 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 3D Restoration and Reconstruction in Real-world Adverse Conditions: RealX3D Challenge Results
Apr 05, 2026This paper presents a comprehensive review of the NTIRE 2026 3D Restoration and Reconstruction (3DRR) Challenge, detailing the proposed methods and results. The challenge seeks to identify robust reconstruction pipelines that are robust under real-world adverse conditions, specifically extreme low-light and smoke-degraded environments, as captured by our RealX3D benchmark. A total of 279 participants registered for the competition, of whom 33 teams submitted valid results. We thoroughly evaluate the submitted approaches against state-of-the-art baselines, revealing significant progress in 3D reconstruction under adverse conditions. Our analysis highlights shared design principles among top-performing methods and provides insights into effective strategies for handling 3D scene degradation.
Learning in Context, Guided by Choice: A Reward-Free Paradigm for Reinforcement Learning with Transformers
Feb 09, 2026In-context reinforcement learning (ICRL) leverages the in-context learning capabilities of transformer models (TMs) to efficiently generalize to unseen sequential decision-making tasks without parameter updates. However, existing ICRL methods rely on explicit reward signals during pretraining, which limits their applicability when rewards are ambiguous, hard to specify, or costly to obtain. To overcome this limitation, we propose a new learning paradigm, In-Context Preference-based Reinforcement Learning (ICPRL), in which both pretraining and deployment rely solely on preference feedback, eliminating the need for reward supervision. We study two variants that differ in the granularity of feedback: Immediate Preference-based RL (I-PRL) with per-step preferences, and Trajectory Preference-based RL (T-PRL) with trajectory-level comparisons. We first show that supervised pretraining, a standard approach in ICRL, remains effective under preference-only context datasets, demonstrating the feasibility of in-context reinforcement learning using only preference signals. To further improve data efficiency, we introduce alternative preference-native frameworks for I-PRL and T-PRL that directly optimize TM policies from preference data without requiring reward signals nor optimal action labels.Experiments on dueling bandits, navigation, and continuous control tasks demonstrate that ICPRL enables strong in-context generalization to unseen tasks, achieving performance comparable to ICRL methods trained with full reward supervision.
Neuro-Logic Lifelong Learning
Nov 16, 2025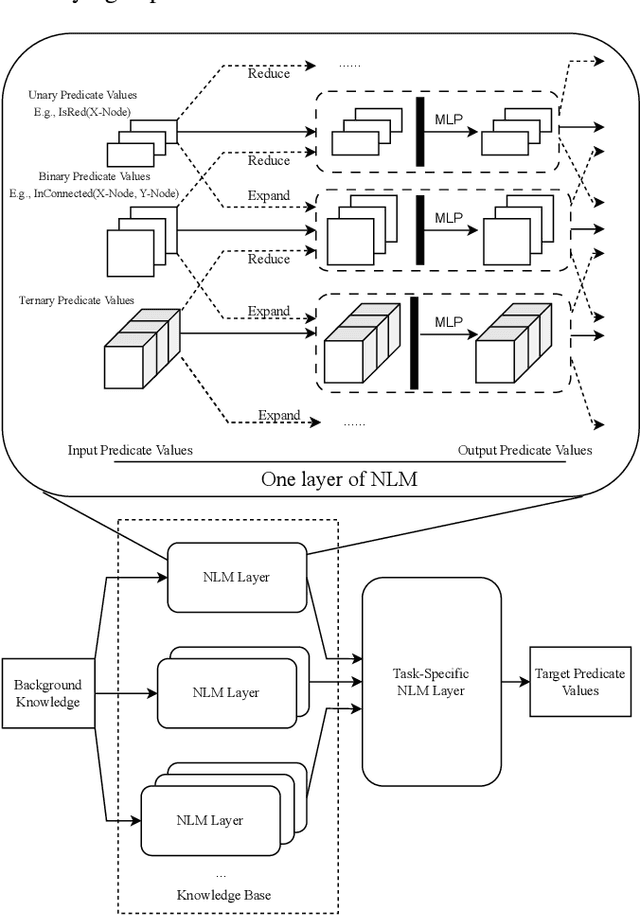
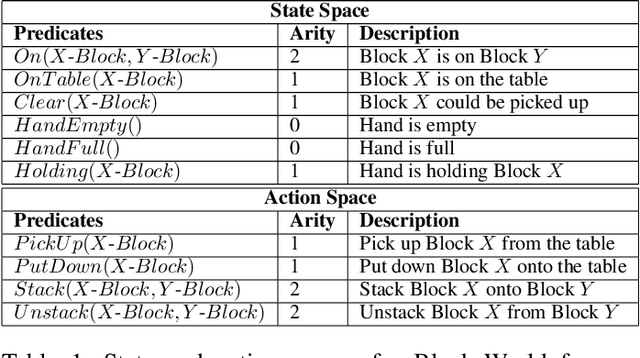
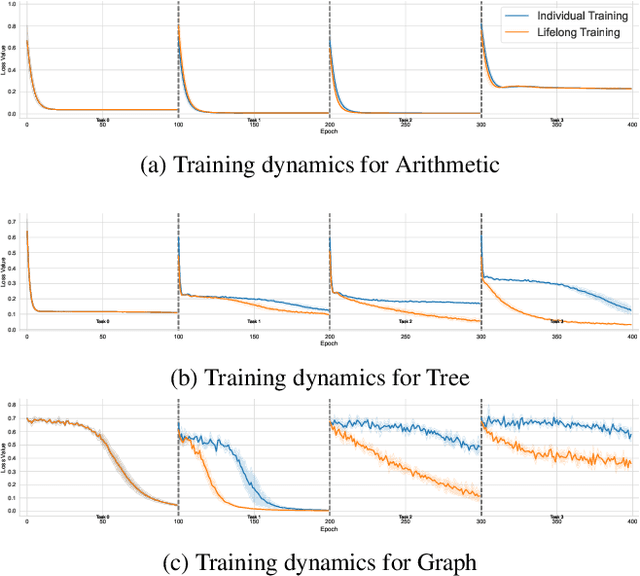
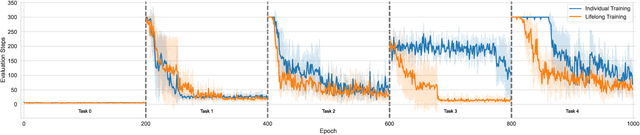
Solving Inductive Logic Programming (ILP) problems with neural networks is a key challenge in Neural-Symbolic Ar- tificial Intelligence (AI). While most research has focused on designing novel network architectures for individual prob- lems, less effort has been devoted to exploring new learning paradigms involving a sequence of problems. In this work, we investigate lifelong learning ILP, which leverages the com- positional and transferable nature of logic rules for efficient learning of new problems. We introduce a compositional framework, demonstrating how logic rules acquired from ear- lier tasks can be efficiently reused in subsequent ones, leading to improved scalability and performance. We formalize our approach and empirically evaluate it on sequences of tasks. Experimental results validate the feasibility and advantages of this paradigm, opening new directions for continual learn- ing in Neural-Symbolic AI.
Improving Audio-Visual Segmentation with Bidirectional Generation
Aug 16, 2023The aim of audio-visual segmentation (AVS) is to precisely differentiate audible objects within videos down to the pixel level. Traditional approaches often tackle this challenge by combining information from various modalities, where the contribution of each modality is implicitly or explicitly modeled. Nevertheless, the interconnections between different modalities tend to be overlooked in audio-visual modeling. In this paper, inspired by the human ability to mentally simulate the sound of an object and its visual appearance, we introduce a bidirectional generation framework. This framework establishes robust correlations between an object's visual characteristics and its associated sound, thereby enhancing the performance of AVS. To achieve this, we employ a visual-to-audio projection component that reconstructs audio features from object segmentation masks and minimizes reconstruction errors. Moreover, recognizing that many sounds are linked to object movements, we introduce an implicit volumetric motion estimation module to handle temporal dynamics that may be challenging to capture using conventional optical flow methods. To showcase the effectiveness of our approach, we conduct comprehensive experiments and analyses on the widely recognized AVSBench benchmark. As a result, we establish a new state-of-the-art performance level in the AVS benchmark, particularly excelling in the challenging MS3 subset which involves segmenting multiple sound sources. To facilitate reproducibility, we plan to release both the source code and the pre-trained model.
Toeplitz Neural Network for Sequence Modeling
May 08, 2023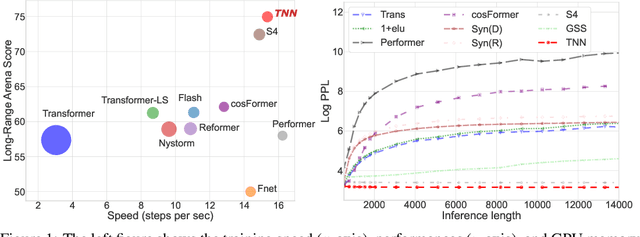

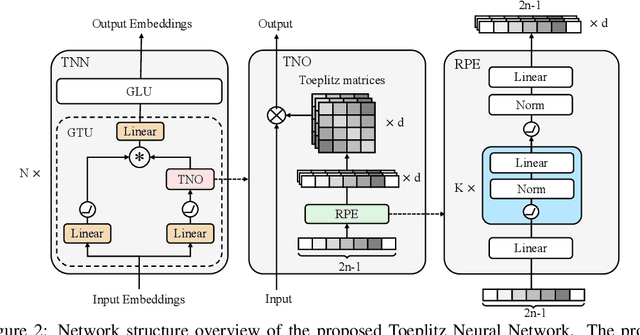
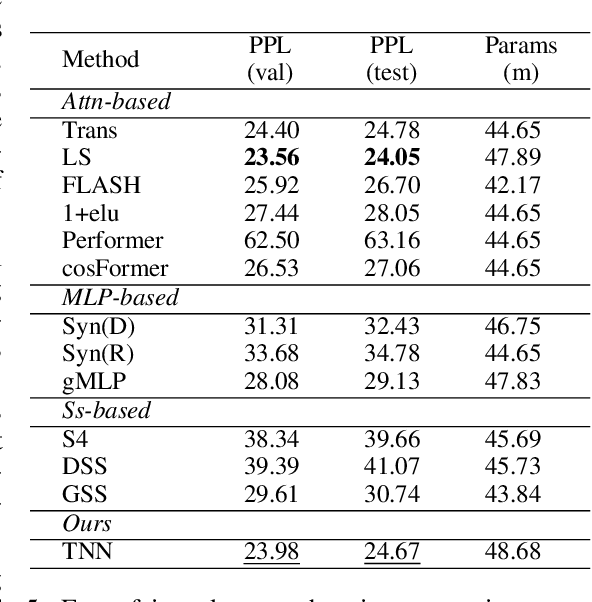
Sequence modeling has important applications in natural language processing and computer vision. Recently, the transformer-based models have shown strong performance on various sequence modeling tasks, which rely on attention to capture pairwise token relations, and position embedding to inject positional information. While showing good performance, the transformer models are inefficient to scale to long input sequences, mainly due to the quadratic space-time complexity of attention. To overcome this inefficiency, we propose to model sequences with a relative position encoded Toeplitz matrix and use a Toeplitz matrix-vector production trick to reduce the space-time complexity of the sequence modeling to log linear. A lightweight sub-network called relative position encoder is proposed to generate relative position coefficients with a fixed budget of parameters, enabling the proposed Toeplitz neural network to deal with varying sequence lengths. In addition, despite being trained on 512-token sequences, our model can extrapolate input sequence length up to 14K tokens in inference with consistent performance. Extensive experiments on autoregressive and bidirectional language modeling, image modeling, and the challenging Long-Range Arena benchmark show that our method achieves better performance than its competitors in most downstream tasks while being significantly faster. The code is available at https://github.com/OpenNLPLab/Tnn.
Fine-grained Audible Video Description
Mar 27, 2023
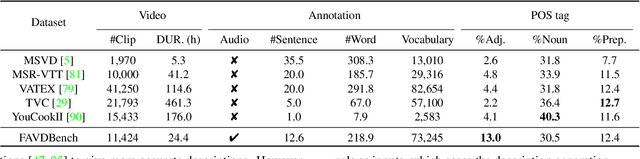
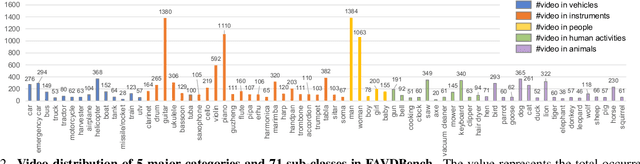
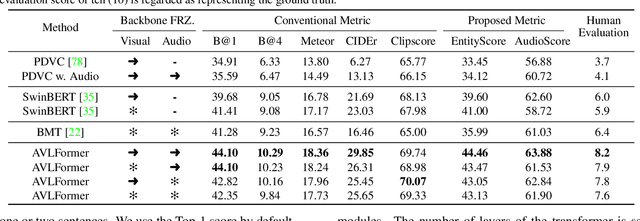
We explore a new task for audio-visual-language modeling called fine-grained audible video description (FAVD). It aims to provide detailed textual descriptions for the given audible videos, including the appearance and spatial locations of each object, the actions of moving objects, and the sounds in videos. Existing visual-language modeling tasks often concentrate on visual cues in videos while undervaluing the language and audio modalities. On the other hand, FAVD requires not only audio-visual-language modeling skills but also paragraph-level language generation abilities. We construct the first fine-grained audible video description benchmark (FAVDBench) to facilitate this research. For each video clip, we first provide a one-sentence summary of the video, ie, the caption, followed by 4-6 sentences describing the visual details and 1-2 audio-related descriptions at the end. The descriptions are provided in both English and Chinese. We create two new metrics for this task: an EntityScore to gauge the completeness of entities in the visual descriptions, and an AudioScore to assess the audio descriptions. As a preliminary approach to this task, we propose an audio-visual-language transformer that extends existing video captioning model with an additional audio branch. We combine the masked language modeling and auto-regressive language modeling losses to optimize our model so that it can produce paragraph-level descriptions. We illustrate the efficiency of our model in audio-visual-language modeling by evaluating it against the proposed benchmark using both conventional captioning metrics and our proposed metrics. We further put our benchmark to the test in video generation models, demonstrating that employing fine-grained video descriptions can create more intricate videos than using captions.
Does DQN really learn? Exploring adversarial training schemes in Pong
Mar 20, 2022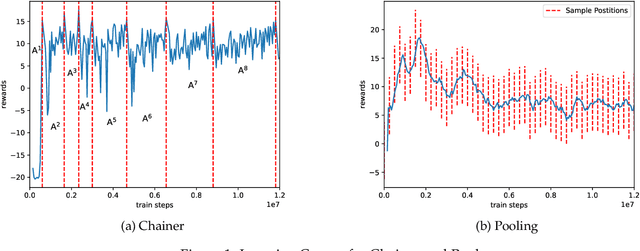
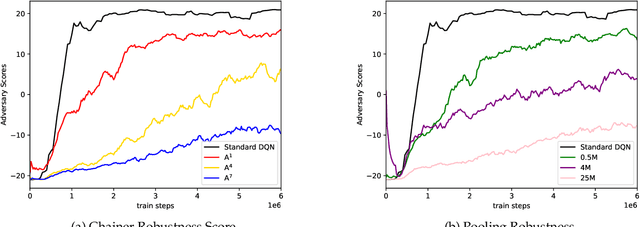

In this work, we study two self-play training schemes, Chainer and Pool, and show they lead to improved agent performance in Atari Pong compared to a standard DQN agent -- trained against the built-in Atari opponent. To measure agent performance, we define a robustness metric that captures how difficult it is to learn a strategy that beats the agent's learned policy. Through playing past versions of themselves, Chainer and Pool are able to target weaknesses in their policies and improve their resistance to attack. Agents trained using these methods score well on our robustness metric and can easily defeat the standard DQN agent. We conclude by using linear probing to illuminate what internal structures the different agents develop to play the game. We show that training agents with Chainer or Pool leads to richer network activations with greater predictive power to estimate critical game-state features compared to the standard DQN agent.
Value-Based Reinforcement Learning for Continuous Control Robotic Manipulation in Multi-Task Sparse Reward Settings
Jul 28, 2021
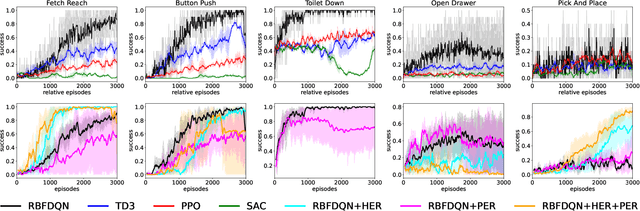
Learning continuous control in high-dimensional sparse reward settings, such as robotic manipulation, is a challenging problem due to the number of samples often required to obtain accurate optimal value and policy estimates. While many deep reinforcement learning methods have aimed at improving sample efficiency through replay or improved exploration techniques, state of the art actor-critic and policy gradient methods still suffer from the hard exploration problem in sparse reward settings. Motivated by recent successes of value-based methods for approximating state-action values, like RBF-DQN, we explore the potential of value-based reinforcement learning for learning continuous robotic manipulation tasks in multi-task sparse reward settings. On robotic manipulation tasks, we empirically show RBF-DQN converges faster than current state of the art algorithms such as TD3, SAC, and PPO. We also perform ablation studies with RBF-DQN and have shown that some enhancement techniques for vanilla Deep Q learning such as Hindsight Experience Replay (HER) and Prioritized Experience Replay (PER) can also be applied to RBF-DQN. Our experimental analysis suggests that value-based approaches may be more sensitive to data augmentation and replay buffer sample techniques than policy-gradient methods, and that the benefits of these methods for robot manipulation are heavily dependent on the transition dynamics of generated subgoal states.
A Domain Generalization Perspective on Listwise Context Modeling
Feb 12, 2019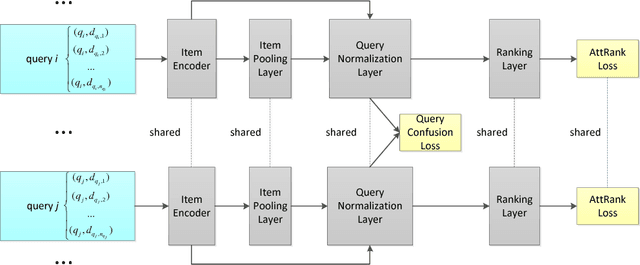
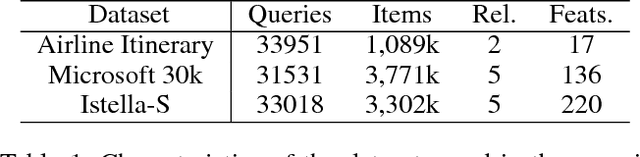
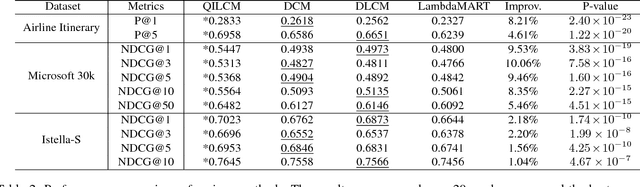
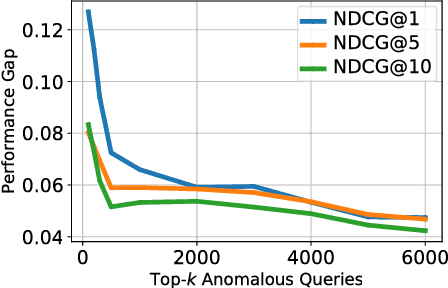
As one of the most popular techniques for solving the ranking problem in information retrieval, Learning-to-rank (LETOR) has received a lot of attention both in academia and industry due to its importance in a wide variety of data mining applications. However, most of existing LETOR approaches choose to learn a single global ranking function to handle all queries, and ignore the substantial differences that exist between queries. In this paper, we propose a domain generalization strategy to tackle this problem. We propose Query-Invariant Listwise Context Modeling (QILCM), a novel neural architecture which eliminates the detrimental influence of inter-query variability by learning \textit{query-invariant} latent representations, such that the ranking system could generalize better to unseen queries. We evaluate our techniques on benchmark datasets, demonstrating that QILCM outperforms previous state-of-the-art approaches by a substantial margin.