 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstance-Level Moving Object Segmentation from a Single Image with Events
Feb 18, 2025Moving object segmentation plays a crucial role in understanding dynamic scenes involving multiple moving objects, while the difficulties lie in taking into account both spatial texture structures and temporal motion cues. Existing methods based on video frames encounter difficulties in distinguishing whether pixel displacements of an object are caused by camera motion or object motion due to the complexities of accurate image-based motion modeling. Recent advances exploit the motion sensitivity of novel event cameras to counter conventional images' inadequate motion modeling capabilities, but instead lead to challenges in segmenting pixel-level object masks due to the lack of dense texture structures in events. To address these two limitations imposed by unimodal settings, we propose the first instance-level moving object segmentation framework that integrates complementary texture and motion cues. Our model incorporates implicit cross-modal masked attention augmentation, explicit contrastive feature learning, and flow-guided motion enhancement to exploit dense texture information from a single image and rich motion information from events, respectively. By leveraging the augmented texture and motion features, we separate mask segmentation from motion classification to handle varying numbers of independently moving objects. Through extensive evaluations on multiple datasets, as well as ablation experiments with different input settings and real-time efficiency analysis of the proposed framework, we believe that our first attempt to incorporate image and event data for practical deployment can provide new insights for future work in event-based motion related works. The source code with model training and pre-trained weights is released at https://npucvr.github.io/EvInsMOS
RPEFlow: Multimodal Fusion of RGB-PointCloud-Event for Joint Optical Flow and Scene Flow Estimation
Sep 26, 2023

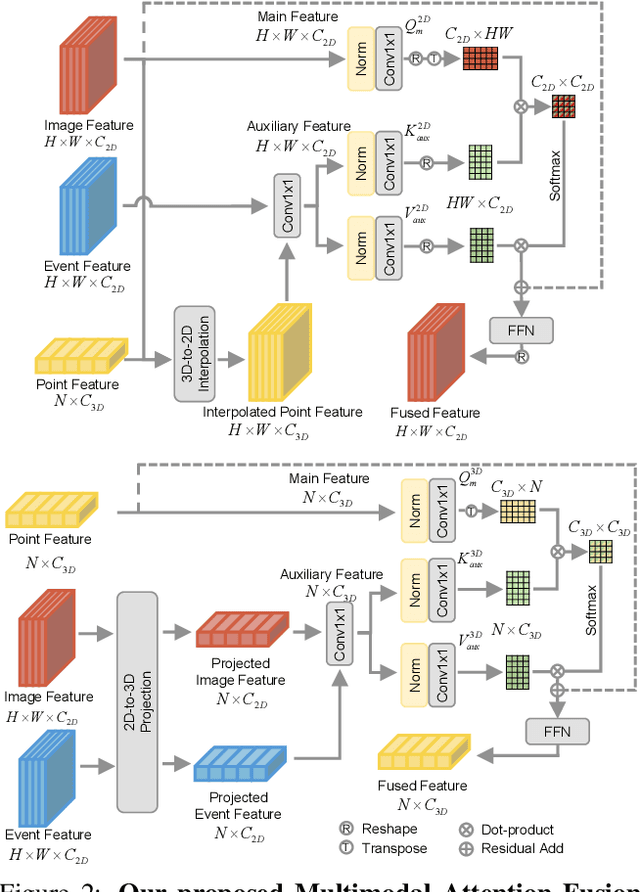

Recently, the RGB images and point clouds fusion methods have been proposed to jointly estimate 2D optical flow and 3D scene flow. However, as both conventional RGB cameras and LiDAR sensors adopt a frame-based data acquisition mechanism, their performance is limited by the fixed low sampling rates, especially in highly-dynamic scenes. By contrast, the event camera can asynchronously capture the intensity changes with a very high temporal resolution, providing complementary dynamic information of the observed scenes. In this paper, we incorporate RGB images, Point clouds and Events for joint optical flow and scene flow estimation with our proposed multi-stage multimodal fusion model, RPEFlow. First, we present an attention fusion module with a cross-attention mechanism to implicitly explore the internal cross-modal correlation for 2D and 3D branches, respectively. Second, we introduce a mutual information regularization term to explicitly model the complementary information of three modalities for effective multimodal feature learning. We also contribute a new synthetic dataset to advocate further research. Experiments on both synthetic and real datasets show that our model outperforms the existing state-of-the-art by a wide margin. Code and dataset is available at https://npucvr.github.io/RPEFlow.
Learning Dense and Continuous Optical Flow from an Event Camera
Nov 16, 2022



Event cameras such as DAVIS can simultaneously output high temporal resolution events and low frame-rate intensity images, which own great potential in capturing scene motion, such as optical flow estimation. Most of the existing optical flow estimation methods are based on two consecutive image frames and can only estimate discrete flow at a fixed time interval. Previous work has shown that continuous flow estimation can be achieved by changing the quantities or time intervals of events. However, they are difficult to estimate reliable dense flow , especially in the regions without any triggered events. In this paper, we propose a novel deep learning-based dense and continuous optical flow estimation framework from a single image with event streams, which facilitates the accurate perception of high-speed motion. Specifically, we first propose an event-image fusion and correlation module to effectively exploit the internal motion from two different modalities of data. Then we propose an iterative update network structure with bidirectional training for optical flow prediction. Therefore, our model can estimate reliable dense flow as two-frame-based methods, as well as estimate temporal continuous flow as event-based methods. Extensive experimental results on both synthetic and real captured datasets demonstrate that our model outperforms existing event-based state-of-the-art methods and our designed baselines for accurate dense and continuous optical flow estimation.
Deep Idempotent Network for Efficient Single Image Blind Deblurring
Oct 18, 2022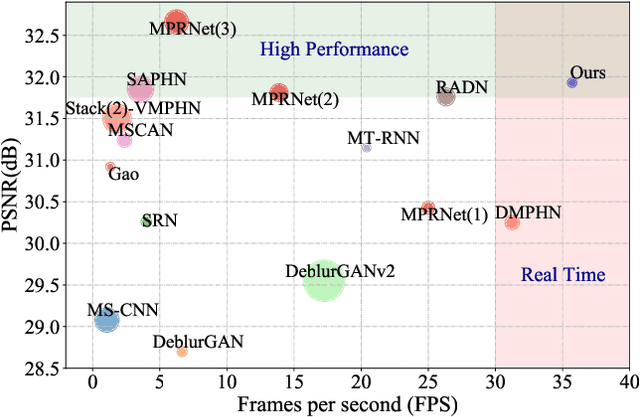



Single image blind deblurring is highly ill-posed as neither the latent sharp image nor the blur kernel is known. Even though considerable progress has been made, several major difficulties remain for blind deblurring, including the trade-off between high-performance deblurring and real-time processing. Besides, we observe that current single image blind deblurring networks cannot further improve or stabilize the performance but significantly degrades the performance when re-deblurring is repeatedly applied. This implies the limitation of these networks in modeling an ideal deblurring process. In this work, we make two contributions to tackle the above difficulties: (1) We introduce the idempotent constraint into the deblurring framework and present a deep idempotent network to achieve improved blind non-uniform deblurring performance with stable re-deblurring. (2) We propose a simple yet efficient deblurring network with lightweight encoder-decoder units and a recurrent structure that can deblur images in a progressive residual fashion. Extensive experiments on synthetic and realistic datasets prove the superiority of our proposed framework. Remarkably, our proposed network is nearly 6.5X smaller and 6.4X faster than the state-of-the-art while achieving comparable high performance.
Transformer Transforms Salient Object Detection and Camouflaged Object Detection
Apr 20, 2021
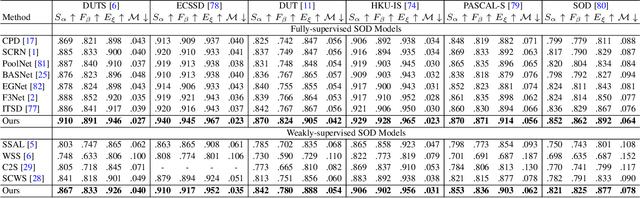
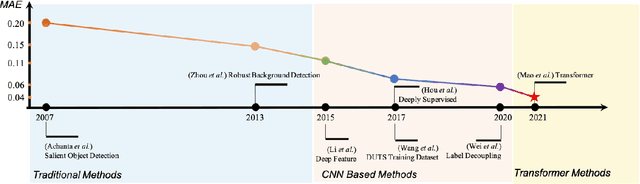
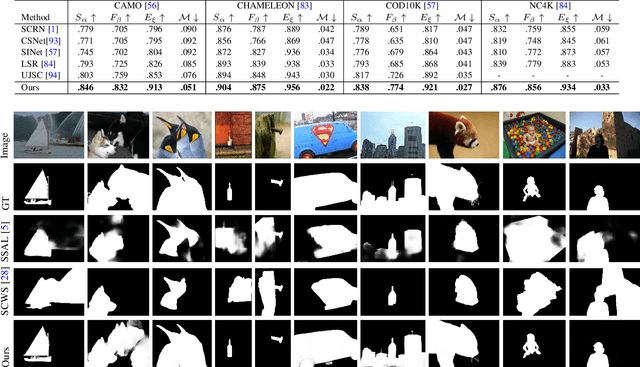
The transformer networks, which originate from machine translation, are particularly good at modeling long-range dependencies within a long sequence. Currently, the transformer networks are making revolutionary progress in various vision tasks ranging from high-level classification tasks to low-level dense prediction tasks. In this paper, we conduct research on applying the transformer networks for salient object detection (SOD). Specifically, we adopt the dense transformer backbone for fully supervised RGB image based SOD, RGB-D image pair based SOD, and weakly supervised SOD via scribble supervision. As an extension, we also apply our fully supervised model to the task of camouflaged object detection (COD) for camouflaged object segmentation. For the fully supervised models, we define the dense transformer backbone as feature encoder, and design a very simple decoder to produce a one channel saliency map (or camouflage map for the COD task). For the weakly supervised model, as there exists no structure information in the scribble annotation, we first adopt the recent proposed Gated-CRF loss to effectively model the pair-wise relationships for accurate model prediction. Then, we introduce self-supervised learning strategy to push the model to produce scale-invariant predictions, which is proven effective for weakly supervised models and models trained on small training datasets. Extensive experimental results on various SOD and COD tasks (fully supervised RGB image based SOD, fully supervised RGB-D image pair based SOD, weakly supervised SOD via scribble supervision, and fully supervised RGB image based COD) illustrate that transformer networks can transform salient object detection and camouflaged object detection, leading to new benchmarks for each related task.
PRAFlow_RVC: Pyramid Recurrent All-Pairs Field Transforms for Optical Flow Estimation in Robust Vision Challenge 2020
Sep 14, 2020

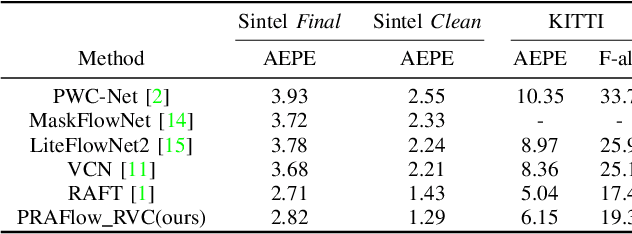

Optical flow estimation is an important computer vision task, which aims at estimating the dense correspondences between two frames. RAFT (Recurrent All Pairs Field Transforms) currently represents the state-of-the-art in optical flow estimation. It has excellent generalization ability and has obtained outstanding results across several benchmarks. To further improve the robustness and achieve accurate optical flow estimation, we present PRAFlow (Pyramid Recurrent All-Pairs Flow), which builds upon the pyramid network structure. Due to computational limitation, our proposed network structure only uses two pyramid layers. At each layer, the RAFT unit is used to estimate the optical flow at the current resolution. Our model was trained on several simulate and real-image datasets, submitted to multiple leaderboards using the same model and parameters, and won the 2nd place in the optical flow task of ECCV 2020 workshop: Robust Vision Challenge.