 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Consequences of Privacy Policies with Narrative Generation via Answer Set Programming
Dec 13, 2022

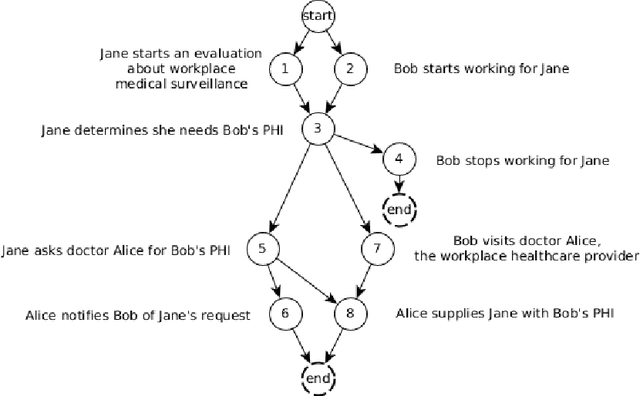
Informed consent has become increasingly salient for data privacy and its regulation. Entities from governments to for-profit companies have addressed concerns about data privacy with policies that enumerate the conditions for personal data storage and transfer. However, increased enumeration of and transparency in data privacy policies has not improved end-users' comprehension of how their data might be used: not only are privacy policies written in legal language that users may struggle to understand, but elements of these policies may compose in such a way that the consequences of the policy are not immediately apparent. We present a framework that uses Answer Set Programming (ASP) -- a type of logic programming -- to formalize privacy policies. Privacy policies thus become constraints on a narrative planning space, allowing end-users to forward-simulate possible consequences of the policy in terms of actors having roles and taking actions in a domain. We demonstrate through the example of the Health Insurance Portability and Accountability Act (HIPAA) how to use the system in various ways, including asking questions about possibilities and identifying which clauses of the law are broken by a given sequence of events.
Toybox: A Suite of Environments for Experimental Evaluation of Deep Reinforcement Learning
May 07, 2019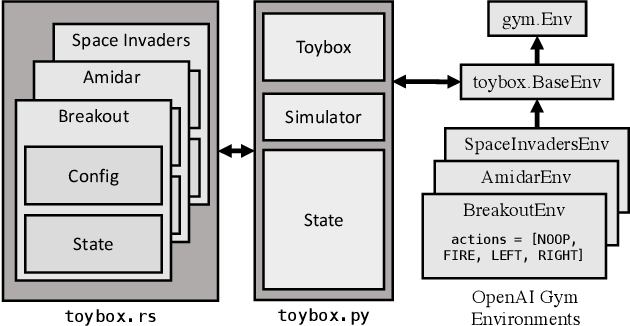
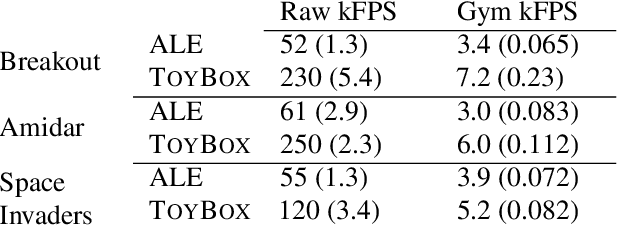
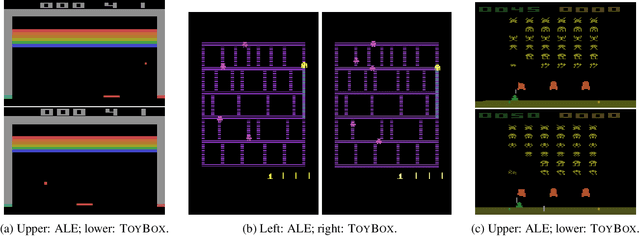
Evaluation of deep reinforcement learning (RL) is inherently challenging. In particular, learned policies are largely opaque, and hypotheses about the behavior of deep RL agents are difficult to test in black-box environments. Considerable effort has gone into addressing opacity, but almost no effort has been devoted to producing high quality environments for experimental evaluation of agent behavior. We present TOYBOX, a new high-performance, open-source* subset of Atari environments re-designed for the experimental evaluation of deep RL. We show that TOYBOX enables a wide range of experiments and analyses that are impossible in other environments. *https://kdl-umass.github.io/Toybox/
Let's Play Again: Variability of Deep Reinforcement Learning Agents in Atari Environments
Apr 12, 2019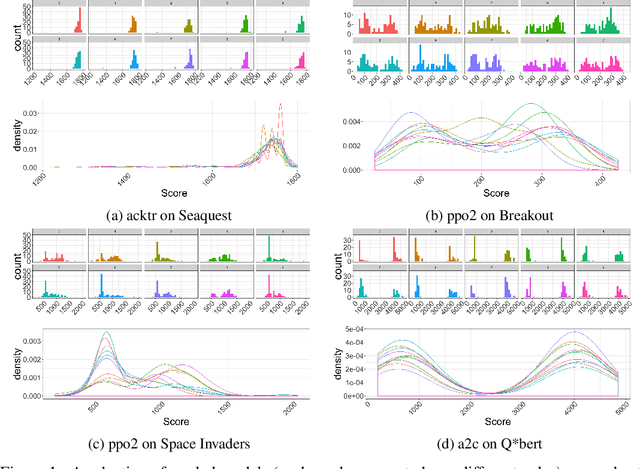
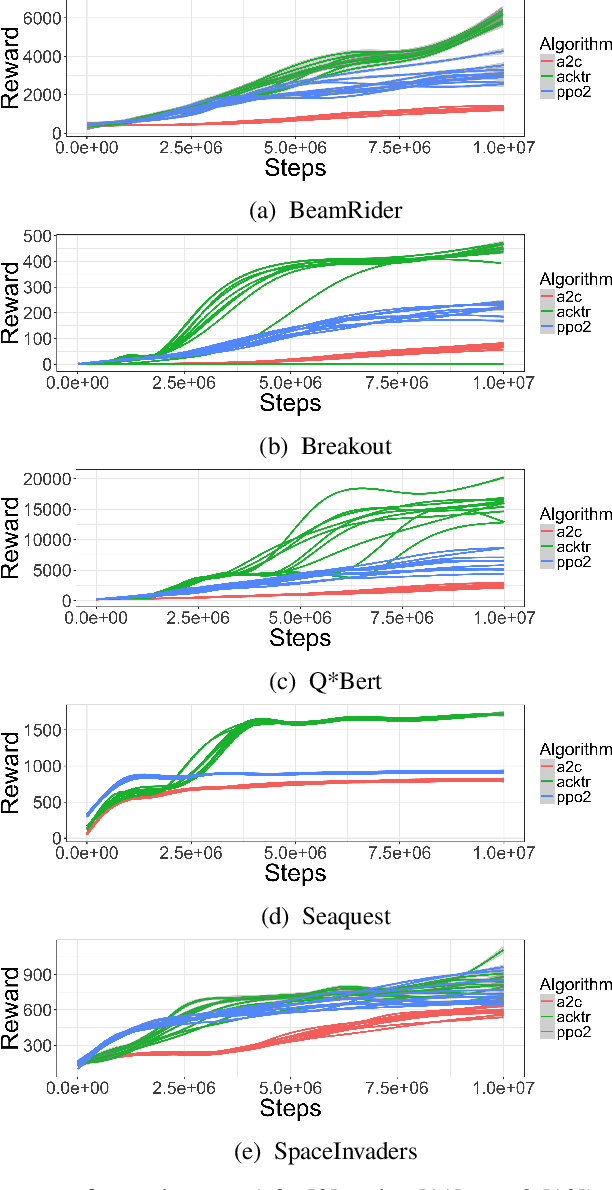
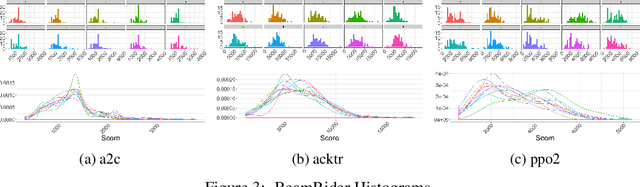
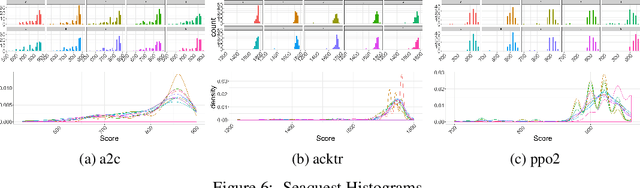
Reproducibility in reinforcement learning is challenging: uncontrolled stochasticity from many sources, such as the learning algorithm, the learned policy, and the environment itself have led researchers to report the performance of learned agents using aggregate metrics of performance over multiple random seeds for a single environment. Unfortunately, there are still pernicious sources of variability in reinforcement learning agents that make reporting common summary statistics an unsound metric for performance. Our experiments demonstrate the variability of common agents used in the popular OpenAI Baselines repository. We make the case for reporting post-training agent performance as a distribution, rather than a point estimate.
Measuring and Characterizing Generalization in Deep Reinforcement Learning
Dec 11, 2018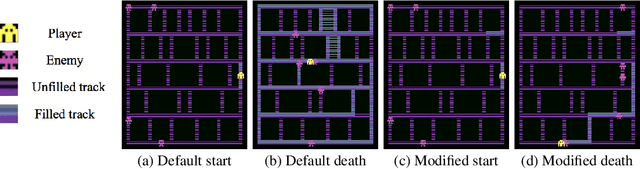
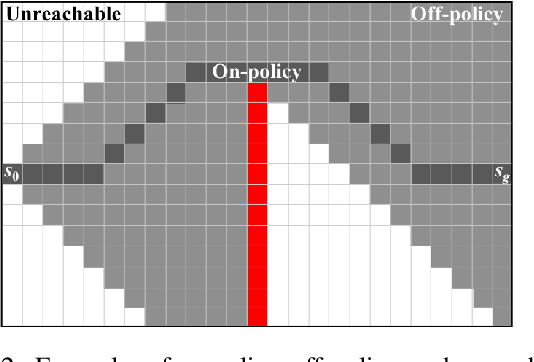
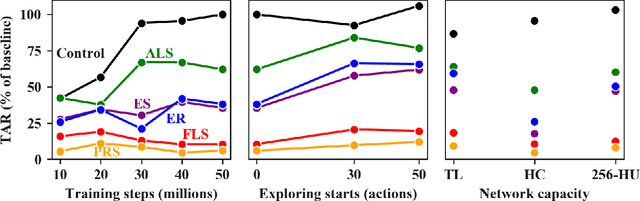
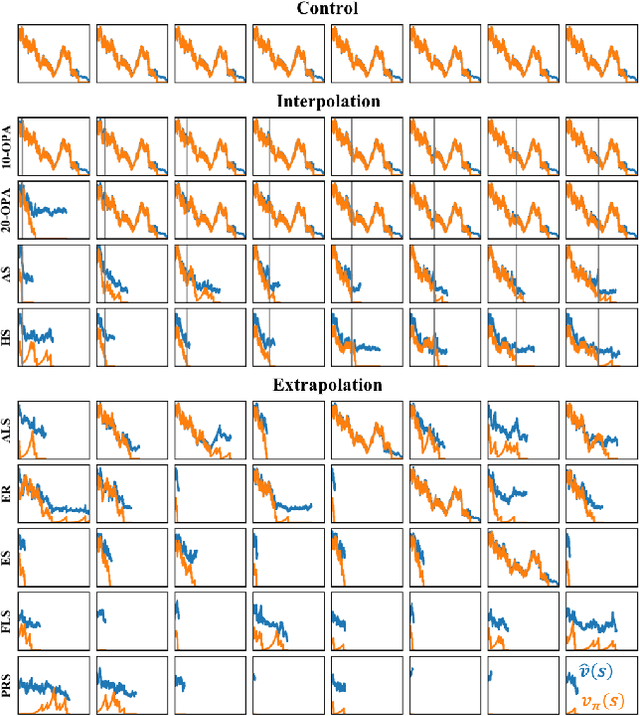
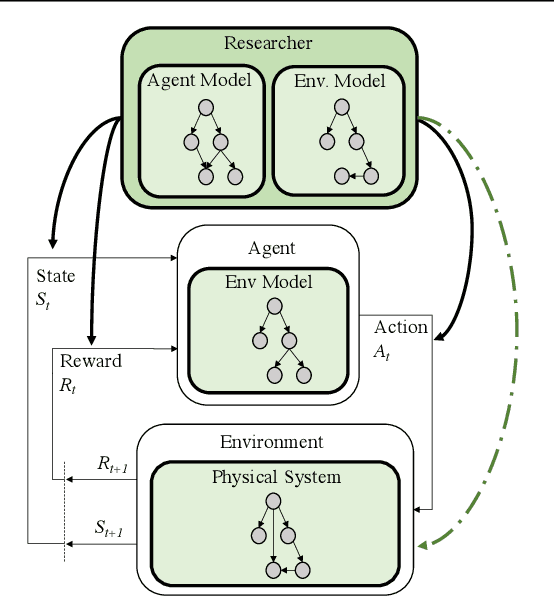
Deep reinforcement-learning methods have achieved remarkable performance on challenging control tasks. Observations of the resulting behavior give the impression that the agent has constructed a generalized representation that supports insightful action decisions. We re-examine what is meant by generalization in RL, and propose several definitions based on an agent's performance in on-policy, off-policy, and unreachable states. We propose a set of practical methods for evaluating agents with these definitions of generalization. We demonstrate these techniques on a common benchmark task for deep RL, and we show that the learned networks make poor decisions for states that differ only slightly from on-policy states, even though those states are not selected adversarially. Taken together, these results call into question the extent to which deep Q-networks learn generalized representations, and suggest that more experimentation and analysis is necessary before claims of representation learning can be supported.
ToyBox: Better Atari Environments for Testing Reinforcement Learning Agents
Dec 10, 2018
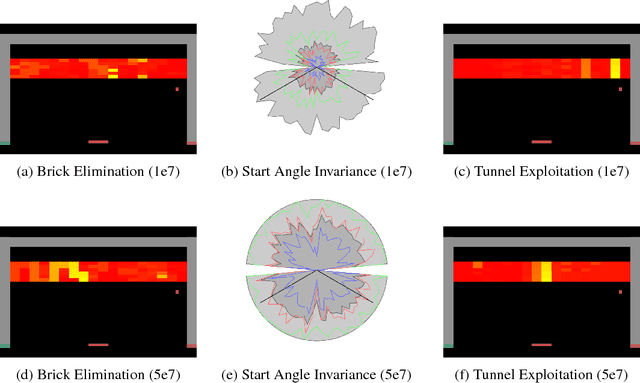
It is a widely accepted principle that software without tests has bugs. Testing reinforcement learning agents is especially difficult because of the stochastic nature of both agents and environments, the complexity of state-of-the-art models, and the sequential nature of their predictions. Recently, the Arcade Learning Environment (ALE) has become one of the most widely used benchmark suites for deep learning research, and state-of-the-art Reinforcement Learning (RL) agents have been shown to routinely equal or exceed human performance on many ALE tasks. Since ALE is based on emulation of original Atari games, the environment does not provide semantically meaningful representations of internal game state. This means that ALE has limited utility as an environment for supporting testing or model introspection. We propose ToyBox, a collection of reimplementations of these games that solves this critical problem and enables robust testing of RL agents.