 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Kung Fu Athlete Bot That Can Do It All Day: Highly Dynamic, Balance-Challenging Motion Dataset and Autonomous Fall-Resilient Tracking
Feb 14, 2026Current humanoid motion tracking systems can execute routine and moderately dynamic behaviors, yet significant gaps remain near hardware performance limits and algorithmic robustness boundaries. Martial arts represent an extreme case of highly dynamic human motion, characterized by rapid center-of-mass shifts, complex coordination, and abrupt posture transitions. However, datasets tailored to such high-intensity scenarios remain scarce. To address this gap, we construct KungFuAthlete, a high-dynamic martial arts motion dataset derived from professional athletes' daily training videos. The dataset includes ground and jump subsets covering representative complex motion patterns. The jump subset exhibits substantially higher joint, linear, and angular velocities compared to commonly used datasets such as LAFAN1, PHUMA, and AMASS, indicating significantly increased motion intensity and complexity. Importantly, even professional athletes may fail during highly dynamic movements. Similarly, humanoid robots are prone to instability and falls under external disturbances or execution errors. Most prior work assumes motion execution remains within safe states and lacks a unified strategy for modeling unsafe states and enabling reliable autonomous recovery. We propose a novel training paradigm that enables a single policy to jointly learn high-dynamic motion tracking and fall recovery, unifying agile execution and stabilization within one framework. This framework expands robotic capability from pure motion tracking to recovery-enabled execution, promoting more robust and autonomous humanoid performance in real-world high-dynamic scenarios.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
CoCAViT: Compact Vision Transformer with Robust Global Coordination
Aug 07, 2025In recent years, large-scale visual backbones have demonstrated remarkable capabilities in learning general-purpose features from images via extensive pre-training. Concurrently, many efficient architectures have emerged that have performance comparable to that of larger models on in-domain benchmarks. However, we observe that for smaller models, the performance drop on out-of-distribution (OOD) data is disproportionately larger, indicating a deficiency in the generalization performance of existing efficient models. To address this, we identify key architectural bottlenecks and inappropriate design choices that contribute to this issue, retaining robustness for smaller models. To restore the global field of pure window attention, we further introduce a Coordinator-patch Cross Attention (CoCA) mechanism, featuring dynamic, domain-aware global tokens that enhance local-global feature modeling and adaptively capture robust patterns across domains with minimal computational overhead. Integrating these advancements, we present CoCAViT, a novel visual backbone designed for robust real-time visual representation. Extensive experiments empirically validate our design. At a resolution of 224*224, CoCAViT-28M achieves 84.0% top-1 accuracy on ImageNet-1K, with significant gains on multiple OOD benchmarks, compared to competing models. It also attains 52.2 mAP on COCO object detection and 51.3 mIOU on ADE20K semantic segmentation, while maintaining low latency.
Formation Maneuver Control Based on the Augmented Laplacian Method
May 09, 2025This paper proposes a novel formation maneuver control method for both 2-D and 3-D space, which enables the formation to translate, scale, and rotate with arbitrary orientation. The core innovation is the novel design of weights in the proposed augmented Laplacian matrix. Instead of using scalars, we represent weights as matrices, which are designed based on a specified rotation axis and allow the formation to perform rotation in 3-D space. To further improve the flexibility and scalability of the formation, the rotational axis adjustment approach and dynamic agent reconfiguration method are developed, allowing formations to rotate around arbitrary axes in 3-D space and new agents to join the formation. Theoretical analysis is provided to show that the proposed approach preserves the original configuration of the formation. The proposed method maintains the advantages of the complex Laplacian-based method, including reduced neighbor requirements and no reliance on generic or convex nominal configurations, while achieving arbitrary orientation rotations via a more simplified implementation. Simulations in both 2-D and 3-D space validate the effectiveness of the proposed method.
Reliable Disentanglement Multi-view Learning Against View Adversarial Attacks
May 07, 2025Recently, trustworthy multi-view learning has attracted extensive attention because evidence learning can provide reliable uncertainty estimation to enhance the credibility of multi-view predictions. Existing trusted multi-view learning methods implicitly assume that multi-view data is secure. In practice, however, in safety-sensitive applications such as autonomous driving and security monitoring, multi-view data often faces threats from adversarial perturbations, thereby deceiving or disrupting multi-view learning models. This inevitably leads to the adversarial unreliability problem (AUP) in trusted multi-view learning. To overcome this tricky problem, we propose a novel multi-view learning framework, namely Reliable Disentanglement Multi-view Learning (RDML). Specifically, we first propose evidential disentanglement learning to decompose each view into clean and adversarial parts under the guidance of corresponding evidences, which is extracted by a pretrained evidence extractor. Then, we employ the feature recalibration module to mitigate the negative impact of adversarial perturbations and extract potential informative features from them. Finally, to further ignore the irreparable adversarial interferences, a view-level evidential attention mechanism is designed. Extensive experiments on multi-view classification tasks with adversarial attacks show that our RDML outperforms the state-of-the-art multi-view learning methods by a relatively large margin.
Leveraging Large Self-Supervised Time-Series Models for Transferable Diagnosis in Cross-Aircraft Type Bleed Air System
Apr 12, 2025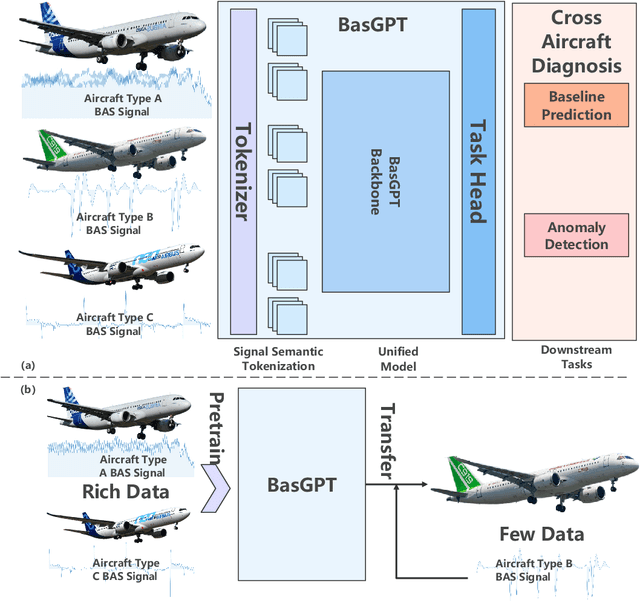

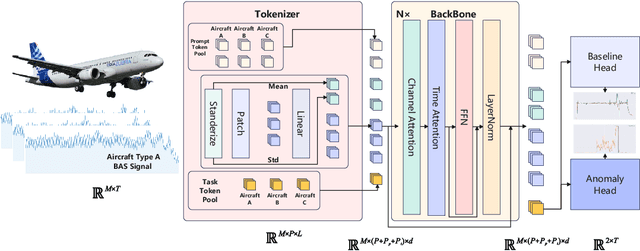

Bleed Air System (BAS) is critical for maintaining flight safety and operational efficiency, supporting functions such as cabin pressurization, air conditioning, and engine anti-icing. However, BAS malfunctions, including overpressure, low pressure, and overheating, pose significant risks such as cabin depressurization, equipment failure, or engine damage. Current diagnostic approaches face notable limitations when applied across different aircraft types, particularly for newer models that lack sufficient operational data. To address these challenges, this paper presents a self-supervised learning-based foundation model that enables the transfer of diagnostic knowledge from mature aircraft (e.g., A320, A330) to newer ones (e.g., C919). Leveraging self-supervised pretraining, the model learns universal feature representations from flight signals without requiring labeled data, making it effective in data-scarce scenarios. This model enhances both anomaly detection and baseline signal prediction, thereby improving system reliability. The paper introduces a cross-model dataset, a self-supervised learning framework for BAS diagnostics, and a novel Joint Baseline and Anomaly Detection Loss Function tailored to real-world flight data. These innovations facilitate efficient transfer of diagnostic knowledge across aircraft types, ensuring robust support for early operational stages of new models. Additionally, the paper explores the relationship between model capacity and transferability, providing a foundation for future research on large-scale flight signal models.
DoubleDiffusion: Combining Heat Diffusion with Denoising Diffusion for Generative Learning on 3D Meshes
Jan 06, 2025

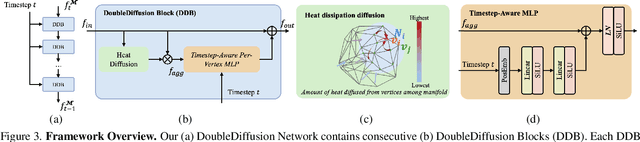

This paper proposes DoubleDiffusion, a novel framework that combines heat dissipation diffusion and denoising diffusion for direct generative learning on 3D mesh surfaces. Our approach addresses the challenges of generating continuous signal distributions residing on a curve manifold surface. Unlike previous methods that rely on unrolling 3D meshes into 2D or adopting field representations, DoubleDiffusion leverages the Laplacian-Beltrami operator to process features respecting the mesh structure. This combination enables effective geometry-aware signal diffusion across the underlying geometry. As shown in Fig.~\ref{fig:teaser}, we demonstrate that DoubleDiffusion has the ability to generate RGB signal distributions on complex 3D mesh surfaces and achieves per-category shape-conditioned texture generation across different shape geometry. Our work contributes a new direction in diffusion-based generative modeling on 3D surfaces, with potential applications in the field of 3D asset generation.
Automatic Text Pronunciation Correlation Generation and Application for Contextual Biasing
Jan 01, 2025



Effectively distinguishing the pronunciation correlations between different written texts is a significant issue in linguistic acoustics. Traditionally, such pronunciation correlations are obtained through manually designed pronunciation lexicons. In this paper, we propose a data-driven method to automatically acquire these pronunciation correlations, called automatic text pronunciation correlation (ATPC). The supervision required for this method is consistent with the supervision needed for training end-to-end automatic speech recognition (E2E-ASR) systems, i.e., speech and corresponding text annotations. First, the iteratively-trained timestamp estimator (ITSE) algorithm is employed to align the speech with their corresponding annotated text symbols. Then, a speech encoder is used to convert the speech into speech embeddings. Finally, we compare the speech embeddings distances of different text symbols to obtain ATPC. Experimental results on Mandarin show that ATPC enhances E2E-ASR performance in contextual biasing and holds promise for dialects or languages lacking artificial pronunciation lexicons.
Relative Entropy-Based Waveform Optimization for Rician Target Detection with Dual-Function Radar Communication Systems
Apr 05, 2023In this paper, we consider waveform design for dualfunction radar-communication systems based on multiple-inputmultiple-out arrays. To achieve better Rician target detection performance, we use the relative entropy associated with the formulated detection problem as the design metric. We also impose a multiuser interference energy constraint on the waveforms to ensure the achievable sum-rate of the communications. Two algorithms are presented to tackle the nonlinear non-convex waveform design problem. In the first algorithm, we derive a quadratic function to minorize the objective function. To tackle the quadratically constrained quadratic programming problem at each iteration, a semidefinite relaxation approach followed by a rank-one decomposition procedure and an efficient alternating direction method of multipliers (ADMM) are proposed, respectively. In the second algorithm, we present a novel ADMM algorithm to tackle the optimization problem and employ an efficient minorization-maximization approach in the inner loop of the ADMM algorithm. Numerical results demonstrate the superiority of both algorithms. Moreover, the presented algorithms can be extended to synthesize peak-to-average-power ratio constrained waveforms, which allows the radio frequency amplifier to operate at an increased efficiency.
Co-Design for Spectral Coexistence between RIS-aided MIMO Radar and MIMO Communication Systems
Apr 04, 2023Reconfigurable intelligent surface (RIS) refers to a signal reflection surface containing a large number of low-cost passive reflecting elements. RIS can improve the performance of radar and communication systems by dynamically modulating the wireless channels. In this paper, we consider the co-design for improving the co-existence between multiple-input-multiple-output (MIMO) radar and MIMO communication system with the aid of RIS.The design purpose is to improve the radar detection performance and guarantee the communication capability. Due to the unimodular constraint on the RIS coefficients and the constant-envelope constraint on the radar transmit waveforms, the associated optimization problem is non-convex.To tackle this problem, we develop a cyclic method based on minorization-maximization, semi-definite programming, and alternating direction method of multipliers. Numerical examples verify the effectiveness of the proposed algorithm.