 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreamlining Tensor and Network Pruning in PyTorch
Paper and Code
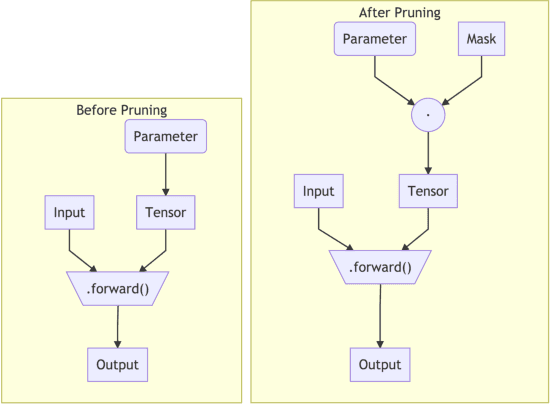
In order to contrast the explosion in size of state-of-the-art machine learning models that can be attributed to the empirical advantages of over-parametrization, and due to the necessity of deploying fast, sustainable, and private on-device models on resource-constrained devices, the community has focused on techniques such as pruning, quantization, and distillation as central strategies for model compression. Towards the goal of facilitating the adoption of a common interface for neural network pruning in PyTorch, this contribution describes the recent addition of the PyTorch torch.nn.utils.prune module, which provides shared, open source pruning functionalities to lower the technical implementation barrier to reducing model size and capacity before, during, and/or after training. We present the module's user interface, elucidate implementation details, illustrate example usage, and suggest ways to extend the contributed functionalities to new pruning methods.