 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Centered Development of Guide Dog Robots: Quiet and Stable Locomotion Control
May 17, 2025
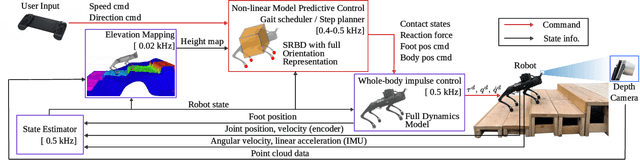
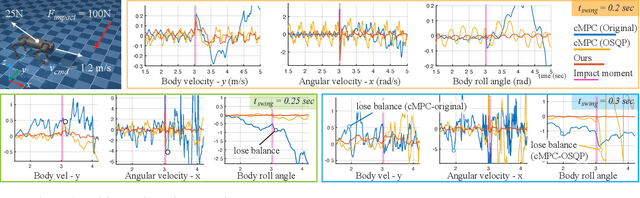
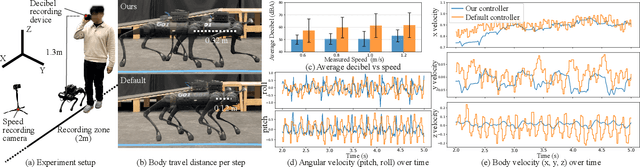
A quadruped robot is a promising system that can offer assistance comparable to that of dog guides due to its similar form factor. However, various challenges remain in making these robots a reliable option for blind and low-vision (BLV) individuals. Among these challenges, noise and jerky motion during walking are critical drawbacks of existing quadruped robots. While these issues have largely been overlooked in guide dog robot research, our interviews with guide dog handlers and trainers revealed that acoustic and physical disturbances can be particularly disruptive for BLV individuals, who rely heavily on environmental sounds for navigation. To address these issues, we developed a novel walking controller for slow stepping and smooth foot swing/contact while maintaining human walking speed, as well as robust and stable balance control. The controller integrates with a perception system to facilitate locomotion over non-flat terrains, such as stairs. Our controller was extensively tested on the Unitree Go1 robot and, when compared with other control methods, demonstrated significant noise reduction -- half of the default locomotion controller. In this study, we adopt a mixed-methods approach to evaluate its usability with BLV individuals. In our indoor walking experiments, participants compared our controller to the robot's default controller. Results demonstrated superior acceptance of our controller, highlighting its potential to improve the user experience of guide dog robots. Video demonstration (best viewed with audio) available at: https://youtu.be/8-pz_8Hqe6s.
A Biomechanics-Inspired Approach to Soccer Kicking for Humanoid Robots
Jul 19, 2024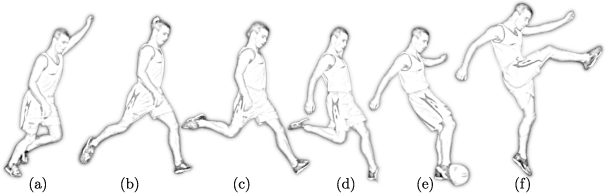
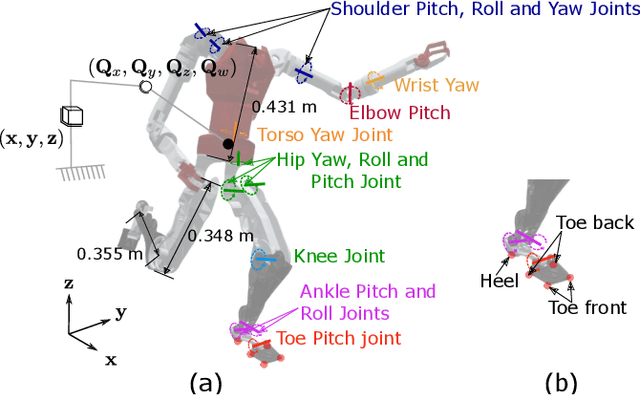
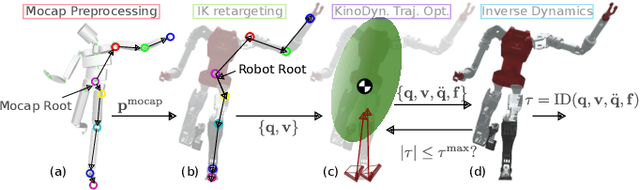
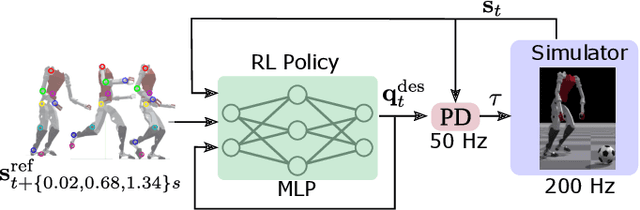
Soccer kicking is a complex whole-body motion that requires intricate coordination of various motor actions. To accomplish such dynamic motion in a humanoid robot, the robot needs to simultaneously: 1) transfer high kinetic energy to the kicking leg, 2) maintain balance and stability of the entire body, and 3) manage the impact disturbance from the ball during the kicking moment. Prior studies on robotic soccer kicking often prioritized stability, leading to overly conservative quasi-static motions. In this work, we present a biomechanics-inspired control framework that leverages trajectory optimization and imitation learning to facilitate highly dynamic soccer kicks in humanoid robots. We conducted an in-depth analysis of human soccer kick biomechanics to identify key motion constraints. Based on this understanding, we designed kinodynamically feasible trajectories that are then used as a reference in imitation learning to develop a robust feedback control policy. We demonstrate the effectiveness of our approach through a simulation of an anthropomorphic 25 DoF bipedal humanoid robot, named PresToe, which is equipped with 7 DoF legs, including a unique actuated toe. Using our framework, PresToe can execute dynamic instep kicks, propelling the ball at speeds exceeding 11m/s in full dynamics simulation.
Learning Generic and Dynamic Locomotion of Humanoids Across Discrete Terrains
May 27, 2024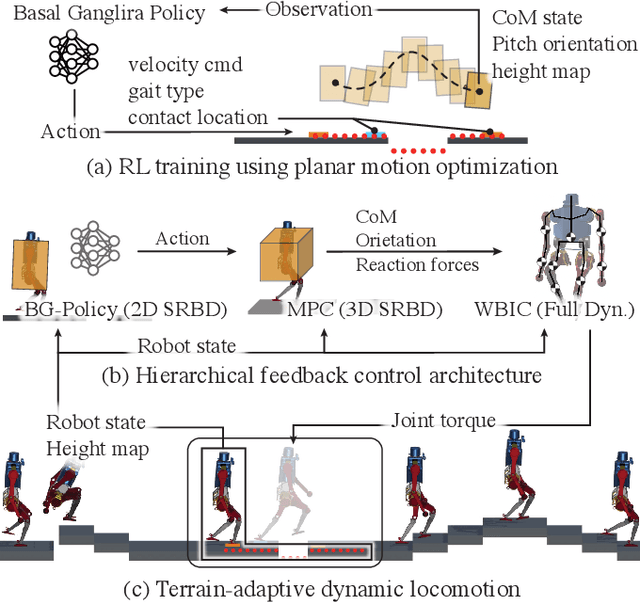



This paper addresses the challenge of terrain-adaptive dynamic locomotion in humanoid robots, a problem traditionally tackled by optimization-based methods or reinforcement learning (RL). Optimization-based methods, such as model-predictive control, excel in finding optimal reaction forces and achieving agile locomotion, especially in quadruped, but struggle with the nonlinear hybrid dynamics of legged systems and the real-time computation of step location, timing, and reaction forces. Conversely, RL-based methods show promise in navigating dynamic and rough terrains but are limited by their extensive data requirements. We introduce a novel locomotion architecture that integrates a neural network policy, trained through RL in simplified environments, with a state-of-the-art motion controller combining model-predictive control (MPC) and whole-body impulse control (WBIC). The policy efficiently learns high-level locomotion strategies, such as gait selection and step positioning, without the need for full dynamics simulations. This control architecture enables humanoid robots to dynamically navigate discrete terrains, making strategic locomotion decisions (e.g., walking, jumping, and leaping) based on ground height maps. Our results demonstrate that this integrated control architecture achieves dynamic locomotion with significantly fewer training samples than conventional RL-based methods and can be transferred to different humanoid platforms without additional training. The control architecture has been extensively tested in dynamic simulations, accomplishing terrain height-based dynamic locomotion for three different robots.
Impedance Matching: Enabling an RL-Based Running Jump in a Quadruped Robot
Apr 30, 2024



Replicating the remarkable athleticism seen in animals has long been a challenge in robotics control. Although Reinforcement Learning (RL) has demonstrated significant progress in dynamic legged locomotion control, the substantial sim-to-real gap often hinders the real-world demonstration of truly dynamic movements. We propose a new framework to mitigate this gap through frequency-domain analysis-based impedance matching between simulated and real robots. Our framework offers a structured guideline for parameter selection and the range for dynamics randomization in simulation, thus facilitating a safe sim-to-real transfer. The learned policy using our framework enabled jumps across distances of 55 cm and heights of 38 cm. The results are, to the best of our knowledge, one of the highest and longest running jumps demonstrated by an RL-based control policy in a real quadruped robot. Note that the achieved jumping height is approximately 85% of that obtained from a state-of-the-art trajectory optimization method, which can be seen as the physical limit for the given robot hardware. In addition, our control policy accomplished stable walking at speeds up to 2 m/s in the forward and backward directions, and 1 m/s in the sideway direction.
StaccaToe: A Single-Leg Robot that Mimics the Human Leg and Toe
Apr 07, 2024



We introduce StaccaToe, a human-scale, electric motor-powered single-leg robot designed to rival the agility of human locomotion through two distinctive attributes: an actuated toe and a co-actuation configuration inspired by the human leg. Leveraging the foundational design of HyperLeg's lower leg mechanism, we develop a stand-alone robot by incorporating new link designs, custom-designed power electronics, and a refined control system. Unlike previous jumping robots that rely on either special mechanisms (e.g., springs and clutches) or hydraulic/pneumatic actuators, StaccaToe employs electric motors without energy storage mechanisms. This choice underscores our ultimate goal of developing a practical, high-performance humanoid robot capable of human-like, stable walking as well as explosive dynamic movements. In this paper, we aim to empirically evaluate the balance capability and the exertion of explosive ground reaction forces of our toe and co-actuation mechanisms. Throughout extensive hardware and controller development, StaccaToe showcases its control fidelity by demonstrating a balanced tip-toe stance and dynamic jump. This study is significant for three key reasons: 1) StaccaToe represents the first human-scale, electric motor-driven single-leg robot to execute dynamic maneuvers without relying on specialized mechanisms; 2) our research provides empirical evidence of the benefits of replicating critical human leg attributes in robotic design; and 3) we explain the design process for creating agile legged robots, the details that have been scantily covered in academic literature.
A Domain-Agnostic Approach for Characterization of Lifelong Learning Systems
Jan 18, 2023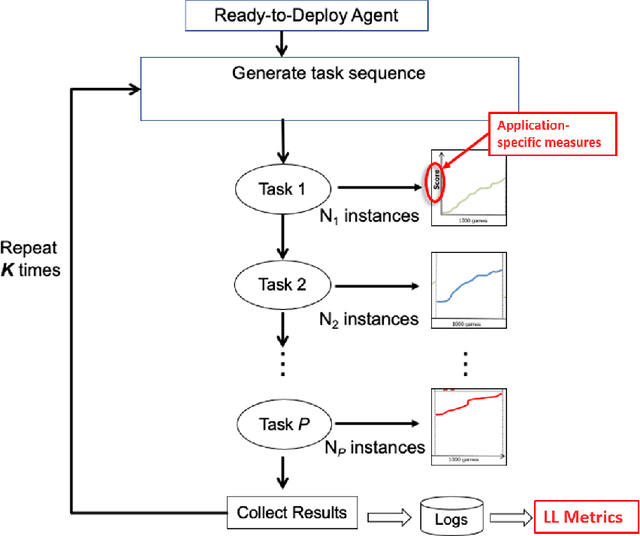


Despite the advancement of machine learning techniques in recent years, state-of-the-art systems lack robustness to "real world" events, where the input distributions and tasks encountered by the deployed systems will not be limited to the original training context, and systems will instead need to adapt to novel distributions and tasks while deployed. This critical gap may be addressed through the development of "Lifelong Learning" systems that are capable of 1) Continuous Learning, 2) Transfer and Adaptation, and 3) Scalability. Unfortunately, efforts to improve these capabilities are typically treated as distinct areas of research that are assessed independently, without regard to the impact of each separate capability on other aspects of the system. We instead propose a holistic approach, using a suite of metrics and an evaluation framework to assess Lifelong Learning in a principled way that is agnostic to specific domains or system techniques. Through five case studies, we show that this suite of metrics can inform the development of varied and complex Lifelong Learning systems. We highlight how the proposed suite of metrics quantifies performance trade-offs present during Lifelong Learning system development - both the widely discussed Stability-Plasticity dilemma and the newly proposed relationship between Sample Efficient and Robust Learning. Further, we make recommendations for the formulation and use of metrics to guide the continuing development of Lifelong Learning systems and assess their progress in the future.
Integration of Riemannian Motion Policy and Whole-Body Control for Dynamic Legged Locomotion
Oct 07, 2022
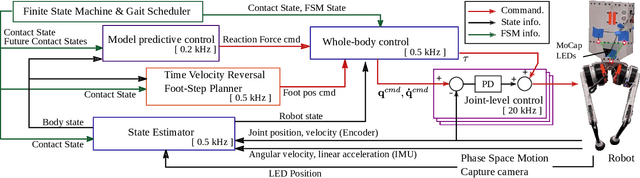


In this paper, we present a novel Riemannian Motion Policy (RMP)flow-based whole-body control framework for improved dynamic legged locomotion. RMPflow is a differential geometry-inspired algorithm for fusing multiple task-space policies (RMPs) into a configuration space policy in a geometrically consistent manner. RMP-based approaches are especially suited for designing simultaneous tracking and collision avoidance behaviors and have been successfully deployed on serial manipulators. However, one caveat of RMPflow is that it is designed with fully actuated systems in mind. In this work, we, for the first time, extend it to the domain of dynamic-legged systems, which have unforgiving under-actuation and limited control input. Thorough push recovery experiments are conducted in simulation to validate the overall framework. We show that expanding the valid stepping region with an RMP-based collision-avoidance swing leg controller improves balance robustness against external disturbances by up to $53\%$ compared to a baseline approach using a restricted stepping region. Furthermore, a point-foot biped robot is purpose-built for experimental studies of dynamic biped locomotion. A preliminary unassisted in-place stepping experiment is conducted to show the viability of the control framework and hardware.
Meta-Learning Transferable Parameterized Skills
Jun 07, 2022



We propose a novel parameterized skill-learning algorithm that aims to learn transferable parameterized skills and synthesize them into a new action space that supports efficient learning in long-horizon tasks. We first propose novel learning objectives -- trajectory-centric diversity and smoothness -- that allow an agent to meta-learn reusable parameterized skills. Our agent can use these learned skills to construct a temporally-extended parameterized-action Markov decision process, for which we propose a hierarchical actor-critic algorithm that aims to efficiently learn a high-level control policy with the learned skills. We empirically demonstrate that the proposed algorithms enable an agent to solve a complicated long-horizon obstacle-course environment.
Hierarchical Reinforcement Learning of Locomotion Policies in Response to Approaching Objects: A Preliminary Study
Mar 20, 2022


Animals such as rabbits and birds can instantly generate locomotion behavior in reaction to a dynamic, approaching object, such as a person or a rock, despite having possibly never seen the object before and having limited perception of the object's properties. Recently, deep reinforcement learning has enabled complex kinematic systems such as humanoid robots to successfully move from point A to point B. Inspired by the observation of the innate reactive behavior of animals in nature, we hope to extend this progress in robot locomotion to settings where external, dynamic objects are involved whose properties are partially observable to the robot. As a first step toward this goal, we build a simulation environment in MuJoCo where a legged robot must avoid getting hit by a ball moving toward it. We explore whether prior locomotion experiences that animals typically possess benefit the learning of a reactive control policy under a proposed hierarchical reinforcement learning framework. Preliminary results support the claim that the learning becomes more efficient using this hierarchical reinforcement learning method, even when partial observability (radius-based object visibility) is taken into account.
Learning Generalizable Behavior via Visual Rewrite Rules
Dec 09, 2021



Though deep reinforcement learning agents have achieved unprecedented success in recent years, their learned policies can be brittle, failing to generalize to even slight modifications of their environments or unfamiliar situations. The black-box nature of the neural network learning dynamics makes it impossible to audit trained deep agents and recover from such failures. In this paper, we propose a novel representation and learning approach to capture environment dynamics without using neural networks. It originates from the observation that, in games designed for people, the effect of an action can often be perceived in the form of local changes in consecutive visual observations. Our algorithm is designed to extract such vision-based changes and condense them into a set of action-dependent descriptive rules, which we call ''visual rewrite rules'' (VRRs). We also present preliminary results from a VRR agent that can explore, expand its rule set, and solve a game via planning with its learned VRR world model. In several classical games, our non-deep agent demonstrates superior performance, extreme sample efficiency, and robust generalization ability compared with several mainstream deep agents.