 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStemVLA:An Open-Source Vision-Language-Action Model with Future 3D Spatial Geometry Knowledge and 4D Historical Representation
Feb 27, 2026Vision-language-action (VLA) models integrate visual observations and language instructions to predict robot actions, demonstrating promising generalization in manipulation tasks. However, most existing approaches primarily rely on direct mappings from 2D visual inputs to action sequences, without explicitly modeling the underlying 3D spatial structure or temporal world dynamics. Such representations may limit spatial reasoning and long-horizon decision-making in dynamic environments. To address this limitation, we propose StemVLA, a novel framework that explicitly incorporates both future-oriented 3D spatial knowledge and historical 4D spatiotemporal representations into action prediction. First, instead of relying solely on observed images, StemVLA forecasts structured 3D future spatial-geometric world knowledge, enabling the model to anticipate upcoming scene geometry and object configurations. Second, to capture temporal consistency and motion dynamics, we feed historical image frames into a pretrained video-geometry transformer backbone to extract implicit 3D world representations, and further aggregate them across time using a temporal attention module, termed VideoFormer [20], forming a unified 4D historical spatiotemporal representation. By jointly modeling 2D observations, predicted 3D future structure, and aggregated 4D temporal dynamics, StemVLA enables more comprehensive world understanding for robot manipulation. Extensive experiments in simulation demonstrate that StemVLA significantly improves long-horizon task success and achieves state-of-the-art performance on the CALVIN ABC-D benchmark [46], achieving an average sequence length of XXX.
Joint Shadow Generation and Relighting via Light-Geometry Interaction Maps
Feb 25, 2026We propose Light-Geometry Interaction (LGI) maps, a novel representation that encodes light-aware occlusion from monocular depth. Unlike ray tracing, which requires full 3D reconstruction, LGI captures essential light-shadow interactions reliably and accurately, computed from off-the-shelf 2.5D depth map predictions. LGI explicitly ties illumination direction to geometry, providing a physics-inspired prior that constrains generative models. Without such prior, these models often produce floating shadows, inconsistent illumination, and implausible shadow geometry. Building on this representation, we propose a unified pipeline for joint shadow generation and relighting - unlike prior methods that treat them as disjoint tasks - capturing the intrinsic coupling of illumination and shadowing essential for modeling indirect effects. By embedding LGI into a bridge-matching generative backbone, we reduce ambiguity and enforce physically consistent light-shadow reasoning. To enable effective training, we curated the first large-scale benchmark dataset for joint shadow and relighting, covering reflections, transparency, and complex interreflections. Experiments show significant gains in realism and consistency across synthetic and real images. LGI thus bridges geometry-inspired rendering with generative modeling, enabling efficient, physically consistent shadow generation and relighting.
CDI3D: Cross-guided Dense-view Interpolation for 3D Reconstruction
Mar 11, 20253D object reconstruction from single-view image is a fundamental task in computer vision with wide-ranging applications. Recent advancements in Large Reconstruction Models (LRMs) have shown great promise in leveraging multi-view images generated by 2D diffusion models to extract 3D content. However, challenges remain as 2D diffusion models often struggle to produce dense images with strong multi-view consistency, and LRMs tend to amplify these inconsistencies during the 3D reconstruction process. Addressing these issues is critical for achieving high-quality and efficient 3D reconstruction. In this paper, we present CDI3D, a feed-forward framework designed for efficient, high-quality image-to-3D generation with view interpolation. To tackle the aforementioned challenges, we propose to integrate 2D diffusion-based view interpolation into the LRM pipeline to enhance the quality and consistency of the generated mesh. Specifically, our approach introduces a Dense View Interpolation (DVI) module, which synthesizes interpolated images between main views generated by the 2D diffusion model, effectively densifying the input views with better multi-view consistency. We also design a tilt camera pose trajectory to capture views with different elevations and perspectives. Subsequently, we employ a tri-plane-based mesh reconstruction strategy to extract robust tokens from these interpolated and original views, enabling the generation of high-quality 3D meshes with superior texture and geometry. Extensive experiments demonstrate that our method significantly outperforms previous state-of-the-art approaches across various benchmarks, producing 3D content with enhanced texture fidelity and geometric accuracy.
Pandora3D: A Comprehensive Framework for High-Quality 3D Shape and Texture Generation
Feb 21, 2025This report presents a comprehensive framework for generating high-quality 3D shapes and textures from diverse input prompts, including single images, multi-view images, and text descriptions. The framework consists of 3D shape generation and texture generation. (1). The 3D shape generation pipeline employs a Variational Autoencoder (VAE) to encode implicit 3D geometries into a latent space and a diffusion network to generate latents conditioned on input prompts, with modifications to enhance model capacity. An alternative Artist-Created Mesh (AM) generation approach is also explored, yielding promising results for simpler geometries. (2). Texture generation involves a multi-stage process starting with frontal images generation followed by multi-view images generation, RGB-to-PBR texture conversion, and high-resolution multi-view texture refinement. A consistency scheduler is plugged into every stage, to enforce pixel-wise consistency among multi-view textures during inference, ensuring seamless integration. The pipeline demonstrates effective handling of diverse input formats, leveraging advanced neural architectures and novel methodologies to produce high-quality 3D content. This report details the system architecture, experimental results, and potential future directions to improve and expand the framework. The source code and pretrained weights are released at: https://github.com/Tencent/Tencent-XR-3DGen.
DoubleDiffusion: Combining Heat Diffusion with Denoising Diffusion for Generative Learning on 3D Meshes
Jan 06, 2025

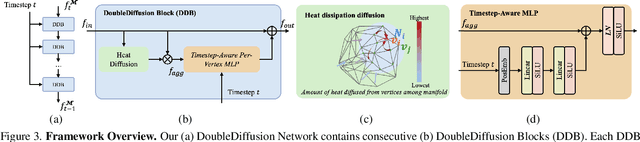

This paper proposes DoubleDiffusion, a novel framework that combines heat dissipation diffusion and denoising diffusion for direct generative learning on 3D mesh surfaces. Our approach addresses the challenges of generating continuous signal distributions residing on a curve manifold surface. Unlike previous methods that rely on unrolling 3D meshes into 2D or adopting field representations, DoubleDiffusion leverages the Laplacian-Beltrami operator to process features respecting the mesh structure. This combination enables effective geometry-aware signal diffusion across the underlying geometry. As shown in Fig.~\ref{fig:teaser}, we demonstrate that DoubleDiffusion has the ability to generate RGB signal distributions on complex 3D mesh surfaces and achieves per-category shape-conditioned texture generation across different shape geometry. Our work contributes a new direction in diffusion-based generative modeling on 3D surfaces, with potential applications in the field of 3D asset generation.
ConsistNet: Enforcing 3D Consistency for Multi-view Images Diffusion
Oct 16, 2023Given a single image of a 3D object, this paper proposes a novel method (named ConsistNet) that is able to generate multiple images of the same object, as if seen they are captured from different viewpoints, while the 3D (multi-view) consistencies among those multiple generated images are effectively exploited. Central to our method is a multi-view consistency block which enables information exchange across multiple single-view diffusion processes based on the underlying multi-view geometry principles. ConsistNet is an extension to the standard latent diffusion model, and consists of two sub-modules: (a) a view aggregation module that unprojects multi-view features into global 3D volumes and infer consistency, and (b) a ray aggregation module that samples and aggregate 3D consistent features back to each view to enforce consistency. Our approach departs from previous methods in multi-view image generation, in that it can be easily dropped-in pre-trained LDMs without requiring explicit pixel correspondences or depth prediction. Experiments show that our method effectively learns 3D consistency over a frozen Zero123 backbone and can generate 16 surrounding views of the object within 40 seconds on a single A100 GPU. Our code will be made available on https://github.com/JiayuYANG/ConsistNet
Stereo Matching in Time: 100+ FPS Video Stereo Matching for Extended Reality
Sep 08, 2023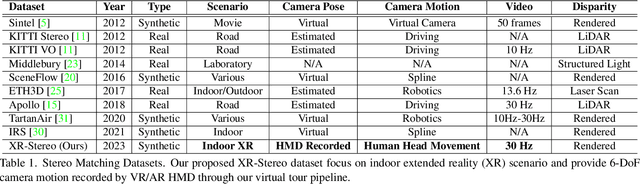
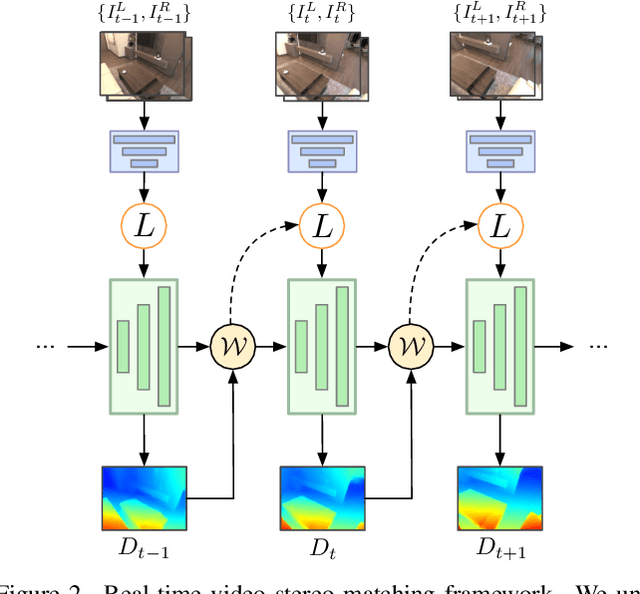
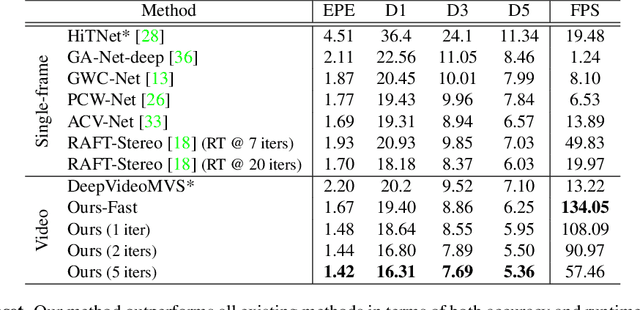
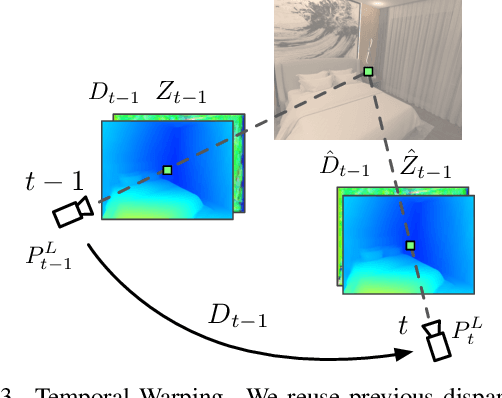
Real-time Stereo Matching is a cornerstone algorithm for many Extended Reality (XR) applications, such as indoor 3D understanding, video pass-through, and mixed-reality games. Despite significant advancements in deep stereo methods, achieving real-time depth inference with high accuracy on a low-power device remains a major challenge. One of the major difficulties is the lack of high-quality indoor video stereo training datasets captured by head-mounted VR/AR glasses. To address this issue, we introduce a novel video stereo synthetic dataset that comprises photorealistic renderings of various indoor scenes and realistic camera motion captured by a 6-DoF moving VR/AR head-mounted display (HMD). This facilitates the evaluation of existing approaches and promotes further research on indoor augmented reality scenarios. Our newly proposed dataset enables us to develop a novel framework for continuous video-rate stereo matching. As another contribution, our dataset enables us to proposed a new video-based stereo matching approach tailored for XR applications, which achieves real-time inference at an impressive 134fps on a standard desktop computer, or 30fps on a battery-powered HMD. Our key insight is that disparity and contextual information are highly correlated and redundant between consecutive stereo frames. By unrolling an iterative cost aggregation in time (i.e. in the temporal dimension), we are able to distribute and reuse the aggregated features over time. This approach leads to a substantial reduction in computation without sacrificing accuracy. We conducted extensive evaluations and comparisons and demonstrated that our method achieves superior performance compared to the current state-of-the-art, making it a strong contender for real-time stereo matching in VR/AR applications.
WildLight: In-the-wild Inverse Rendering with a Flashlight
Mar 24, 2023
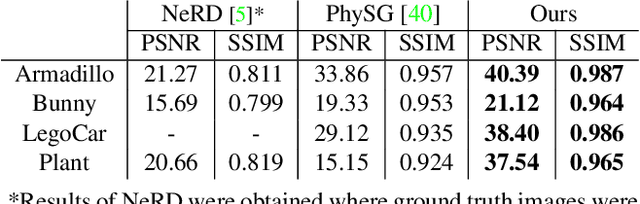

This paper proposes a practical photometric solution for the challenging problem of in-the-wild inverse rendering under unknown ambient lighting. Our system recovers scene geometry and reflectance using only multi-view images captured by a smartphone. The key idea is to exploit smartphone's built-in flashlight as a minimally controlled light source, and decompose image intensities into two photometric components -- a static appearance corresponds to ambient flux, plus a dynamic reflection induced by the moving flashlight. Our method does not require flash/non-flash images to be captured in pairs. Building on the success of neural light fields, we use an off-the-shelf method to capture the ambient reflections, while the flashlight component enables physically accurate photometric constraints to decouple reflectance and illumination. Compared to existing inverse rendering methods, our setup is applicable to non-darkroom environments yet sidesteps the inherent difficulties of explicit solving ambient reflections. We demonstrate by extensive experiments that our method is easy to implement, casual to set up, and consistently outperforms existing in-the-wild inverse rendering techniques. Finally, our neural reconstruction can be easily exported to PBR textured triangle mesh ready for industrial renderers.
Unsupervised Video Interpolation by Learning Multilayered 2.5D Motion Fields
Apr 21, 2022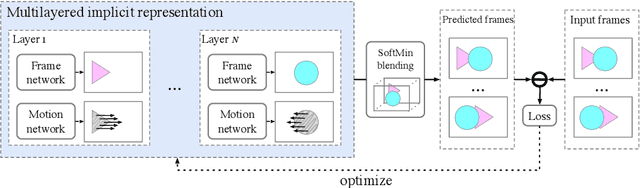
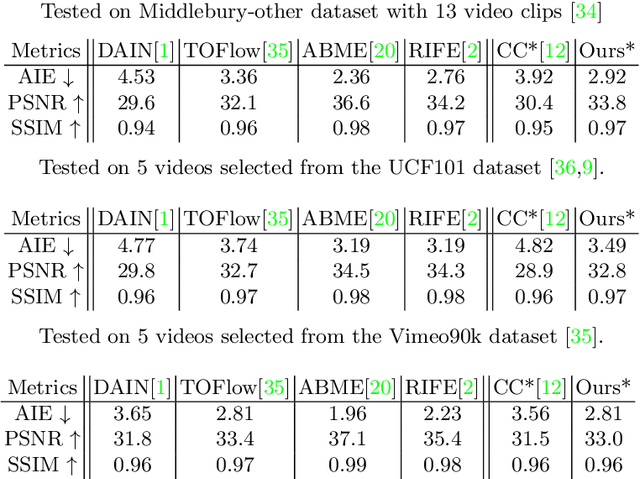
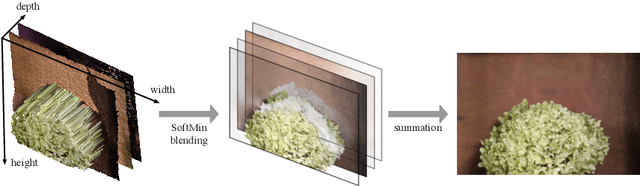

The problem of video frame interpolation is to increase the temporal resolution of a low frame-rate video, by interpolating novel frames between existing temporally sparse frames. This paper presents a self-supervised approach to video frame interpolation that requires only a single video. We pose the video as a set of layers. Each layer is parameterized by two implicit neural networks -- one for learning a static frame and the other for a time-varying motion field corresponding to video dynamics. Together they represent an occlusion-free subset of the scene with a pseudo-depth channel. To model inter-layer occlusions, all layers are lifted to the 2.5D space so that the frontal layer occludes distant layers. This is done by assigning each layer a depth channel, which we call `pseudo-depth', whose partial order defines the occlusion between layers. The pseudo-depths are converted to visibility values through a fully differentiable SoftMin function so that closer layers are more visible than layers in a distance. On the other hand, we parameterize the video motions by solving an ordinary differentiable equation (ODE) defined on a time-varying neural velocity field that guarantees valid motions. This implicit neural representation learns the video as a space-time continuum, allowing frame interpolation at any temporal resolution. We demonstrate the effectiveness of our method on real-world datasets, where our method achieves comparable performance to state-of-the-arts that require ground truth labels for training.
Multi-view 3D Reconstruction of a Texture-less Smooth Surface of Unknown Generic Reflectance
May 25, 2021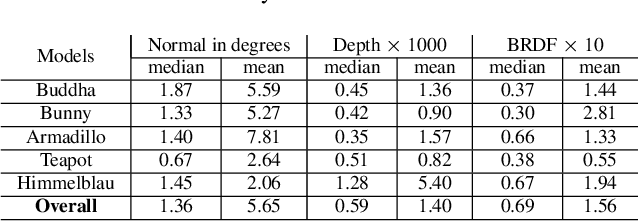

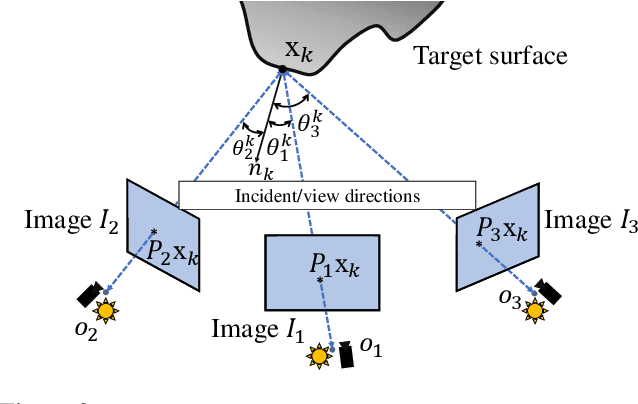
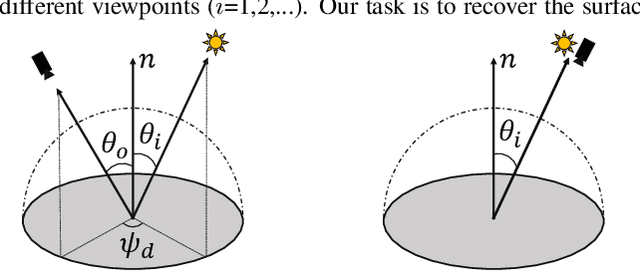
Recovering the 3D geometry of a purely texture-less object with generally unknown surface reflectance (e.g. non-Lambertian) is regarded as a challenging task in multi-view reconstruction. The major obstacle revolves around establishing cross-view correspondences where photometric constancy is violated. This paper proposes a simple and practical solution to overcome this challenge based on a co-located camera-light scanner device. Unlike existing solutions, we do not explicitly solve for correspondence. Instead, we argue the problem is generally well-posed by multi-view geometrical and photometric constraints, and can be solved from a small number of input views. We formulate the reconstruction task as a joint energy minimization over the surface geometry and reflectance. Despite this energy is highly non-convex, we develop an optimization algorithm that robustly recovers globally optimal shape and reflectance even from a random initialization. Extensive experiments on both simulated and real data have validated our method, and possible future extensions are discussed.