 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Meeseeks Mesh: Spatially Consistent 3D Adversarial Objects for BEV Detector
May 29, 20253D object detection is a critical component in autonomous driving systems. It allows real-time recognition and detection of vehicles, pedestrians and obstacles under varying environmental conditions. Among existing methods, 3D object detection in the Bird's Eye View (BEV) has emerged as the mainstream framework. To guarantee a safe, robust and trustworthy 3D object detection, 3D adversarial attacks are investigated, where attacks are placed in 3D environments to evaluate the model performance, e.g. putting a film on a car, clothing a pedestrian. The vulnerability of 3D object detection models to 3D adversarial attacks serves as an important indicator to evaluate the robustness of the model against perturbations. To investigate this vulnerability, we generate non-invasive 3D adversarial objects tailored for real-world attack scenarios. Our method verifies the existence of universal adversarial objects that are spatially consistent across time and camera views. Specifically, we employ differentiable rendering techniques to accurately model the spatial relationship between adversarial objects and the target vehicle. Furthermore, we introduce an occlusion-aware module to enhance visual consistency and realism under different viewpoints. To maintain attack effectiveness across multiple frames, we design a BEV spatial feature-guided optimization strategy. Experimental results demonstrate that our approach can reliably suppress vehicle predictions from state-of-the-art 3D object detectors, serving as an important tool to test robustness of 3D object detection models before deployment. Moreover, the generated adversarial objects exhibit strong generalization capabilities, retaining its effectiveness at various positions and distances in the scene.
A Generative Victim Model for Segmentation
Dec 10, 2024We find that the well-trained victim models (VMs), against which the attacks are generated, serve as fundamental prerequisites for adversarial attacks, i.e. a segmentation VM is needed to generate attacks for segmentation. In this context, the victim model is assumed to be robust to achieve effective adversarial perturbation generation. Instead of focusing on improving the robustness of the task-specific victim models, we shift our attention to image generation. From an image generation perspective, we derive a novel VM for segmentation, aiming to generate adversarial perturbations for segmentation tasks without requiring models explicitly designed for image segmentation. Our approach to adversarial attack generation diverges from conventional white-box or black-box attacks, offering a fresh outlook on adversarial attack strategies. Experiments show that our attack method is able to generate effective adversarial attacks with good transferability.
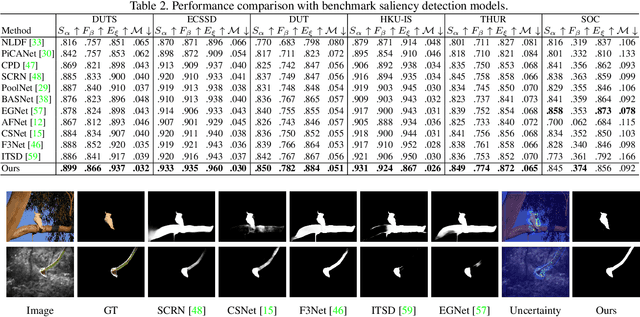
Joint Salient Object Detection and Camouflaged Object Detection via Uncertainty-aware Learning
Jul 10, 2023Salient objects attract human attention and usually stand out clearly from their surroundings. In contrast, camouflaged objects share similar colors or textures with the environment. In this case, salient objects are typically non-camouflaged, and camouflaged objects are usually not salient. Due to this inherent contradictory attribute, we introduce an uncertainty-aware learning pipeline to extensively explore the contradictory information of salient object detection (SOD) and camouflaged object detection (COD) via data-level and task-wise contradiction modeling. We first exploit the dataset correlation of these two tasks and claim that the easy samples in the COD dataset can serve as hard samples for SOD to improve the robustness of the SOD model. Based on the assumption that these two models should lead to activation maps highlighting different regions of the same input image, we further introduce a contrastive module with a joint-task contrastive learning framework to explicitly model the contradictory attributes of these two tasks. Different from conventional intra-task contrastive learning for unsupervised representation learning, our contrastive module is designed to model the task-wise correlation, leading to cross-task representation learning. To better understand the two tasks from the perspective of uncertainty, we extensively investigate the uncertainty estimation techniques for modeling the main uncertainties of the two tasks, namely task uncertainty (for SOD) and data uncertainty (for COD), and aiming to effectively estimate the challenging regions for each task to achieve difficulty-aware learning. Experimental results on benchmark datasets demonstrate that our solution leads to both state-of-the-art performance and informative uncertainty estimation.
Mutual Information Regularization for Weakly-supervised RGB-D Salient Object Detection
Jun 06, 2023



In this paper, we present a weakly-supervised RGB-D salient object detection model via scribble supervision. Specifically, as a multimodal learning task, we focus on effective multimodal representation learning via inter-modal mutual information regularization. In particular, following the principle of disentangled representation learning, we introduce a mutual information upper bound with a mutual information minimization regularizer to encourage the disentangled representation of each modality for salient object detection. Based on our multimodal representation learning framework, we introduce an asymmetric feature extractor for our multimodal data, which is proven more effective than the conventional symmetric backbone setting. We also introduce multimodal variational auto-encoder as stochastic prediction refinement techniques, which takes pseudo labels from the first training stage as supervision and generates refined prediction. Experimental results on benchmark RGB-D salient object detection datasets verify both effectiveness of our explicit multimodal disentangled representation learning method and the stochastic prediction refinement strategy, achieving comparable performance with the state-of-the-art fully supervised models. Our code and data are available at: https://github.com/baneitixiaomai/MIRV.
Fine-grained Audible Video Description
Mar 27, 2023
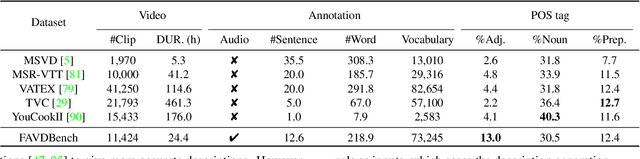
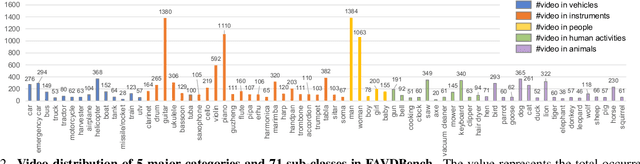
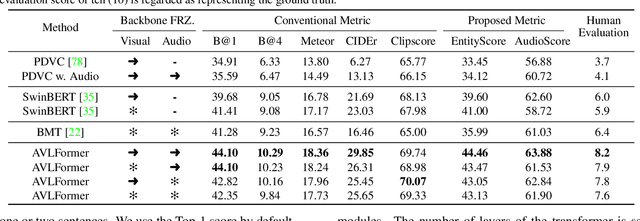
We explore a new task for audio-visual-language modeling called fine-grained audible video description (FAVD). It aims to provide detailed textual descriptions for the given audible videos, including the appearance and spatial locations of each object, the actions of moving objects, and the sounds in videos. Existing visual-language modeling tasks often concentrate on visual cues in videos while undervaluing the language and audio modalities. On the other hand, FAVD requires not only audio-visual-language modeling skills but also paragraph-level language generation abilities. We construct the first fine-grained audible video description benchmark (FAVDBench) to facilitate this research. For each video clip, we first provide a one-sentence summary of the video, ie, the caption, followed by 4-6 sentences describing the visual details and 1-2 audio-related descriptions at the end. The descriptions are provided in both English and Chinese. We create two new metrics for this task: an EntityScore to gauge the completeness of entities in the visual descriptions, and an AudioScore to assess the audio descriptions. As a preliminary approach to this task, we propose an audio-visual-language transformer that extends existing video captioning model with an additional audio branch. We combine the masked language modeling and auto-regressive language modeling losses to optimize our model so that it can produce paragraph-level descriptions. We illustrate the efficiency of our model in audio-visual-language modeling by evaluating it against the proposed benchmark using both conventional captioning metrics and our proposed metrics. We further put our benchmark to the test in video generation models, demonstrating that employing fine-grained video descriptions can create more intricate videos than using captions.
Towards Deeper Understanding of Camouflaged Object Detection
May 23, 2022
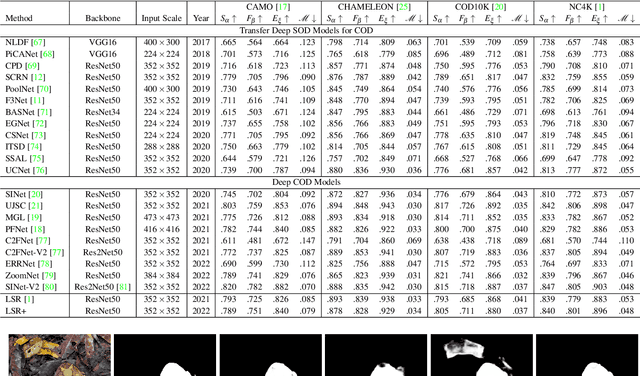

Preys in the wild evolve to be camouflaged to avoid being recognized by predators. In this way, camouflage acts as a key defence mechanism across species that is critical to survival. To detect and segment the whole scope of a camouflaged object, camouflaged object detection (COD) is introduced as a binary segmentation task, with the binary ground truth camouflage map indicating the exact regions of the camouflaged objects. In this paper, we revisit this task and argue that the binary segmentation setting fails to fully understand the concept of camouflage. We find that explicitly modeling the conspicuousness of camouflaged objects against their particular backgrounds can not only lead to a better understanding about camouflage, but also provide guidance to designing more sophisticated camouflage techniques. Furthermore, we observe that it is some specific parts of camouflaged objects that make them detectable by predators. With the above understanding about camouflaged objects, we present the first triple-task learning framework to simultaneously localize, segment and rank camouflaged objects, indicating the conspicuousness level of camouflage. As no corresponding datasets exist for either the localization model or the ranking model, we generate localization maps with an eye tracker, which are then processed according to the instance level labels to generate our ranking-based training and testing dataset. We also contribute the largest COD testing set to comprehensively analyse performance of the camouflaged object detection models. Experimental results show that our triple-task learning framework achieves new state-of-the-art, leading to a more explainable camouflaged object detection network. Our code, data and results are available at: https://github.com/JingZhang617/COD-Rank-Localize-and-Segment.
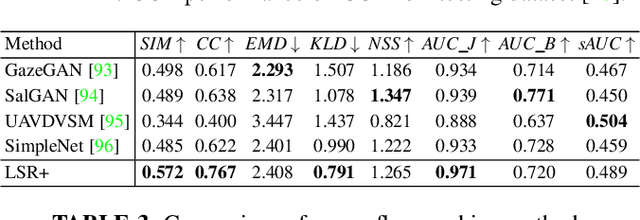
Depth-Guided Camouflaged Object Detection
Jun 26, 2021
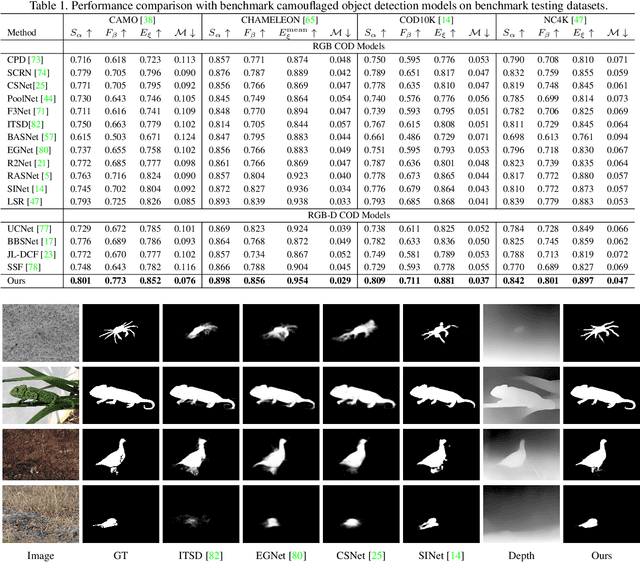
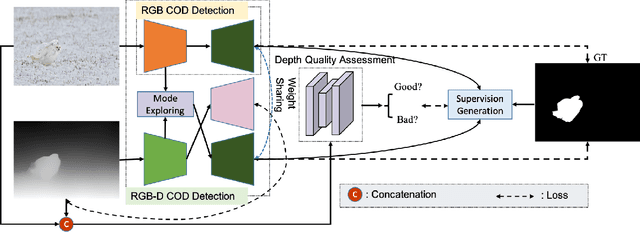

Camouflaged object detection (COD) aims to segment camouflaged objects hiding in the environment, which is challenging due to the similar appearance of camouflaged objects and their surroundings. Research in biology suggests that depth can provide useful object localization cues for camouflaged object discovery, as all the animals have 3D perception ability. However, the depth information has not been exploited for camouflaged object detection. To explore the contribution of depth for camouflage detection, we present a depth-guided camouflaged object detection network with pre-computed depth maps from existing monocular depth estimation methods. Due to the domain gap between the depth estimation dataset and our camouflaged object detection dataset, the generated depth may not be accurate enough to be directly used in our framework. We then introduce a depth quality assessment module to evaluate the quality of depth based on the model prediction from both RGB COD branch and RGB-D COD branch. During training, only high-quality depth is used to update the modal interaction module for multi-modal learning. During testing, our depth quality assessment module can effectively determine the contribution of depth and select the RGB branch or RGB-D branch for camouflage prediction. Extensive experiments on various camouflaged object detection datasets prove the effectiveness of our solution in exploring the depth information for camouflaged object detection. Our code and data is publicly available at: \url{https://github.com/JingZhang617/RGBD-COD}.
Transformer Transforms Salient Object Detection and Camouflaged Object Detection
Apr 20, 2021
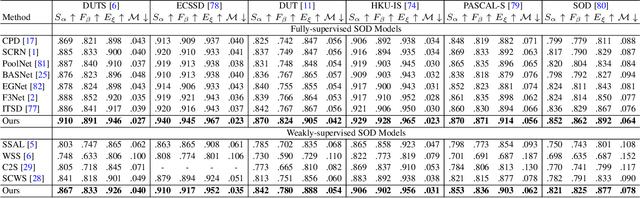
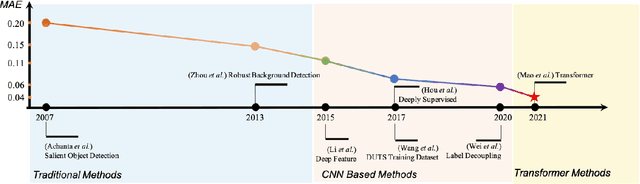
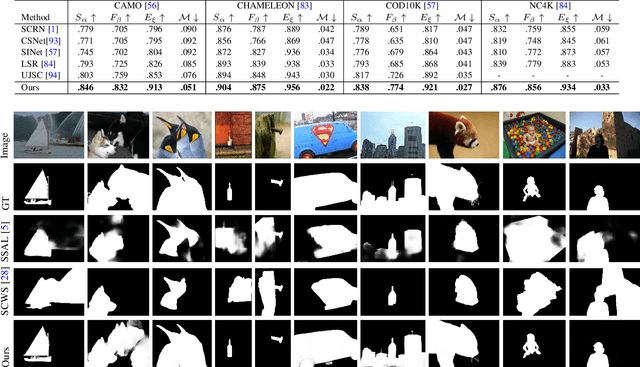
The transformer networks, which originate from machine translation, are particularly good at modeling long-range dependencies within a long sequence. Currently, the transformer networks are making revolutionary progress in various vision tasks ranging from high-level classification tasks to low-level dense prediction tasks. In this paper, we conduct research on applying the transformer networks for salient object detection (SOD). Specifically, we adopt the dense transformer backbone for fully supervised RGB image based SOD, RGB-D image pair based SOD, and weakly supervised SOD via scribble supervision. As an extension, we also apply our fully supervised model to the task of camouflaged object detection (COD) for camouflaged object segmentation. For the fully supervised models, we define the dense transformer backbone as feature encoder, and design a very simple decoder to produce a one channel saliency map (or camouflage map for the COD task). For the weakly supervised model, as there exists no structure information in the scribble annotation, we first adopt the recent proposed Gated-CRF loss to effectively model the pair-wise relationships for accurate model prediction. Then, we introduce self-supervised learning strategy to push the model to produce scale-invariant predictions, which is proven effective for weakly supervised models and models trained on small training datasets. Extensive experimental results on various SOD and COD tasks (fully supervised RGB image based SOD, fully supervised RGB-D image pair based SOD, weakly supervised SOD via scribble supervision, and fully supervised RGB image based COD) illustrate that transformer networks can transform salient object detection and camouflaged object detection, leading to new benchmarks for each related task.
Uncertainty-aware Joint Salient Object and Camouflaged Object Detection
Apr 06, 2021
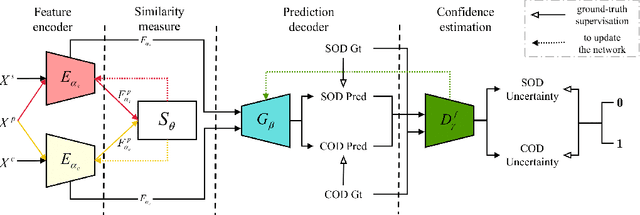
Visual salient object detection (SOD) aims at finding the salient object(s) that attract human attention, while camouflaged object detection (COD) on the contrary intends to discover the camouflaged object(s) that hidden in the surrounding. In this paper, we propose a paradigm of leveraging the contradictory information to enhance the detection ability of both salient object detection and camouflaged object detection. We start by exploiting the easy positive samples in the COD dataset to serve as hard positive samples in the SOD task to improve the robustness of the SOD model. Then, we introduce a similarity measure module to explicitly model the contradicting attributes of these two tasks. Furthermore, considering the uncertainty of labeling in both tasks' datasets, we propose an adversarial learning network to achieve both higher order similarity measure and network confidence estimation. Experimental results on benchmark datasets demonstrate that our solution leads to state-of-the-art (SOTA) performance for both tasks.
Simultaneously Localize, Segment and Rank the Camouflaged Objects
Mar 06, 2021
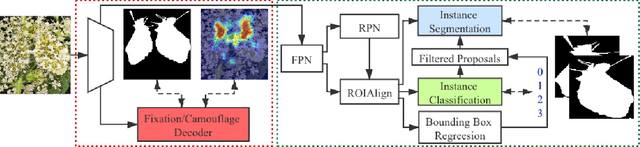


Camouflage is a key defence mechanism across species that is critical to survival. Common strategies for camouflage include background matching, imitating the color and pattern of the environment, and disruptive coloration, disguising body outlines [35]. Camouflaged object detection (COD) aims to segment camouflaged objects hiding in their surroundings. Existing COD models are built upon binary ground truth to segment the camouflaged objects without illustrating the level of camouflage. In this paper, we revisit this task and argue that explicitly modeling the conspicuousness of camouflaged objects against their particular backgrounds can not only lead to a better understanding about camouflage and evolution of animals, but also provide guidance to design more sophisticated camouflage techniques. Furthermore, we observe that it is some specific parts of the camouflaged objects that make them detectable by predators. With the above understanding about camouflaged objects, we present the first ranking based COD network (Rank-Net) to simultaneously localize, segment and rank camouflaged objects. The localization model is proposed to find the discriminative regions that make the camouflaged object obvious. The segmentation model segments the full scope of the camouflaged objects. And, the ranking model infers the detectability of different camouflaged objects. Moreover, we contribute a large COD testing set to evaluate the generalization ability of COD models. Experimental results show that our model achieves new state-of-the-art, leading to a more interpretable COD network.