 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinguistics-Vision Monotonic Consistent Network for Sign Language Production
Paper and Code
Dec 22, 2024

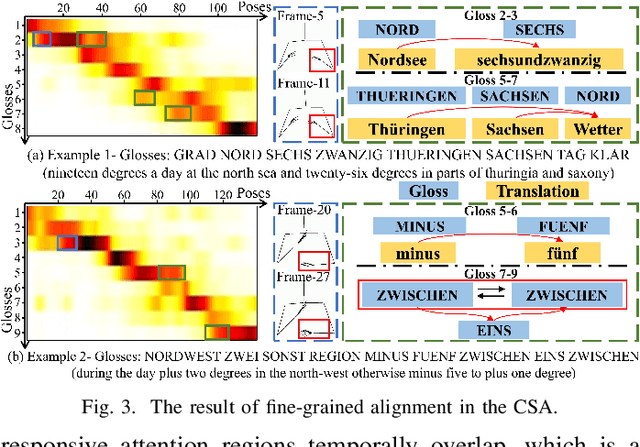

Sign Language Production (SLP) aims to generate sign videos corresponding to spoken language sentences, where the conversion of sign Glosses to Poses (G2P) is the key step. Due to the cross-modal semantic gap and the lack of word-action correspondence labels for strong supervision alignment, the SLP suffers huge challenges in linguistics-vision consistency. In this work, we propose a Transformer-based Linguistics-Vision Monotonic Consistent Network (LVMCN) for SLP, which constrains fine-grained cross-modal monotonic alignment and coarse-grained multimodal semantic consistency in language-visual cues through Cross-modal Semantic Aligner (CSA) and Multimodal Semantic Comparator (MSC). In the CSA, we constrain the implicit alignment between corresponding gloss and pose sequences by computing the cosine similarity association matrix between cross-modal feature sequences (i.e., the order consistency of fine-grained sign glosses and actions). As for MSC, we construct multimodal triplets based on paired and unpaired samples in batch data. By pulling closer the corresponding text-visual pairs and pushing apart the non-corresponding text-visual pairs, we constrain the semantic co-occurrence degree between corresponding gloss and pose sequences (i.e., the semantic consistency of coarse-grained textual sentences and sign videos). Extensive experiments on the popular PHOENIX14T benchmark show that the LVMCN outperforms the state-of-the-art.