 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Emotion Recognition: A Multi-Turn Multimodal Emotion Understanding and Reasoning Benchmark
Aug 23, 2025Multimodal large language models (MLLMs) have been widely applied across various fields due to their powerful perceptual and reasoning capabilities. In the realm of psychology, these models hold promise for a deeper understanding of human emotions and behaviors. However, recent research primarily focuses on enhancing their emotion recognition abilities, leaving the substantial potential in emotion reasoning, which is crucial for improving the naturalness and effectiveness of human-machine interactions. Therefore, in this paper, we introduce a multi-turn multimodal emotion understanding and reasoning (MTMEUR) benchmark, which encompasses 1,451 video data from real-life scenarios, along with 5,101 progressive questions. These questions cover various aspects, including emotion recognition, potential causes of emotions, future action prediction, etc. Besides, we propose a multi-agent framework, where each agent specializes in a specific aspect, such as background context, character dynamics, and event details, to improve the system's reasoning capabilities. Furthermore, we conduct experiments with existing MLLMs and our agent-based method on the proposed benchmark, revealing that most models face significant challenges with this task.
Towards Efficient Partially Relevant Video Retrieval with Active Moment Discovering
Apr 15, 2025



Partially relevant video retrieval (PRVR) is a practical yet challenging task in text-to-video retrieval, where videos are untrimmed and contain much background content. The pursuit here is of both effective and efficient solutions to capture the partial correspondence between text queries and untrimmed videos. Existing PRVR methods, which typically focus on modeling multi-scale clip representations, however, suffer from content independence and information redundancy, impairing retrieval performance. To overcome these limitations, we propose a simple yet effective approach with active moment discovering (AMDNet). We are committed to discovering video moments that are semantically consistent with their queries. By using learnable span anchors to capture distinct moments and applying masked multi-moment attention to emphasize salient moments while suppressing redundant backgrounds, we achieve more compact and informative video representations. To further enhance moment modeling, we introduce a moment diversity loss to encourage different moments of distinct regions and a moment relevance loss to promote semantically query-relevant moments, which cooperate with a partially relevant retrieval loss for end-to-end optimization. Extensive experiments on two large-scale video datasets (\ie, TVR and ActivityNet Captions) demonstrate the superiority and efficiency of our AMDNet. In particular, AMDNet is about 15.5 times smaller (\#parameters) while 6.0 points higher (SumR) than the up-to-date method GMMFormer on TVR.
Linguistics-Vision Monotonic Consistent Network for Sign Language Production
Dec 22, 2024

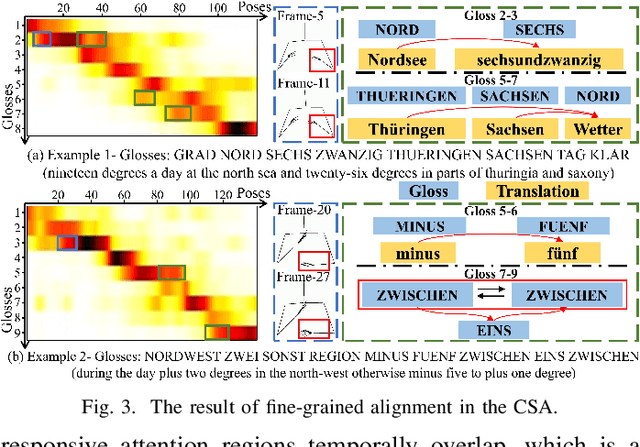

Sign Language Production (SLP) aims to generate sign videos corresponding to spoken language sentences, where the conversion of sign Glosses to Poses (G2P) is the key step. Due to the cross-modal semantic gap and the lack of word-action correspondence labels for strong supervision alignment, the SLP suffers huge challenges in linguistics-vision consistency. In this work, we propose a Transformer-based Linguistics-Vision Monotonic Consistent Network (LVMCN) for SLP, which constrains fine-grained cross-modal monotonic alignment and coarse-grained multimodal semantic consistency in language-visual cues through Cross-modal Semantic Aligner (CSA) and Multimodal Semantic Comparator (MSC). In the CSA, we constrain the implicit alignment between corresponding gloss and pose sequences by computing the cosine similarity association matrix between cross-modal feature sequences (i.e., the order consistency of fine-grained sign glosses and actions). As for MSC, we construct multimodal triplets based on paired and unpaired samples in batch data. By pulling closer the corresponding text-visual pairs and pushing apart the non-corresponding text-visual pairs, we constrain the semantic co-occurrence degree between corresponding gloss and pose sequences (i.e., the semantic consistency of coarse-grained textual sentences and sign videos). Extensive experiments on the popular PHOENIX14T benchmark show that the LVMCN outperforms the state-of-the-art.
Scene-Text Grounding for Text-Based Video Question Answering
Sep 22, 2024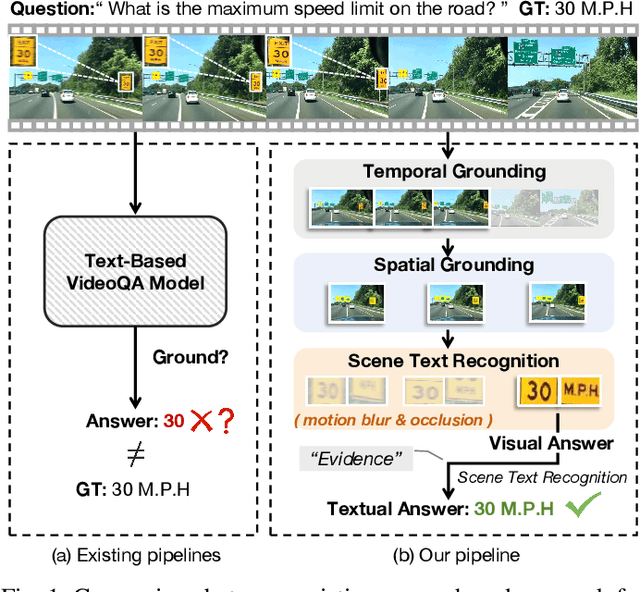
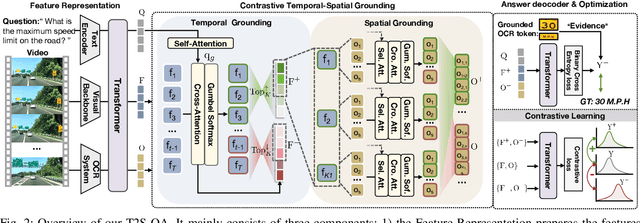
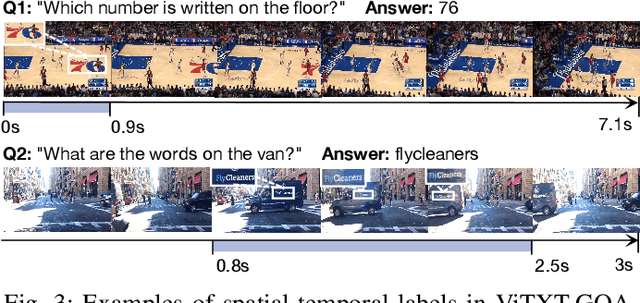
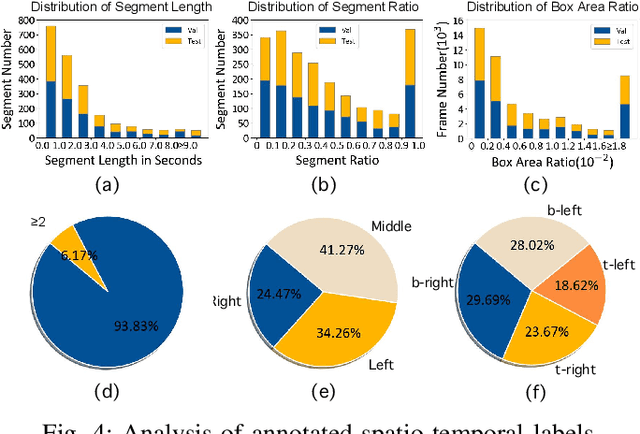
Existing efforts in text-based video question answering (TextVideoQA) are criticized for their opaque decisionmaking and heavy reliance on scene-text recognition. In this paper, we propose to study Grounded TextVideoQA by forcing models to answer questions and spatio-temporally localize the relevant scene-text regions, thus decoupling QA from scenetext recognition and promoting research towards interpretable QA. The task has three-fold significance. First, it encourages scene-text evidence versus other short-cuts for answer predictions. Second, it directly accepts scene-text regions as visual answers, thus circumventing the problem of ineffective answer evaluation by stringent string matching. Third, it isolates the challenges inherited in VideoQA and scene-text recognition. This enables the diagnosis of the root causes for failure predictions, e.g., wrong QA or wrong scene-text recognition? To achieve Grounded TextVideoQA, we propose the T2S-QA model that highlights a disentangled temporal-to-spatial contrastive learning strategy for weakly-supervised scene-text grounding and grounded TextVideoQA. To facilitate evaluation, we construct a new dataset ViTXT-GQA which features 52K scene-text bounding boxes within 2.2K temporal segments related to 2K questions and 729 videos. With ViTXT-GQA, we perform extensive experiments and demonstrate the severe limitations of existing techniques in Grounded TextVideoQA. While T2S-QA achieves superior results, the large performance gap with human leaves ample space for improvement. Our further analysis of oracle scene-text inputs posits that the major challenge is scene-text recognition. To advance the research of Grounded TextVideoQA, our dataset and code are at \url{https://github.com/zhousheng97/ViTXT-GQA.git}
Learning Gaussian Representation for Eye Fixation Prediction
Mar 21, 2024



Existing eye fixation prediction methods perform the mapping from input images to the corresponding dense fixation maps generated from raw fixation points. However, due to the stochastic nature of human fixation, the generated dense fixation maps may be a less-than-ideal representation of human fixation. To provide a robust fixation model, we introduce Gaussian Representation for eye fixation modeling. Specifically, we propose to model the eye fixation map as a mixture of probability distributions, namely a Gaussian Mixture Model. In this new representation, we use several Gaussian distribution components as an alternative to the provided fixation map, which makes the model more robust to the randomness of fixation. Meanwhile, we design our framework upon some lightweight backbones to achieve real-time fixation prediction. Experimental results on three public fixation prediction datasets (SALICON, MIT1003, TORONTO) demonstrate that our method is fast and effective.
Recurrent Relational Memory Network for Unsupervised Image Captioning
Jun 24, 2020

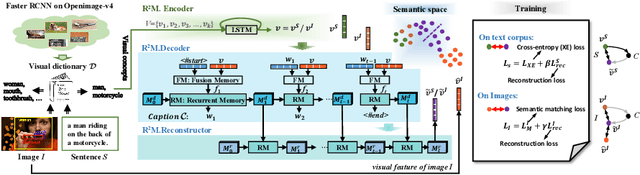

Unsupervised image captioning with no annotations is an emerging challenge in computer vision, where the existing arts usually adopt GAN (Generative Adversarial Networks) models. In this paper, we propose a novel memory-based network rather than GAN, named Recurrent Relational Memory Network ($R^2M$). Unlike complicated and sensitive adversarial learning that non-ideally performs for long sentence generation, $R^2M$ implements a concepts-to-sentence memory translator through two-stage memory mechanisms: fusion and recurrent memories, correlating the relational reasoning between common visual concepts and the generated words for long periods. $R^2M$ encodes visual context through unsupervised training on images, while enabling the memory to learn from irrelevant textual corpus via supervised fashion. Our solution enjoys less learnable parameters and higher computational efficiency than GAN-based methods, which heavily bear parameter sensitivity. We experimentally validate the superiority of $R^2M$ than state-of-the-arts on all benchmark datasets.
Weakly-Supervised Salient Object Detection via Scribble Annotations
Mar 17, 2020



Compared with laborious pixel-wise dense labeling, it is much easier to label data by scribbles, which only costs 1$\sim$2 seconds to label one image. However, using scribble labels to learn salient object detection has not been explored. In this paper, we propose a weakly-supervised salient object detection model to learn saliency from such annotations. In doing so, we first relabel an existing large-scale salient object detection dataset with scribbles, namely S-DUTS dataset. Since object structure and detail information is not identified by scribbles, directly training with scribble labels will lead to saliency maps of poor boundary localization. To mitigate this problem, we propose an auxiliary edge detection task to localize object edges explicitly, and a gated structure-aware loss to place constraints on the scope of structure to be recovered. Moreover, we design a scribble boosting scheme to iteratively consolidate our scribble annotations, which are then employed as supervision to learn high-quality saliency maps. As existing saliency evaluation metrics neglect to measure structure alignment of the predictions, the saliency map ranking metric may not comply with human perception. We present a new metric, termed saliency structure measure, to measure the structure alignment of the predicted saliency maps, which is more consistent with human perception. Extensive experiments on six benchmark datasets demonstrate that our method not only outperforms existing weakly-supervised/unsupervised methods, but also is on par with several fully-supervised state-of-the-art models. Our code and data is publicly available at https://github.com/JingZhang617/Scribble_Saliency.