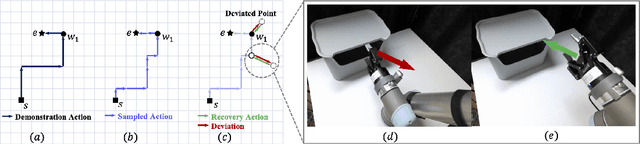
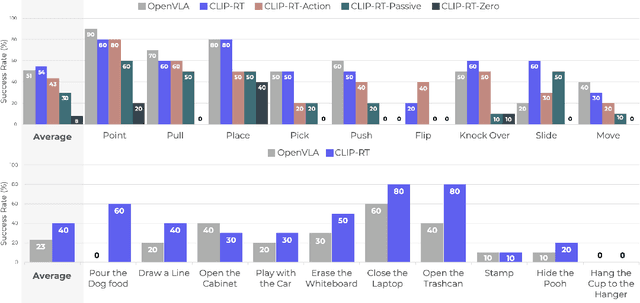
This paper explores how non-experts can teach robots desired skills in their environments. We argue that natural language is an intuitive and accessible interface for robot learning. To this end, we investigate two key aspects: (1) how non-experts collect robotic data using natural language supervision and (2) how pre-trained vision-language models learn end-to-end policies directly from this supervision. We propose a data collection framework that collects robot demonstrations based on natural language supervision (e.g., "move forward") and further augments these demonstrations. Next, we introduce a model that learns language-conditioned policies from natural language supervision called CLIP-RT. Our model employs pre-trained CLIP models and learns to predict actions represented in language via contrastive imitation learning. We first train CLIP-RT on large-scale robotic data and then enable it to learn desired skills using data collected from our framework. CLIP-RT shows strong capabilities in acquiring novel manipulation skills, outperforming the state-of-the-art model, OpenVLA (7B parameters), by 17% in average success rates, while using 7x fewer parameters (1B).
Multi-Object RANSAC: Efficient Plane Clustering Method in a Clutter
Mar 19, 2024



In this paper, we propose a novel method for plane clustering specialized in cluttered scenes using an RGB-D camera and validate its effectiveness through robot grasping experiments. Unlike existing methods, which focus on large-scale indoor structures, our approach -- Multi-Object RANSAC emphasizes cluttered environments that contain a wide range of objects with different scales. It enhances plane segmentation by generating subplanes in Deep Plane Clustering (DPC) module, which are then merged with the final planes by post-processing. DPC rearranges the point cloud by voting layers to make subplane clusters, trained in a self-supervised manner using pseudo-labels generated from RANSAC. Multi-Object RANSAC demonstrates superior plane instance segmentation performances over other recent RANSAC applications. We conducted an experiment on robot suction-based grasping, comparing our method with vision-based grasping network and RANSAC applications. The results from this real-world scenario showed its remarkable performance surpassing the baseline methods, highlighting its potential for advanced scene understanding and manipulation.
Stackelberg Punishment and Bully-Proofing Autonomous Vehicles
Aug 23, 2019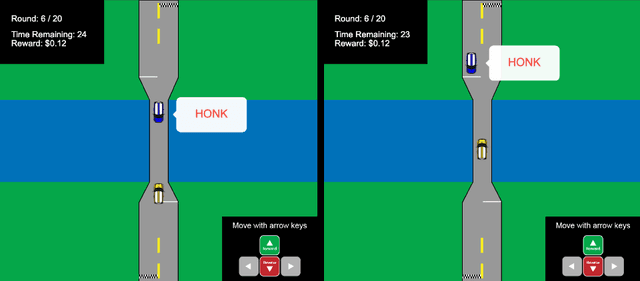
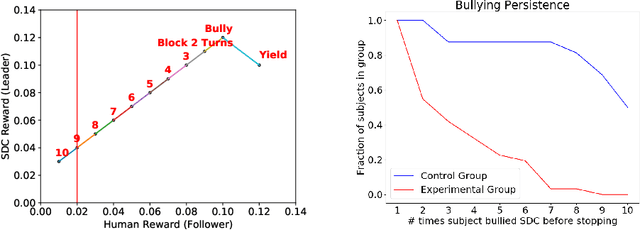
Mutually beneficial behavior in repeated games can be enforced via the threat of punishment, as enshrined in game theory's well-known "folk theorem." There is a cost, however, to a player for generating these disincentives. In this work, we seek to minimize this cost by computing a "Stackelberg punishment," in which the player selects a behavior that sufficiently punishes the other player while maximizing its own score under the assumption that the other player will adopt a best response. This idea generalizes the concept of a Stackelberg equilibrium. Known efficient algorithms for computing a Stackelberg equilibrium can be adapted to efficiently produce a Stackelberg punishment. We demonstrate an application of this idea in an experiment involving a virtual autonomous vehicle and human participants. We find that a self-driving car with a Stackelberg punishment policy discourages human drivers from bullying in a driving scenario requiring social negotiation.
Deep Reinforcement Learning from Policy-Dependent Human Feedback
Feb 12, 2019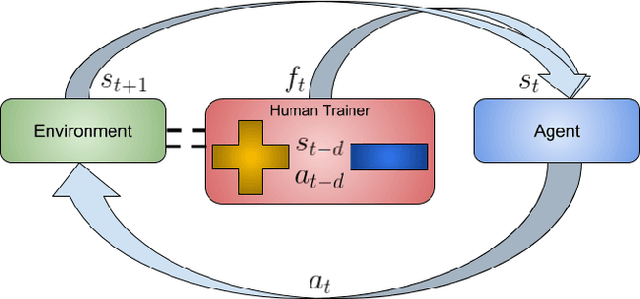
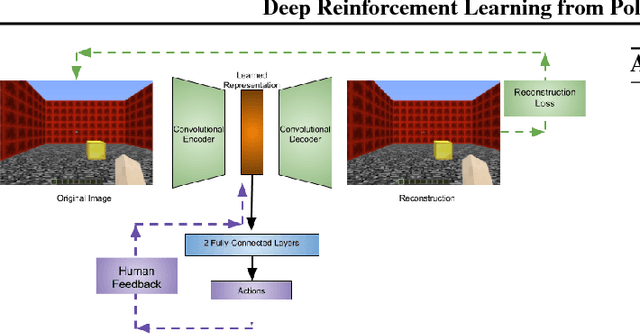

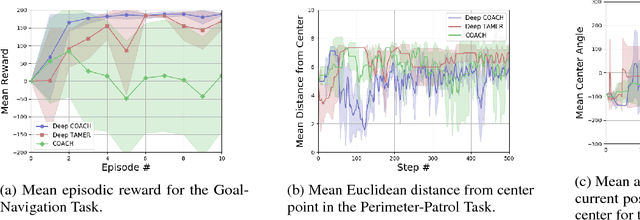
To widen their accessibility and increase their utility, intelligent agents must be able to learn complex behaviors as specified by (non-expert) human users. Moreover, they will need to learn these behaviors within a reasonable amount of time while efficiently leveraging the sparse feedback a human trainer is capable of providing. Recent work has shown that human feedback can be characterized as a critique of an agent's current behavior rather than as an alternative reward signal to be maximized, culminating in the COnvergent Actor-Critic by Humans (COACH) algorithm for making direct policy updates based on human feedback. Our work builds on COACH, moving to a setting where the agent's policy is represented by a deep neural network. We employ a series of modifications on top of the original COACH algorithm that are critical for successfully learning behaviors from high-dimensional observations, while also satisfying the constraint of obtaining reduced sample complexity. We demonstrate the effectiveness of our Deep COACH algorithm in the rich 3D world of Minecraft with an agent that learns to complete tasks by mapping from raw pixels to actions using only real-time human feedback in 10-15 minutes of interaction.
Measuring and Characterizing Generalization in Deep Reinforcement Learning
Dec 11, 2018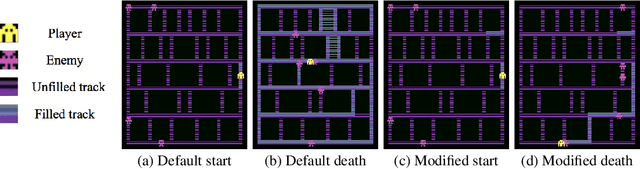
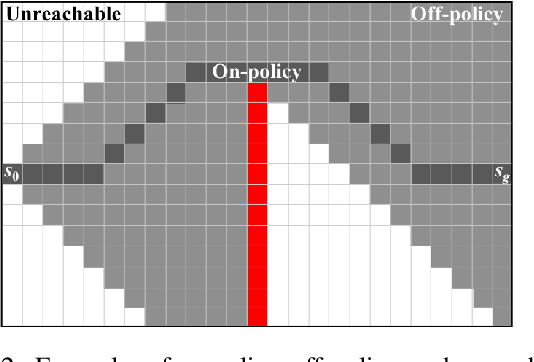
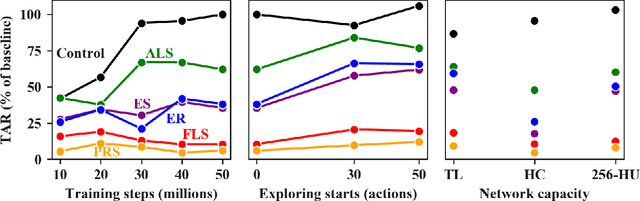
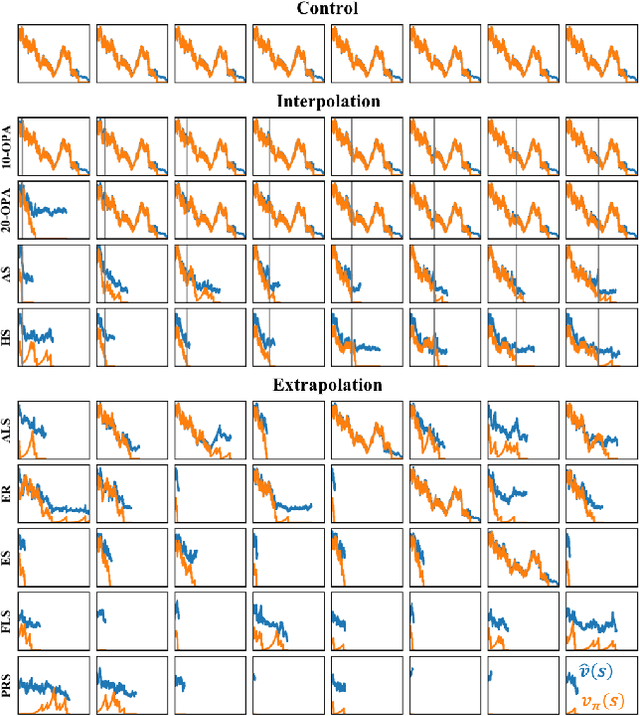
Deep reinforcement-learning methods have achieved remarkable performance on challenging control tasks. Observations of the resulting behavior give the impression that the agent has constructed a generalized representation that supports insightful action decisions. We re-examine what is meant by generalization in RL, and propose several definitions based on an agent's performance in on-policy, off-policy, and unreachable states. We propose a set of practical methods for evaluating agents with these definitions of generalization. We demonstrate these techniques on a common benchmark task for deep RL, and we show that the learned networks make poor decisions for states that differ only slightly from on-policy states, even though those states are not selected adversarially. Taken together, these results call into question the extent to which deep Q-networks learn generalized representations, and suggest that more experimentation and analysis is necessary before claims of representation learning can be supported.
Mitigating Planner Overfitting in Model-Based Reinforcement Learning
Dec 03, 2018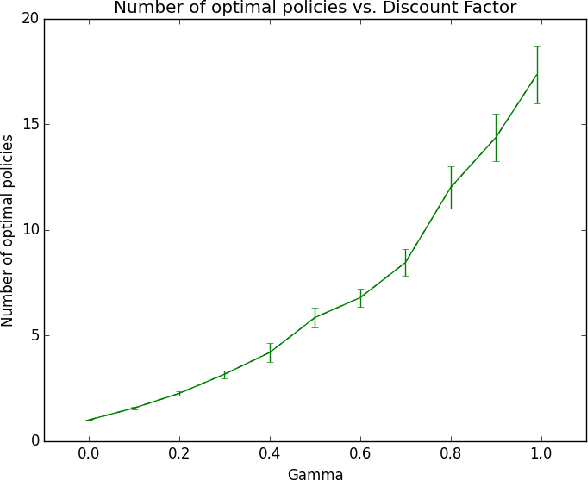
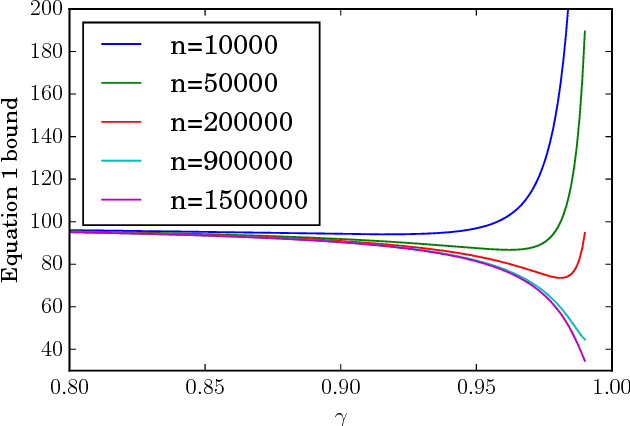
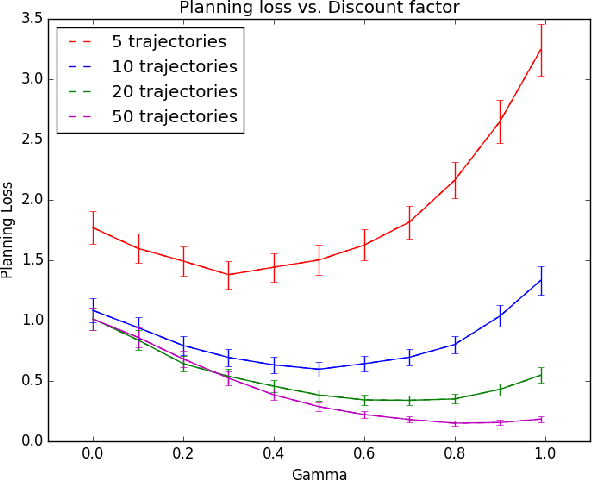
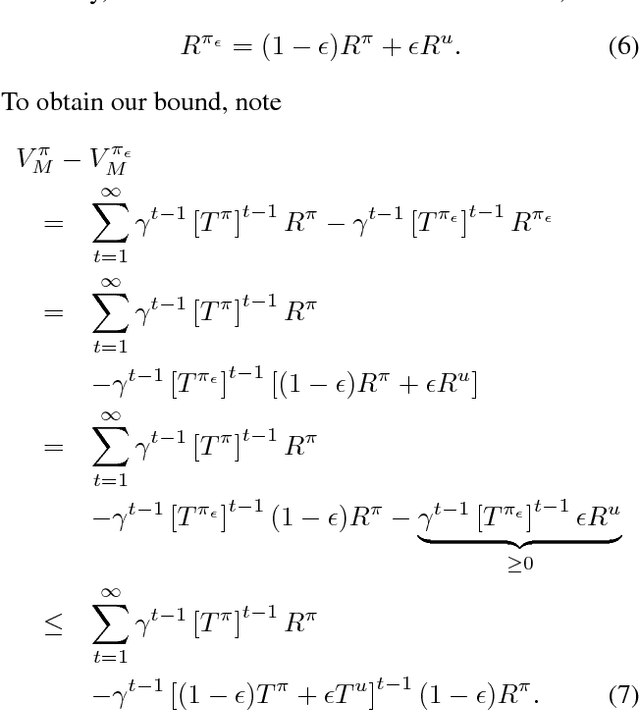
An agent with an inaccurate model of its environment faces a difficult choice: it can ignore the errors in its model and act in the real world in whatever way it determines is optimal with respect to its model. Alternatively, it can take a more conservative stance and eschew its model in favor of optimizing its behavior solely via real-world interaction. This latter approach can be exceedingly slow to learn from experience, while the former can lead to "planner overfitting" - aspects of the agent's behavior are optimized to exploit errors in its model. This paper explores an intermediate position in which the planner seeks to avoid overfitting through a kind of regularization of the plans it considers. We present three different approaches that demonstrably mitigate planner overfitting in reinforcement-learning environments.