 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputably Continuous Reinforcement-Learning Objectives are PAC-learnable
Mar 19, 2023In reinforcement learning, the classic objectives of maximizing discounted and finite-horizon cumulative rewards are PAC-learnable: There are algorithms that learn a near-optimal policy with high probability using a finite amount of samples and computation. In recent years, researchers have introduced objectives and corresponding reinforcement-learning algorithms beyond the classic cumulative rewards, such as objectives specified as linear temporal logic formulas. However, questions about the PAC-learnability of these new objectives have remained open. This work demonstrates the PAC-learnability of general reinforcement-learning objectives through sufficient conditions for PAC-learnability in two analysis settings. In particular, for the analysis that considers only sample complexity, we prove that if an objective given as an oracle is uniformly continuous, then it is PAC-learnable. Further, for the analysis that considers computational complexity, we prove that if an objective is computable, then it is PAC-learnable. In other words, if a procedure computes successive approximations of the objective's value, then the objective is PAC-learnable. We give three applications of our condition on objectives from the literature with previously unknown PAC-learnability and prove that these objectives are PAC-learnable. Overall, our result helps verify existing objectives' PAC-learnability. Also, as some studied objectives that are not uniformly continuous have been shown to be not PAC-learnable, our results could guide the design of new PAC-learnable objectives.
Reinforcement Learning for General LTL Objectives Is Intractable
Nov 24, 2021
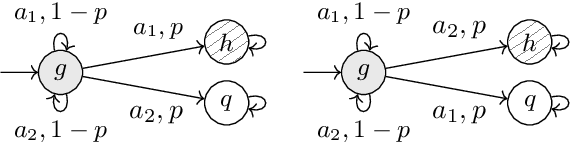


In recent years, researchers have made significant progress in devising reinforcement-learning algorithms for optimizing linear temporal logic (LTL) objectives and LTL-like objectives. Despite these advancements, there are fundamental limitations to how well this problem can be solved that previous studies have alluded to but, to our knowledge, have not examined in depth. In this paper, we address theoretically the hardness of learning with general LTL objectives. We formalize the problem under the probably approximately correct learning in Markov decision processes (PAC-MDP) framework, a standard framework for measuring sample complexity in reinforcement learning. In this formalization, we prove that the optimal policy for any LTL formula is PAC-MDP-learnable only if the formula is in the most limited class in the LTL hierarchy, consisting of only finite-horizon-decidable properties. Practically, our result implies that it is impossible for a reinforcement-learning algorithm to obtain a PAC-MDP guarantee on the performance of its learned policy after finitely many interactions with an unconstrained environment for non-finite-horizon-decidable LTL objectives.