 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHy-MT2: A Family of Fast, Efficient and Powerful Multilingual Translation Models in the Wild
May 21, 2026Hy-MT2 is a family of fast-thinking multilingual translation models designed for complex real-world scenarios. It includes three model sizes: 1.8B, 7B, and 30B-A3B (MoE), all of which support translation among 33 languages and effectively follow translation instructions in multiple languages. For on-device deployment, with AngelSlim 1.25-bit extreme quantization, the 1.8B model requires only 440 MB of storage and improves inference speed by 1.5x. Multi-dimensional evaluations show that Hy-MT2 delivers outstanding performance across general, real-world business, domain-specific, and instruction-following translation tasks. The 7B and 30B models outperform open-source models such as DeepSeek-V4-Pro and Kimi K2.6 in fast-thinking mode, while the lightweight 1.8B model also surpasses mainstream commercial APIs from providers such as Microsoft and Doubao overall.
SparseForge: Efficient Semi-Structured LLM Sparsification via Annealing of Hessian-Guided Soft-Mask
May 07, 2026Semi-structured sparsity provides a practical path to accelerate large language models (LLMs) with native hardware support, but post-training semi-structured pruning often suffers from substantial quality degradation due to strong structural coupling. Existing methods rely on large-scale sparse retraining to recover accuracy, resulting in high computational cost. We propose SparseForge, a post-training framework that improves recovery efficiency by directly optimizing the sparsity mask rather than scaling up retraining tokens. SparseForge combines Hessian-aware importance estimation with progressive annealing of soft masks into hardware-executable structured sparsity, enabling stable and efficient sparse recovery. On LLaMA-2-7B under 2:4 sparsity, SparseForge achieves 57.27% average zero-shot accuracy with only $\textbf{5B}$ retraining tokens, surpassing the dense model's 56.43% accuracy and approaching the 57.52% result of a state-of-the-art method using $\textbf{40B}$ tokens. Such improvements on the accuracy-efficiency trade-off from SparseForge are shown to be consistent across model families.
CCrepairBench: A High-Fidelity Benchmark and Reinforcement Learning Framework for C++ Compilation Repair
Sep 19, 2025



The automated repair of C++ compilation errors presents a significant challenge, the resolution of which is critical for developer productivity. Progress in this domain is constrained by two primary factors: the scarcity of large-scale, high-fidelity datasets and the limitations of conventional supervised methods, which often fail to generate semantically correct patches.This paper addresses these gaps by introducing a comprehensive framework with three core contributions. First, we present CCrepair, a novel, large-scale C++ compilation error dataset constructed through a sophisticated generate-and-verify pipeline. Second, we propose a Reinforcement Learning (RL) paradigm guided by a hybrid reward signal, shifting the focus from mere compilability to the semantic quality of the fix. Finally, we establish the robust, two-stage evaluation system providing this signal, centered on an LLM-as-a-Judge whose reliability has been rigorously validated against the collective judgments of a panel of human experts. This integrated approach aligns the training objective with generating high-quality, non-trivial patches that are both syntactically and semantically correct. The effectiveness of our approach was demonstrated experimentally. Our RL-trained Qwen2.5-1.5B-Instruct model achieved performance comparable to a Qwen2.5-14B-Instruct model, validating the efficiency of our training paradigm. Our work provides the research community with a valuable new dataset and a more effective paradigm for training and evaluating robust compilation repair models, paving the way for more practical and reliable automated programming assistants.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
CDI3D: Cross-guided Dense-view Interpolation for 3D Reconstruction
Mar 11, 20253D object reconstruction from single-view image is a fundamental task in computer vision with wide-ranging applications. Recent advancements in Large Reconstruction Models (LRMs) have shown great promise in leveraging multi-view images generated by 2D diffusion models to extract 3D content. However, challenges remain as 2D diffusion models often struggle to produce dense images with strong multi-view consistency, and LRMs tend to amplify these inconsistencies during the 3D reconstruction process. Addressing these issues is critical for achieving high-quality and efficient 3D reconstruction. In this paper, we present CDI3D, a feed-forward framework designed for efficient, high-quality image-to-3D generation with view interpolation. To tackle the aforementioned challenges, we propose to integrate 2D diffusion-based view interpolation into the LRM pipeline to enhance the quality and consistency of the generated mesh. Specifically, our approach introduces a Dense View Interpolation (DVI) module, which synthesizes interpolated images between main views generated by the 2D diffusion model, effectively densifying the input views with better multi-view consistency. We also design a tilt camera pose trajectory to capture views with different elevations and perspectives. Subsequently, we employ a tri-plane-based mesh reconstruction strategy to extract robust tokens from these interpolated and original views, enabling the generation of high-quality 3D meshes with superior texture and geometry. Extensive experiments demonstrate that our method significantly outperforms previous state-of-the-art approaches across various benchmarks, producing 3D content with enhanced texture fidelity and geometric accuracy.
Pandora3D: A Comprehensive Framework for High-Quality 3D Shape and Texture Generation
Feb 21, 2025This report presents a comprehensive framework for generating high-quality 3D shapes and textures from diverse input prompts, including single images, multi-view images, and text descriptions. The framework consists of 3D shape generation and texture generation. (1). The 3D shape generation pipeline employs a Variational Autoencoder (VAE) to encode implicit 3D geometries into a latent space and a diffusion network to generate latents conditioned on input prompts, with modifications to enhance model capacity. An alternative Artist-Created Mesh (AM) generation approach is also explored, yielding promising results for simpler geometries. (2). Texture generation involves a multi-stage process starting with frontal images generation followed by multi-view images generation, RGB-to-PBR texture conversion, and high-resolution multi-view texture refinement. A consistency scheduler is plugged into every stage, to enforce pixel-wise consistency among multi-view textures during inference, ensuring seamless integration. The pipeline demonstrates effective handling of diverse input formats, leveraging advanced neural architectures and novel methodologies to produce high-quality 3D content. This report details the system architecture, experimental results, and potential future directions to improve and expand the framework. The source code and pretrained weights are released at: https://github.com/Tencent/Tencent-XR-3DGen.
MARS: Mesh AutoRegressive Model for 3D Shape Detailization
Feb 17, 2025

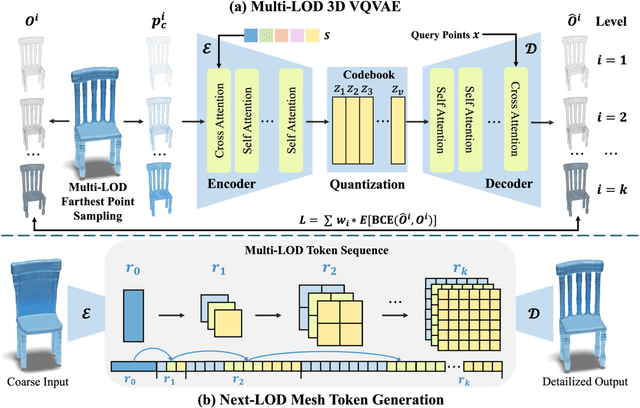

State-of-the-art methods for mesh detailization predominantly utilize Generative Adversarial Networks (GANs) to generate detailed meshes from coarse ones. These methods typically learn a specific style code for each category or similar categories without enforcing geometry supervision across different Levels of Detail (LODs). Consequently, such methods often fail to generalize across a broader range of categories and cannot ensure shape consistency throughout the detailization process. In this paper, we introduce MARS, a novel approach for 3D shape detailization. Our method capitalizes on a novel multi-LOD, multi-category mesh representation to learn shape-consistent mesh representations in latent space across different LODs. We further propose a mesh autoregressive model capable of generating such latent representations through next-LOD token prediction. This approach significantly enhances the realism of the generated shapes. Extensive experiments conducted on the challenging 3D Shape Detailization benchmark demonstrate that our proposed MARS model achieves state-of-the-art performance, surpassing existing methods in both qualitative and quantitative assessments. Notably, the model's capability to generate fine-grained details while preserving the overall shape integrity is particularly commendable.
MiniMax-01: Scaling Foundation Models with Lightning Attention
Jan 14, 2025We introduce MiniMax-01 series, including MiniMax-Text-01 and MiniMax-VL-01, which are comparable to top-tier models while offering superior capabilities in processing longer contexts. The core lies in lightning attention and its efficient scaling. To maximize computational capacity, we integrate it with Mixture of Experts (MoE), creating a model with 32 experts and 456 billion total parameters, of which 45.9 billion are activated for each token. We develop an optimized parallel strategy and highly efficient computation-communication overlap techniques for MoE and lightning attention. This approach enables us to conduct efficient training and inference on models with hundreds of billions of parameters across contexts spanning millions of tokens. The context window of MiniMax-Text-01 can reach up to 1 million tokens during training and extrapolate to 4 million tokens during inference at an affordable cost. Our vision-language model, MiniMax-VL-01 is built through continued training with 512 billion vision-language tokens. Experiments on both standard and in-house benchmarks show that our models match the performance of state-of-the-art models like GPT-4o and Claude-3.5-Sonnet while offering 20-32 times longer context window. We publicly release MiniMax-01 at https://github.com/MiniMax-AI.
Various Lengths, Constant Speed: Efficient Language Modeling with Lightning Attention
May 27, 2024We present Lightning Attention, the first linear attention implementation that maintains a constant training speed for various sequence lengths under fixed memory consumption. Due to the issue with cumulative summation operations (cumsum), previous linear attention implementations cannot achieve their theoretical advantage in a casual setting. However, this issue can be effectively solved by utilizing different attention calculation strategies to compute the different parts of attention. Specifically, we split the attention calculation into intra-blocks and inter-blocks and use conventional attention computation for intra-blocks and linear attention kernel tricks for inter-blocks. This eliminates the need for cumsum in the linear attention calculation. Furthermore, a tiling technique is adopted through both forward and backward procedures to take full advantage of the GPU hardware. To enhance accuracy while preserving efficacy, we introduce TransNormerLLM (TNL), a new architecture that is tailored to our lightning attention. We conduct rigorous testing on standard and self-collected datasets with varying model sizes and sequence lengths. TNL is notably more efficient than other language models. In addition, benchmark results indicate that TNL performs on par with state-of-the-art LLMs utilizing conventional transformer structures. The source code is released at github.com/OpenNLPLab/TransnormerLLM.
LAM3D: Large Image-Point-Cloud Alignment Model for 3D Reconstruction from Single Image
May 24, 2024
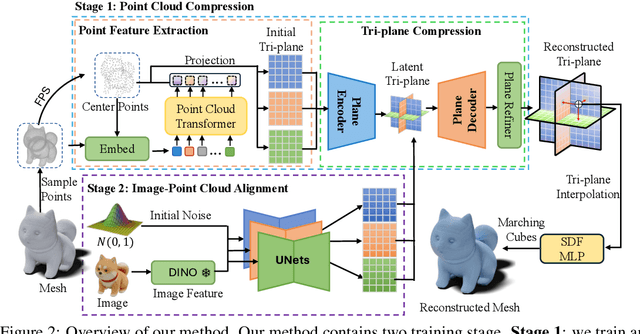

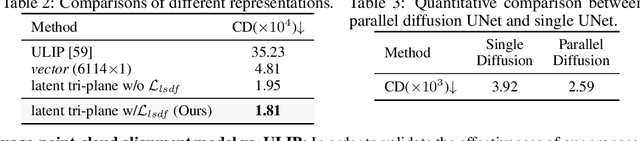
Large Reconstruction Models have made significant strides in the realm of automated 3D content generation from single or multiple input images. Despite their success, these models often produce 3D meshes with geometric inaccuracies, stemming from the inherent challenges of deducing 3D shapes solely from image data. In this work, we introduce a novel framework, the Large Image and Point Cloud Alignment Model (LAM3D), which utilizes 3D point cloud data to enhance the fidelity of generated 3D meshes. Our methodology begins with the development of a point-cloud-based network that effectively generates precise and meaningful latent tri-planes, laying the groundwork for accurate 3D mesh reconstruction. Building upon this, our Image-Point-Cloud Feature Alignment technique processes a single input image, aligning to the latent tri-planes to imbue image features with robust 3D information. This process not only enriches the image features but also facilitates the production of high-fidelity 3D meshes without the need for multi-view input, significantly reducing geometric distortions. Our approach achieves state-of-the-art high-fidelity 3D mesh reconstruction from a single image in just 6 seconds, and experiments on various datasets demonstrate its effectiveness.