 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI+HW 2035: Shaping the Next Decade
Mar 05, 2026Artificial intelligence (AI) and hardware (HW) are advancing at unprecedented rates, yet their trajectories have become inseparably intertwined. The global research community lacks a cohesive, long-term vision to strategically coordinate the development of AI and HW. This fragmentation constrains progress toward holistic, sustainable, and adaptive AI systems capable of learning, reasoning, and operating efficiently across cloud, edge, and physical environments. The future of AI depends not only on scaling intelligence, but on scaling efficiency, achieving exponential gains in intelligence per joule, rather than unbounded compute consumption. Addressing this grand challenge requires rethinking the entire computing stack. This vision paper lays out a 10-year roadmap for AI+HW co-design and co-development, spanning algorithms, architectures, systems, and sustainability. We articulate key insights that redefine scaling around energy efficiency, system-level integration, and cross-layer optimization. We identify key challenges and opportunities, candidly assess potential obstacles and pitfalls, and propose integrated solutions grounded in algorithmic innovation, hardware advances, and software abstraction. Looking ahead, we define what success means in 10 years: achieving a 1000x improvement in efficiency for AI training and inference; enabling energy-aware, self-optimizing systems that seamlessly span cloud, edge, and physical AI; democratizing access to advanced AI infrastructure; and embedding human-centric principles into the design of intelligent systems. Finally, we outline concrete action items for academia, industry, government, and the broader community, calling for coordinated national initiatives, shared infrastructure, workforce development, cross-agency collaboration, and sustained public-private partnerships to ensure that AI+HW co-design becomes a unifying long-term mission.
Knowledge Retention for Continual Model-Based Reinforcement Learning
Mar 06, 2025



We propose DRAGO, a novel approach for continual model-based reinforcement learning aimed at improving the incremental development of world models across a sequence of tasks that differ in their reward functions but not the state space or dynamics. DRAGO comprises two key components: Synthetic Experience Rehearsal, which leverages generative models to create synthetic experiences from past tasks, allowing the agent to reinforce previously learned dynamics without storing data, and Regaining Memories Through Exploration, which introduces an intrinsic reward mechanism to guide the agent toward revisiting relevant states from prior tasks. Together, these components enable the agent to maintain a comprehensive and continually developing world model, facilitating more effective learning and adaptation across diverse environments. Empirical evaluations demonstrate that DRAGO is able to preserve knowledge across tasks, achieving superior performance in various continual learning scenarios.
Computably Continuous Reinforcement-Learning Objectives are PAC-learnable
Mar 19, 2023In reinforcement learning, the classic objectives of maximizing discounted and finite-horizon cumulative rewards are PAC-learnable: There are algorithms that learn a near-optimal policy with high probability using a finite amount of samples and computation. In recent years, researchers have introduced objectives and corresponding reinforcement-learning algorithms beyond the classic cumulative rewards, such as objectives specified as linear temporal logic formulas. However, questions about the PAC-learnability of these new objectives have remained open. This work demonstrates the PAC-learnability of general reinforcement-learning objectives through sufficient conditions for PAC-learnability in two analysis settings. In particular, for the analysis that considers only sample complexity, we prove that if an objective given as an oracle is uniformly continuous, then it is PAC-learnable. Further, for the analysis that considers computational complexity, we prove that if an objective is computable, then it is PAC-learnable. In other words, if a procedure computes successive approximations of the objective's value, then the objective is PAC-learnable. We give three applications of our condition on objectives from the literature with previously unknown PAC-learnability and prove that these objectives are PAC-learnable. Overall, our result helps verify existing objectives' PAC-learnability. Also, as some studied objectives that are not uniformly continuous have been shown to be not PAC-learnable, our results could guide the design of new PAC-learnable objectives.
Meta-Learning Transferable Parameterized Skills
Jun 07, 2022



We propose a novel parameterized skill-learning algorithm that aims to learn transferable parameterized skills and synthesize them into a new action space that supports efficient learning in long-horizon tasks. We first propose novel learning objectives -- trajectory-centric diversity and smoothness -- that allow an agent to meta-learn reusable parameterized skills. Our agent can use these learned skills to construct a temporally-extended parameterized-action Markov decision process, for which we propose a hierarchical actor-critic algorithm that aims to efficiently learn a high-level control policy with the learned skills. We empirically demonstrate that the proposed algorithms enable an agent to solve a complicated long-horizon obstacle-course environment.
Does DQN really learn? Exploring adversarial training schemes in Pong
Mar 20, 2022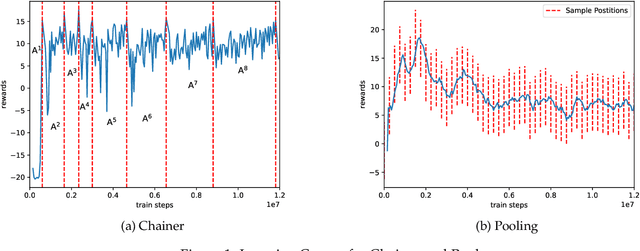
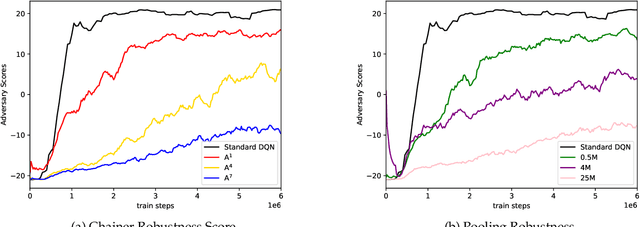

In this work, we study two self-play training schemes, Chainer and Pool, and show they lead to improved agent performance in Atari Pong compared to a standard DQN agent -- trained against the built-in Atari opponent. To measure agent performance, we define a robustness metric that captures how difficult it is to learn a strategy that beats the agent's learned policy. Through playing past versions of themselves, Chainer and Pool are able to target weaknesses in their policies and improve their resistance to attack. Agents trained using these methods score well on our robustness metric and can easily defeat the standard DQN agent. We conclude by using linear probing to illuminate what internal structures the different agents develop to play the game. We show that training agents with Chainer or Pool leads to richer network activations with greater predictive power to estimate critical game-state features compared to the standard DQN agent.
Learning Generalizable Behavior via Visual Rewrite Rules
Dec 09, 2021



Though deep reinforcement learning agents have achieved unprecedented success in recent years, their learned policies can be brittle, failing to generalize to even slight modifications of their environments or unfamiliar situations. The black-box nature of the neural network learning dynamics makes it impossible to audit trained deep agents and recover from such failures. In this paper, we propose a novel representation and learning approach to capture environment dynamics without using neural networks. It originates from the observation that, in games designed for people, the effect of an action can often be perceived in the form of local changes in consecutive visual observations. Our algorithm is designed to extract such vision-based changes and condense them into a set of action-dependent descriptive rules, which we call ''visual rewrite rules'' (VRRs). We also present preliminary results from a VRR agent that can explore, expand its rule set, and solve a game via planning with its learned VRR world model. In several classical games, our non-deep agent demonstrates superior performance, extreme sample efficiency, and robust generalization ability compared with several mainstream deep agents.
Reinforcement Learning for General LTL Objectives Is Intractable
Nov 24, 2021
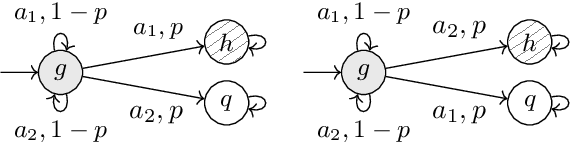


In recent years, researchers have made significant progress in devising reinforcement-learning algorithms for optimizing linear temporal logic (LTL) objectives and LTL-like objectives. Despite these advancements, there are fundamental limitations to how well this problem can be solved that previous studies have alluded to but, to our knowledge, have not examined in depth. In this paper, we address theoretically the hardness of learning with general LTL objectives. We formalize the problem under the probably approximately correct learning in Markov decision processes (PAC-MDP) framework, a standard framework for measuring sample complexity in reinforcement learning. In this formalization, we prove that the optimal policy for any LTL formula is PAC-MDP-learnable only if the formula is in the most limited class in the LTL hierarchy, consisting of only finite-horizon-decidable properties. Practically, our result implies that it is impossible for a reinforcement-learning algorithm to obtain a PAC-MDP guarantee on the performance of its learned policy after finitely many interactions with an unconstrained environment for non-finite-horizon-decidable LTL objectives.
Learning Finite Linear Temporal Logic Specifications with a Specialized Neural Operator
Nov 21, 2021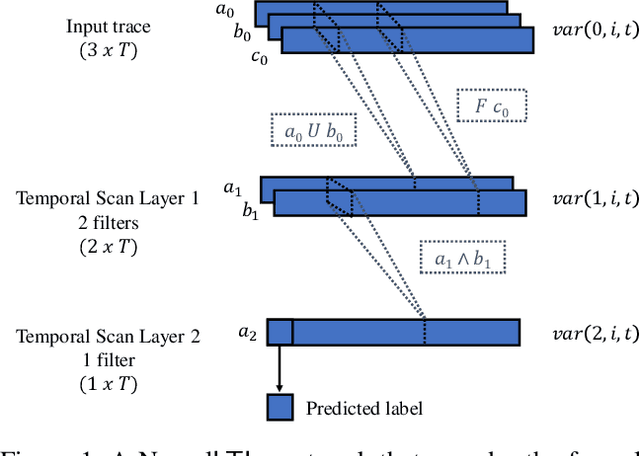
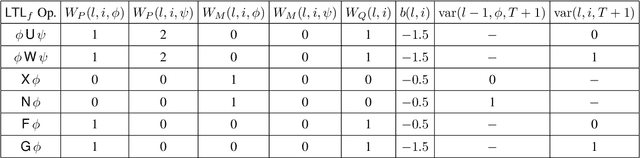

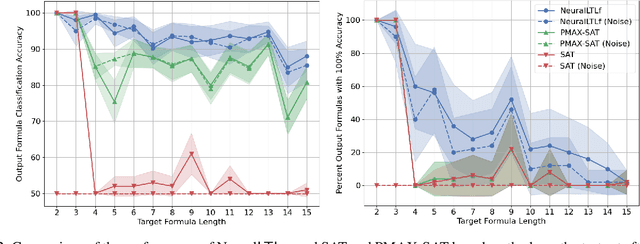
Finite linear temporal logic ($\mathsf{LTL}_f$) is a powerful formal representation for modeling temporal sequences. We address the problem of learning a compact $\mathsf{LTL}_f$ formula from labeled traces of system behavior. We propose a novel neural network operator and evaluate the resulting architecture, Neural$\mathsf{LTL}_f$. Our approach includes a specialized recurrent filter, designed to subsume $\mathsf{LTL}_f$ temporal operators, to learn a highly accurate classifier for traces. Then, it discretizes the activations and extracts the truth table represented by the learned weights. This truth table is converted to symbolic form and returned as the learned formula. Experiments on randomly generated $\mathsf{LTL}_f$ formulas show Neural$\mathsf{LTL}_f$ scales to larger formula sizes than existing approaches and maintains high accuracy even in the presence of noise.
Coarse-Grained Smoothness for RL in Metric Spaces
Oct 23, 2021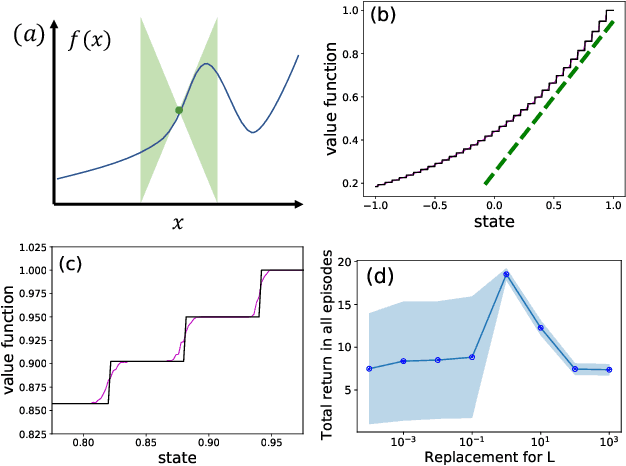
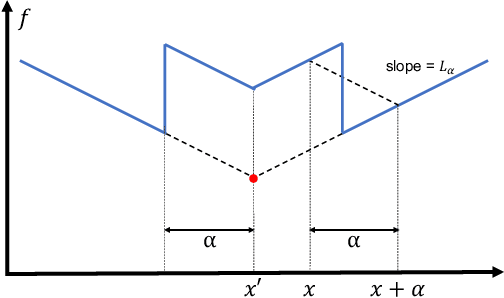
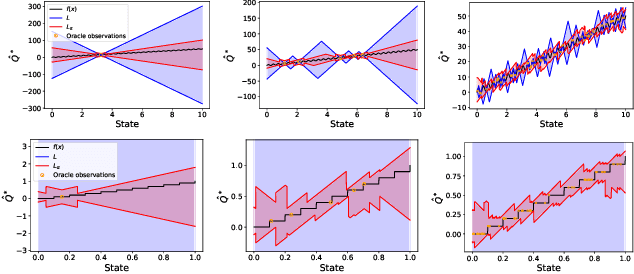
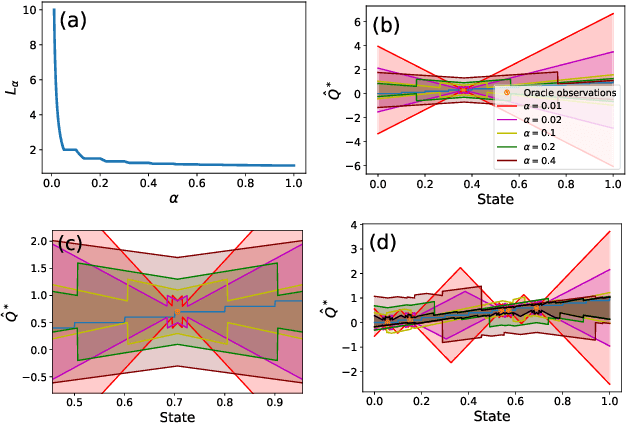
Principled decision-making in continuous state--action spaces is impossible without some assumptions. A common approach is to assume Lipschitz continuity of the Q-function. We show that, unfortunately, this property fails to hold in many typical domains. We propose a new coarse-grained smoothness definition that generalizes the notion of Lipschitz continuity, is more widely applicable, and allows us to compute significantly tighter bounds on Q-functions, leading to improved learning. We provide a theoretical analysis of our new smoothness definition, and discuss its implications and impact on control and exploration in continuous domains.
Model Selection's Disparate Impact in Real-World Deep Learning Applications
Apr 01, 2021
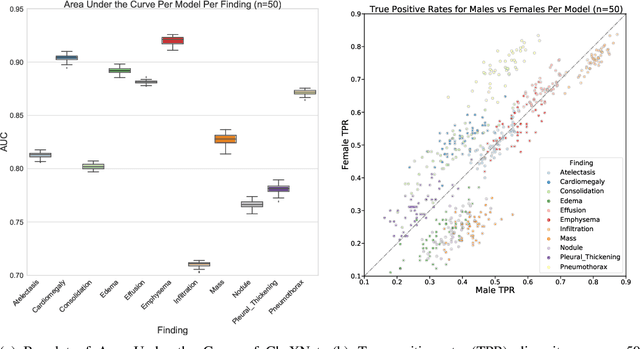
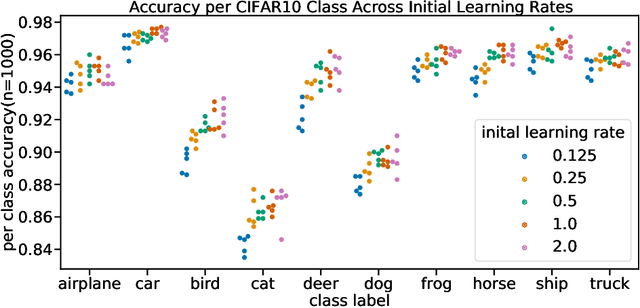
Algorithmic fairness has emphasized the role of biased data in automated decision outcomes. Recently, there has been a shift in attention to sources of bias that implicate fairness in other stages in the ML pipeline. We contend that one source of such bias, human preferences in model selection, remains under-explored in terms of its role in disparate impact across demographic groups. Using a deep learning model trained on real-world medical imaging data, we verify our claim empirically and argue that choice of metric for model comparison can significantly bias model selection outcomes.