 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes DQN really learn? Exploring adversarial training schemes in Pong
Mar 20, 2022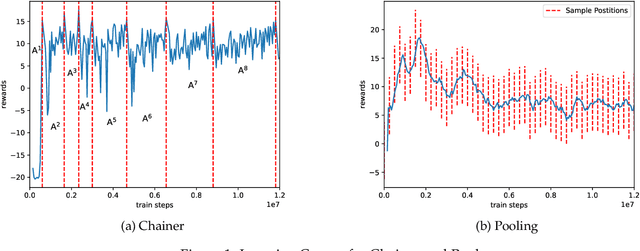
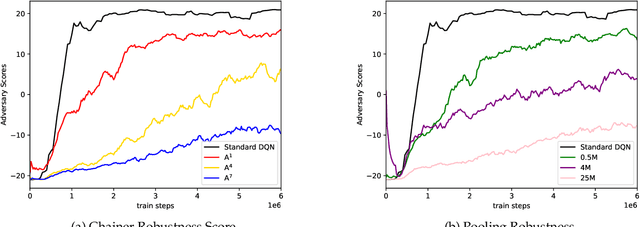

In this work, we study two self-play training schemes, Chainer and Pool, and show they lead to improved agent performance in Atari Pong compared to a standard DQN agent -- trained against the built-in Atari opponent. To measure agent performance, we define a robustness metric that captures how difficult it is to learn a strategy that beats the agent's learned policy. Through playing past versions of themselves, Chainer and Pool are able to target weaknesses in their policies and improve their resistance to attack. Agents trained using these methods score well on our robustness metric and can easily defeat the standard DQN agent. We conclude by using linear probing to illuminate what internal structures the different agents develop to play the game. We show that training agents with Chainer or Pool leads to richer network activations with greater predictive power to estimate critical game-state features compared to the standard DQN agent.
Streamlining Tensor and Network Pruning in PyTorch
Apr 28, 2020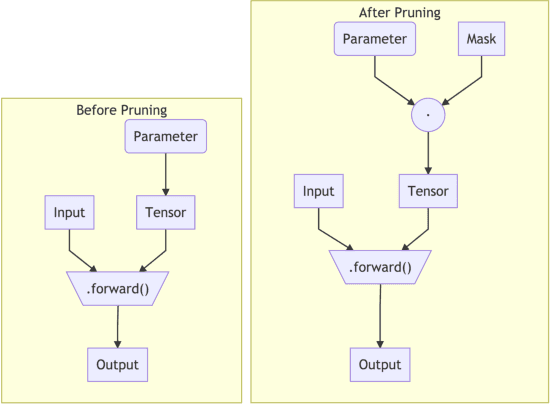
In order to contrast the explosion in size of state-of-the-art machine learning models that can be attributed to the empirical advantages of over-parametrization, and due to the necessity of deploying fast, sustainable, and private on-device models on resource-constrained devices, the community has focused on techniques such as pruning, quantization, and distillation as central strategies for model compression. Towards the goal of facilitating the adoption of a common interface for neural network pruning in PyTorch, this contribution describes the recent addition of the PyTorch torch.nn.utils.prune module, which provides shared, open source pruning functionalities to lower the technical implementation barrier to reducing model size and capacity before, during, and/or after training. We present the module's user interface, elucidate implementation details, illustrate example usage, and suggest ways to extend the contributed functionalities to new pruning methods.
On Iterative Neural Network Pruning, Reinitialization, and the Similarity of Masks
Jan 14, 2020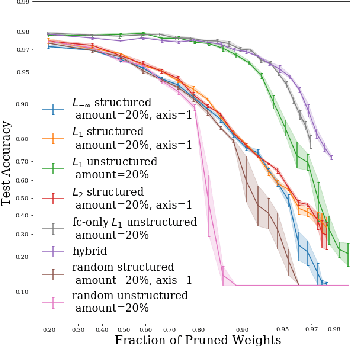

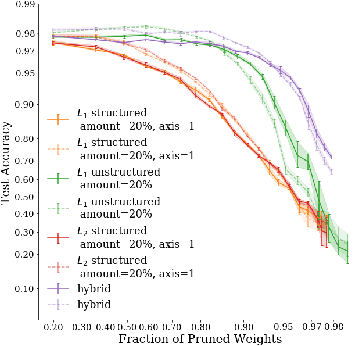
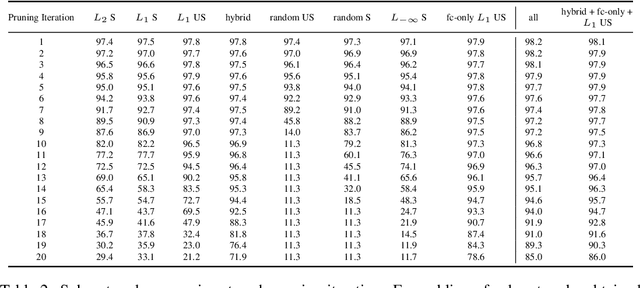
We examine how recently documented, fundamental phenomena in deep learning models subject to pruning are affected by changes in the pruning procedure. Specifically, we analyze differences in the connectivity structure and learning dynamics of pruned models found through a set of common iterative pruning techniques, to address questions of uniqueness of trainable, high-sparsity sub-networks, and their dependence on the chosen pruning method. In convolutional layers, we document the emergence of structure induced by magnitude-based unstructured pruning in conjunction with weight rewinding that resembles the effects of structured pruning. We also show empirical evidence that weight stability can be automatically achieved through apposite pruning techniques.