 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$A^2$: Smaller Self-Supervised ViTs Localize Better than Larger Ones
Jun 02, 2026Robust visual classification often depends on localizing the main foreground objects in an image while ignoring contextual distractors. Surprisingly, we find that the attention maps of smaller self-supervised ViTs localize foreground objects better than those of larger ViTs. However, we still need large ViTs, because they extract richer representations from each patch. To get the best of both worlds, good localization and rich representations, we propose $A^2$, a simple method that leverages this inverse scaling finding by decoupling where to look (a small attention model) from what to extract (a large embedding model): we crop around the attention peaks of a small model and embed the crops with a larger model. $A^2$ uses entirely pretrained features, requires no group labels, and does not require per-dataset attention or backbone training. Across 5 benchmarks, $A^2$ is competitive with backbone-matched loss-level methods like DFR, and outperforms end-to-end attention training under stronger distribution shifts.
Hierarchical Empowerment: Towards Tractable Empowerment-Based Skill-Learning
Jul 06, 2023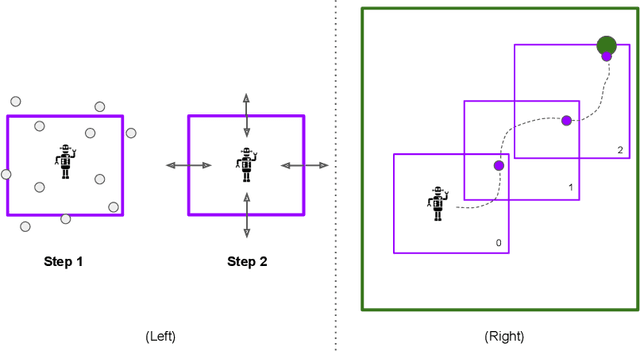

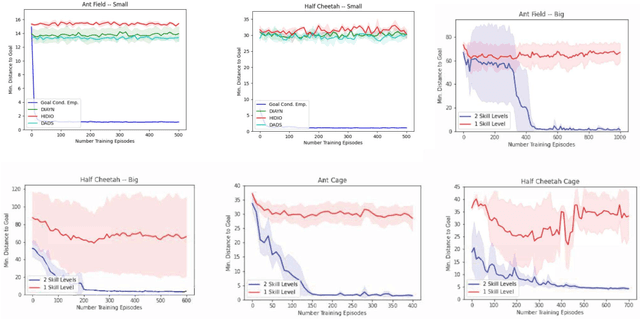

General purpose agents will require large repertoires of skills. Empowerment -- the maximum mutual information between skills and the states -- provides a pathway for learning large collections of distinct skills, but mutual information is difficult to optimize. We introduce a new framework, Hierarchical Empowerment, that makes computing empowerment more tractable by integrating concepts from Goal-Conditioned Hierarchical Reinforcement Learning. Our framework makes two specific contributions. First, we introduce a new variational lower bound on mutual information that can be used to compute empowerment over short horizons. Second, we introduce a hierarchical architecture for computing empowerment over exponentially longer time scales. We verify the contributions of the framework in a series of simulated robotics tasks. In a popular ant navigation domain, our four level agents are able to learn skills that cover a surface area over two orders of magnitude larger than prior work.
Learning robot motor skills with mixed reality
Mar 21, 2022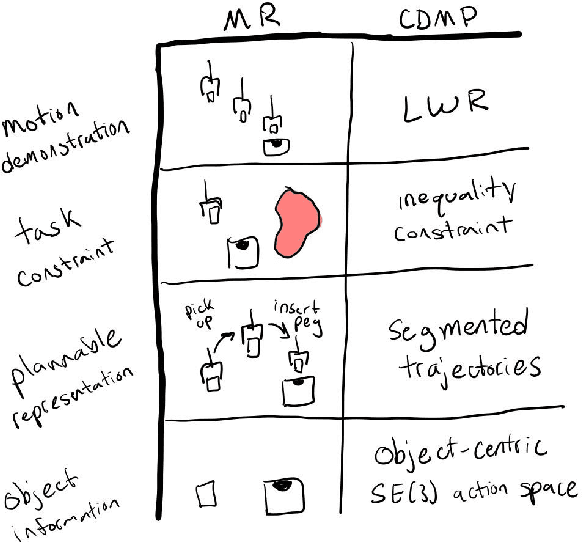

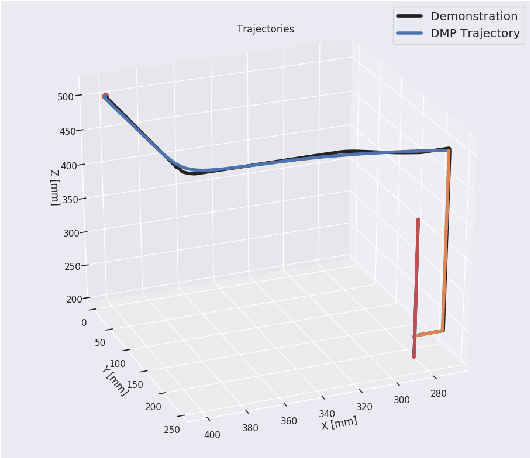
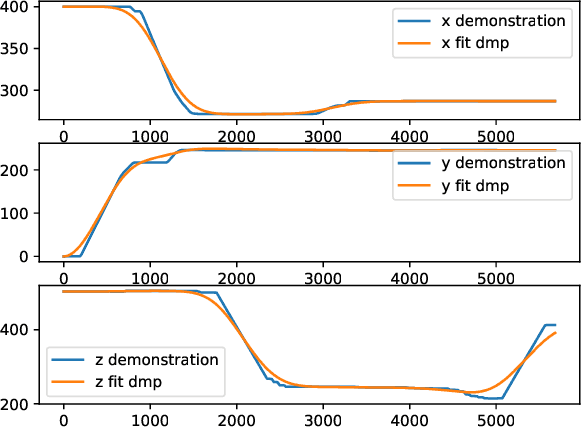
Mixed Reality (MR) has recently shown great success as an intuitive interface for enabling end-users to teach robots. Related works have used MR interfaces to communicate robot intents and beliefs to a co-located human, as well as developed algorithms for taking multi-modal human input and learning complex motor behaviors. Even with these successes, enabling end-users to teach robots complex motor tasks still poses a challenge because end-user communication is highly task dependent and world knowledge is highly varied. We propose a learning framework where end-users teach robots a) motion demonstrations, b) task constraints, c) planning representations, and d) object information, all of which are integrated into a single motor skill learning framework based on Dynamic Movement Primitives (DMPs). We hypothesize that conveying this world knowledge will be intuitive with an MR interface, and that a sample-efficient motor skill learning framework which incorporates varied modalities of world knowledge will enable robots to effectively solve complex tasks.
Hierarchical Reinforcement Learning of Locomotion Policies in Response to Approaching Objects: A Preliminary Study
Mar 20, 2022


Animals such as rabbits and birds can instantly generate locomotion behavior in reaction to a dynamic, approaching object, such as a person or a rock, despite having possibly never seen the object before and having limited perception of the object's properties. Recently, deep reinforcement learning has enabled complex kinematic systems such as humanoid robots to successfully move from point A to point B. Inspired by the observation of the innate reactive behavior of animals in nature, we hope to extend this progress in robot locomotion to settings where external, dynamic objects are involved whose properties are partially observable to the robot. As a first step toward this goal, we build a simulation environment in MuJoCo where a legged robot must avoid getting hit by a ball moving toward it. We explore whether prior locomotion experiences that animals typically possess benefit the learning of a reactive control policy under a proposed hierarchical reinforcement learning framework. Preliminary results support the claim that the learning becomes more efficient using this hierarchical reinforcement learning method, even when partial observability (radius-based object visibility) is taken into account.
Does DQN really learn? Exploring adversarial training schemes in Pong
Mar 20, 2022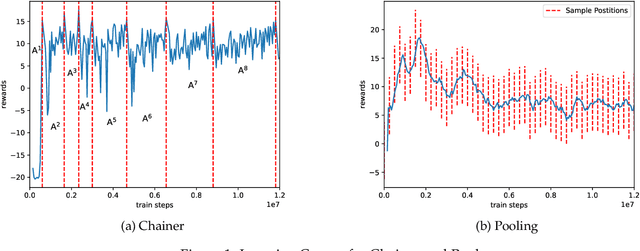
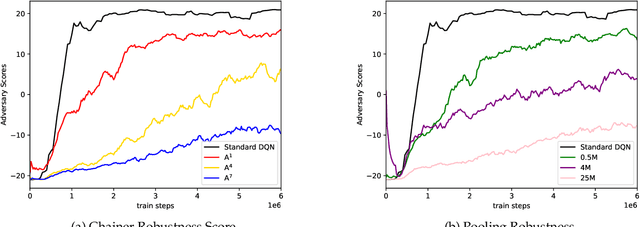

In this work, we study two self-play training schemes, Chainer and Pool, and show they lead to improved agent performance in Atari Pong compared to a standard DQN agent -- trained against the built-in Atari opponent. To measure agent performance, we define a robustness metric that captures how difficult it is to learn a strategy that beats the agent's learned policy. Through playing past versions of themselves, Chainer and Pool are able to target weaknesses in their policies and improve their resistance to attack. Agents trained using these methods score well on our robustness metric and can easily defeat the standard DQN agent. We conclude by using linear probing to illuminate what internal structures the different agents develop to play the game. We show that training agents with Chainer or Pool leads to richer network activations with greater predictive power to estimate critical game-state features compared to the standard DQN agent.
Value-Based Reinforcement Learning for Continuous Control Robotic Manipulation in Multi-Task Sparse Reward Settings
Jul 28, 2021
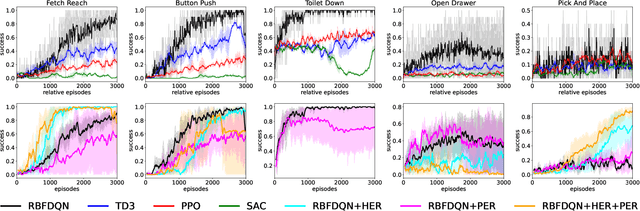
Learning continuous control in high-dimensional sparse reward settings, such as robotic manipulation, is a challenging problem due to the number of samples often required to obtain accurate optimal value and policy estimates. While many deep reinforcement learning methods have aimed at improving sample efficiency through replay or improved exploration techniques, state of the art actor-critic and policy gradient methods still suffer from the hard exploration problem in sparse reward settings. Motivated by recent successes of value-based methods for approximating state-action values, like RBF-DQN, we explore the potential of value-based reinforcement learning for learning continuous robotic manipulation tasks in multi-task sparse reward settings. On robotic manipulation tasks, we empirically show RBF-DQN converges faster than current state of the art algorithms such as TD3, SAC, and PPO. We also perform ablation studies with RBF-DQN and have shown that some enhancement techniques for vanilla Deep Q learning such as Hindsight Experience Replay (HER) and Prioritized Experience Replay (PER) can also be applied to RBF-DQN. Our experimental analysis suggests that value-based approaches may be more sensitive to data augmentation and replay buffer sample techniques than policy-gradient methods, and that the benefits of these methods for robot manipulation are heavily dependent on the transition dynamics of generated subgoal states.